






首先描述一下现象
最近对HDFS底层做了许多优化,包括硬件压缩卡,内存盘及SSD。
在出测试报告时发现老问题,HBase写入速度不稳定,这个大家都习以为常了吧,就是压测时,只要row size稍小一点,不管你怎么压,HBase的RegionServer总是不愠不火特淡定。有些人就怀疑是磁盘到瓶颈了?还有些人怀疑是不是GC拖累了?
总之网上大部分测试都是黑盒测试嘛,大家也就乱猜呗。
下面我仔细来分析下原因,并解决掉问题,详细的测试数据在http://blog.csdn.net/kalaamong/article/details/7290192,对数据感兴趣的同学可以直接跳过下面的内容。
大概全套问题都解决之后写入通量提高两到三倍。
在压测时HRegionServer的Handler很多情况下都被卡在reclaimMemStoreMemory()
ps:这个方法在region数目过多时淘宝庄庄说过这个问题,会影响put速度。
因为他每次都会调这一段代码,当有几千上万个region时。。。。。每次put都检查自然有问题,不过这个相对于后面的事情是小问题了,先放这。
-
public long getGlobalMemStoreSize() { -
long total = 0; -
for (HRegion region : onlineRegions.values()) { -
total += region.memstoreSize.get(); -
} -
return total; -
}
下面这段展示了这个方法。
-
public synchronized void reclaimMemStoreMemory() { -
if (isAboveHighWaterMark()) { -
lock.lock(); -
try { -
while (isAboveHighWaterMark() && !server.isStopped()) { -
wakeupFlushThread(); -
try { -
// we should be able to wait forever, but we've seen a bug where -
// we miss a notify, so put a 5 second bound on it at least. -
flushOccurred.await(5, TimeUnit.SECONDS); -
} catch (InterruptedException ie) { -
Thread.currentThread().interrupt(); -
} -
} -
} finally { -
lock.unlock(); -
} -
} else if (isAboveLowWaterMark()) { -
wakeupFlushThread(); -
} -
}
其中flushOccurred.await(5, TimeUnit.SECONDS);这一部分将所有写入线程都block了,但这也不完全怪flush做得慢,我们实际压测时,flush还是很快的,只是compact不及时,flush就会被阻塞。
参这篇jira的内容
https://issues.apache.org/jira/browse/HBASE-2646
https://issues.apache.org/jira/browse/HBASE-2981
https://issues.apache.org/jira/browse/HBASE-2832
run YCSB写入压测时,HBase有明显的停顿,写入性能有跳变。在EMC一篇关于hypertable和HBase的测试中,提到HBase的性能被GC所累,我觉得他们有可能错误地把
flush和compaction中的停顿当作JAVA gc了。因为在给RegionServer分配24GB内存时,GC的时间很短(毫秒级)。
第一步:为flush添加线程池
HBase flush memorystore时是由一个线程顺序将数据
hbase.hstore.blockingStoreFiles ()同时flush时会获取Region writeLock的writeLock().来做snapshot,而所有的修改包