







引言
youtube观看链接:youtube列表
bilibili观看链接:斯坦福CS224n
本讲主要简述以下7个方面:
- Word meaning
- Word2vec introduction
- Research highlight:前沿研究
- Word2vec objective function gradients:目标函数的梯度
- Optimization refresher
- Assignment 1 notes
- Usefulness of word2vec
1. Word meaning
计算机中是如何获取单词可用的词义的呢?
在过去很长的时间里,一直通过分类词典来处理词义。对于英文来说,通常的方法是使用WordNet。它根据单词层次关系和同义词关系构成单词网络。著名自然语言处理库NLTK中就包含了WordNet,下面是使用WordNet的两个例子:

左边的例子是获取单词“good”各个词义的近义词,右边例子是获取单词“panda”的上位词(is a的关系,例如”熊猫“是”动物“,”熊猫“是”哺乳动物“)。
从symbolic representations到distributed representations
然而WordNet存在着一些缺陷,例如无法反映出同义词的一些细微差别;词汇的含义存在一定的主观倾向;需要大量人力来维护;难以量化单词的相似度等。
此前,无论是规则学派,还是统计学派,绝大多数NLP work都将词语作为最小单位。这相当于将词语离散化表示,即「one-hot」表示,例如我们有一个一共有5个单词的词汇表,其中单词“hotel”和“motel”分别是第2、第4个,那么它们可以用如下向量表示:
h
o
t
e
l
=
[
0
,
1
,
0
,
0
,
0
]
hotel = [0,1,0,0,0]
hotel=[0,1,0,0,0]
m
o
t
e
l
=
[
0
,
0
,
0
,
1
,
0
]
motel = [0,0,0,1,0]
motel=[0,0,0,1,0]
在不同的语料中,词表大小不同。Google的1TB语料词汇量是1300万,这个向量的确太长了。
one-hot 形式虽然简单,但是也存在许多问题,比如:
- 维度灾难,这样稀疏的向量,存储和训练都会造成巨大的开销。
- 每个向量都是正交的(点积为0),欧式距离也都相等,无法直接衡量每个单词的相似度。例如motel 与 hotel 应有一定的相似性。
通过上下文来表征词义
针对上面的相似度的问题,实际上后面有人想到了使用「构建词语相似度表」(word-similarity table)的方式来解决,这样首先需要人工得确定每两个词的相似性程度,这显然是不可能完成的任务,那通过WordNet来获取相似度呢?这样可以小范围的实现,但是明显WordNet是很不完整的。
于是人们想根据单词的特性(比如一起出现的上下文)来构造稠密(dense)的向量来表示单词,使其具有表征词义的能力。

最后得到的向量与下图类似。这种表示单词的方法称作词向量(Word Vectors),也称做词嵌入(Word Embeddings)或词表示(Word Representations)。这样的词向量既可以较为容易地得到,也可以利用余弦相似度等方法计算单词的相似度。

2. Word2vec introduction
学习神经网络word embeddings的基本思路
定义一个以预测某个单词的上下文的模型:
p
(
c
o
n
t
e
x
t
∣
w
t
)
=
…
p(context|w_{t})=…
p(context∣wt)=…
损失函数定义如下:表示准确率是25%,损失则为75%,准确为100%,损失为0
J
=
1
−
p
(
w
−
t
∣
w
t
)
J=1-p(w_{-t}|w_{t})
J=1−p(w−t∣wt)
其中
w
−
t
w_{-t}
w−t表示
w
t
w_{t}
wt的上下文(负号通常表示除了某某之外),如果完美预测,损失函数为零。
然后在一个大型语料库中的不同位置得到训练实例,调整词向量,最小化损失函数。
Then you just pray and depend on the magic of deep learning

word2vec 根据输入输出关系定义了两个重要的模型:
- CBOW:已知上下文预测当前词
- skip-gram:已知当前词预测上下文
两种较为高效的训练方法:
- Hierarchical Softmax
- Negative Sampling
2.1 ship-gram

上图即为skip-gram模型。skip-gram的思路是:每一个步都取一个词作为中心词汇 (center word),接着我们用这个词来预测给定窗口(window)大小内的上下文单词 (context word) 。即通过中心词去预测上下文,给定一个中心词汇,预测某个单词在它上下文中出现的概率。学习的是输入输出词的向量。
对于中心词汇左右两边都有相同的概率分布。
既然每个词
w
t
w_{t}
wt都决定了相邻的词
w
t
+
j
w_{t+j}
wt+j,基于极大似然估计的方法,希望所有样本的条件概率
p
(
w
t
+
j
∣
w
t
)
p(w_{t+j}|w_{t})
p(wt+j∣wt)之积最大。因此word2vec的目标函数定义为所有位置的预测结果的乘积:
J
′
(
θ
)
=
∏
t
=
1
T
∏
−
m
⩽
j
⩽
m
,
j
≠
0
p
(
w
t
+
j
∣
w
t
;
θ
)
J^{'}(\theta)=\prod_{t=1}^{T}\prod_{-m\leqslant j\leqslant m,j\neq 0}p(w_{t+j}|w_{t};\theta )
J′(θ)=t=1∏T−m⩽j⩽m,j=0∏p(wt+j∣wt;θ)
其中的theta也是参数,是词汇的向量表示,也就是每个词汇向量的唯一表示参数。m表示窗口半径。
要最大化目标函数,对其取个负对数,得到损失函数——对数似然函数的相反数,然后对其最小化,机器学习人员喜欢最小化。
J
(
θ
)
=
−
1
T
∑
t
=
1
T
∑
−
m
⩽
j
⩽
m
,
j
≠
0
l
o
g
p
(
w
t
+
j
∣
w
t
)
J(\theta)=-\frac{1}{T}\sum_{t=1}^{T}\sum_{-m\leqslant j\leqslant m,j\neq 0}logp(w_{t+j}|w_{t})
J(θ)=−T1t=1∑T−m⩽j⩽m,j=0∑logp(wt+j∣wt)
图片中上面的目标函数表示的是,假设现在我们有一段很长的文本,其中包含足够的词汇序列和真正的行文(行文,指完整的句子)。接下来,遍历文中的所有位置,对于文本中的每个位置,我们都会定义一个围绕中心词汇的大小为2m的窗口,中心词前后各m个单词。这样就得到一个概率分布,可以根据中心词汇给出其上下文词汇出现的概率。然后我们就设置模型的参数,让上下文中所有词汇出现的概率,都尽可能地高。
2.1.1 word2vec细节
预测到的某个上下文条件概率
p
(
w
t
+
j
∣
w
t
)
p(w_{t+j}|w_{t})
p(wt+j∣wt)可由softmax得到:

c和o分布代表单词在词汇表空间中的索引(我认为这里表述的是在词汇表中的序号),以及它的类型。Uo是索引为o的单词所对应的向量,Vc是中心词汇对应的向量。
softmax 是一种将数值转为概率的标准方法。

这是一种粗糙衡量相似性的方法,两个向量的相似性越大,那么这个点积就越大。一旦我们得出了两个单词向量的点积,我们就把他们转换成softmax形式。softmax形式是一种将数值转换为概率的标准方法。
2.1.2 skip-gram 示意图
每个单词有两个词向量。
skip-gram 模型如下图所示:

- 现在有一个中心词汇 w t w_{t} wt,它是 one-hot 向量
- W W W 是包含所有中心词汇表示的向量矩阵
- 如果将 one-hot 向量和矩阵相乘,选出矩阵的列,即为中心词汇的表示 W w t W_{w_{t}} Wwt
- 接下来要构造上下文词汇的矩阵 W ′ W^{'} W′ (上下文词汇的个数有很多,仅展示3个)存储上下文词汇的表示。
- 将这个中心词向量 W w t W_{w_{t}} Wwt和上下文词汇表示的矩阵 W ′ W^{'} W′相乘,取 softmax,数值最大的即为上下文词汇。
- 同时与答案对比计算损失。
从图中可以看出,最后一列有没有预测准的,说明产生了误差。
还有一个问题是:词向量是否存在唯一解?如下图所示:

答:是有多个解,每个词有两个词向量表示,但最终会决定一个确切的解,比如让两个词向量相加 / 2
2.3 目标函数的梯度
把所有参数写进向量
θ
\theta
θ,对d维的词向量和大小V的词表来讲,有:

2.3.1 训练模型:计算参数向量的梯度

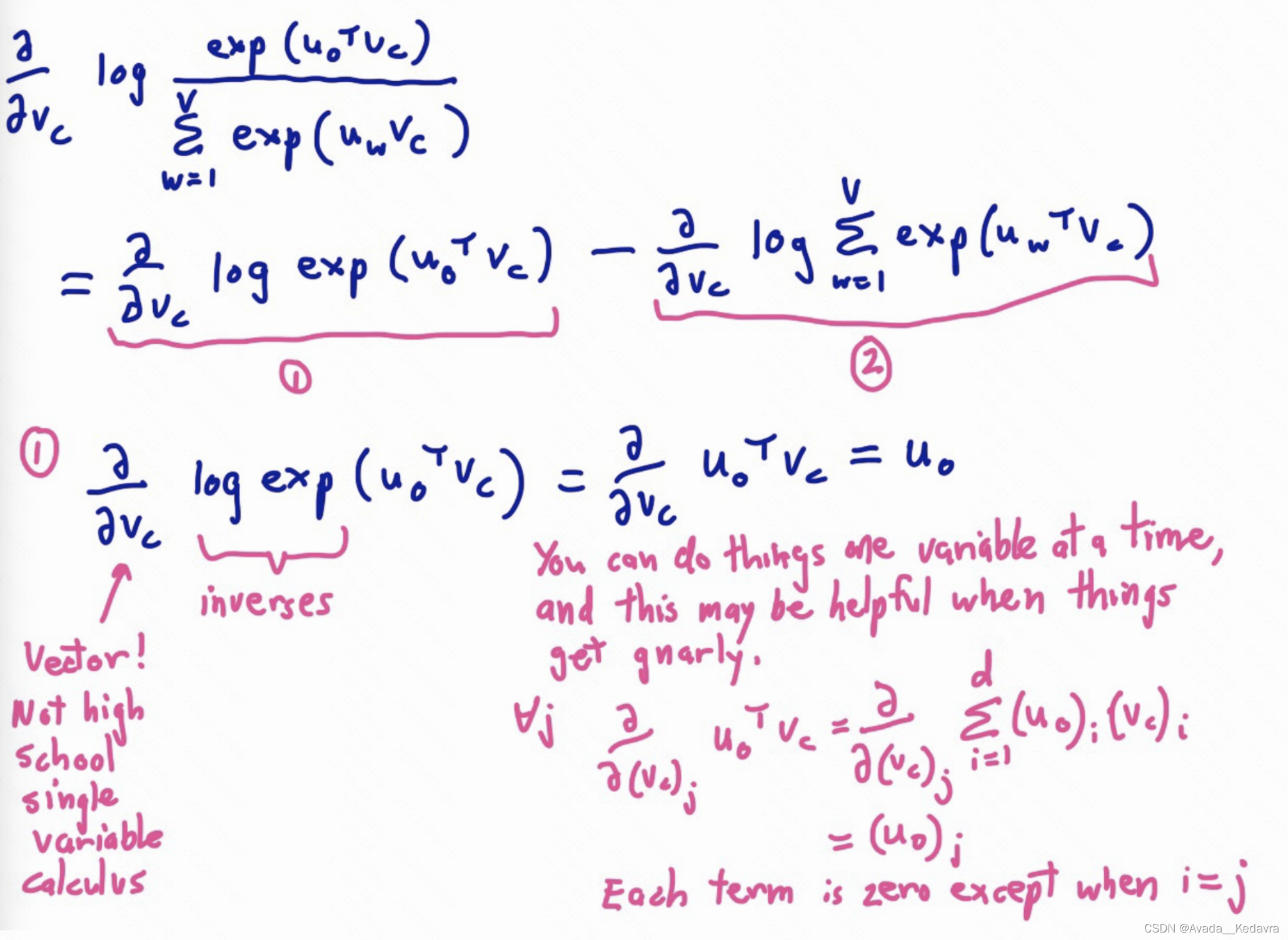
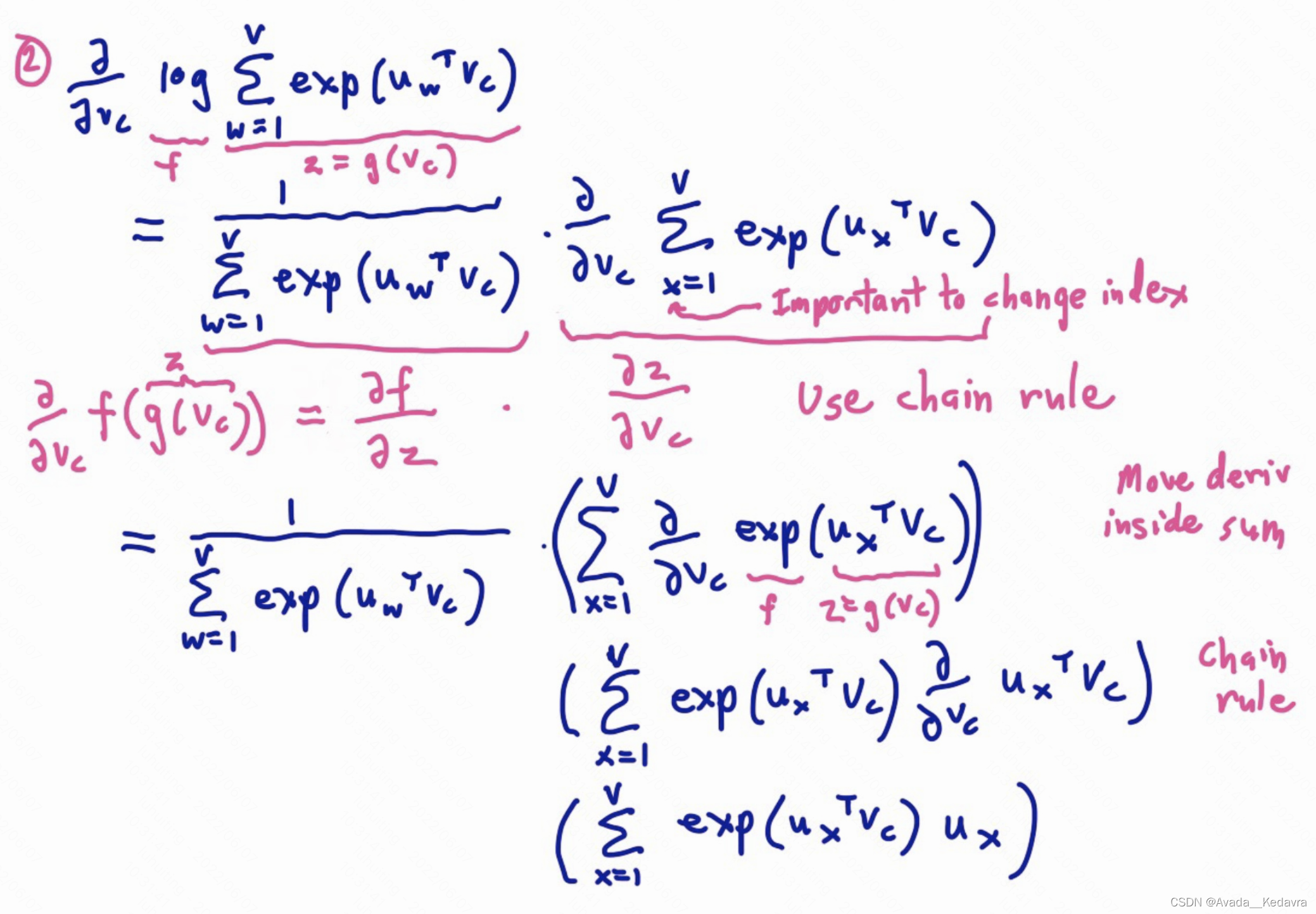

梯度有了,参数减去梯度就能朝着最小值走了。
2.4 目标函数的梯度
下面介绍了梯度下降法:
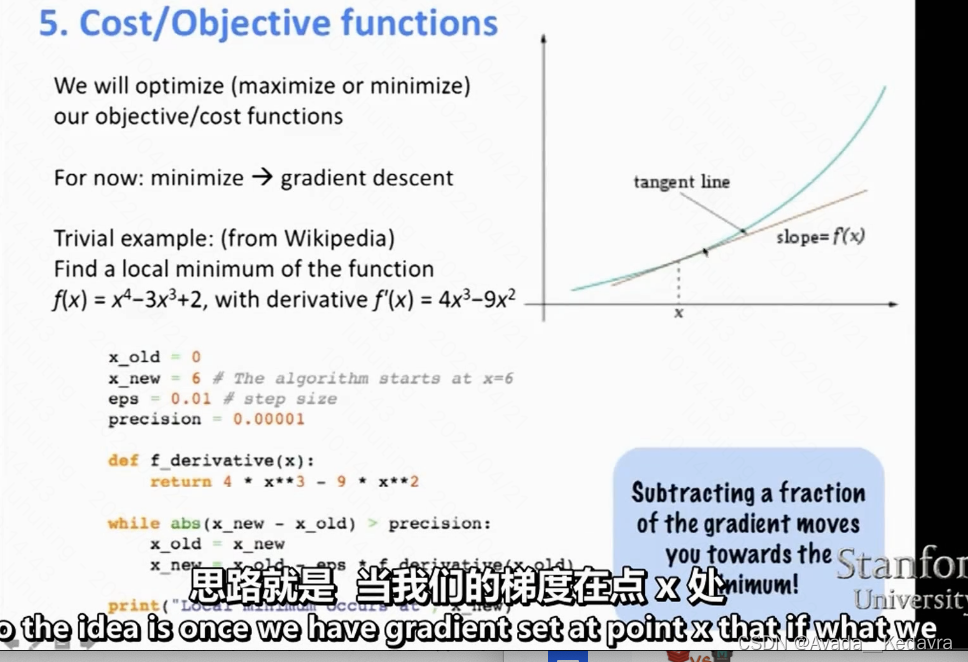

但是实际中,采用了随机梯度下降(????其实我也解释不清楚)。
(???其实我很好奇,在 tensorflow 中是怎么样找梯度的?)
在 skip-gram 里面即为,选取文本中的一个位置。就有了一个中心词汇,以及它周围的词汇,移动一个位置(移动是什么意思),对所有的参数求梯度
——————















 6751
6751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









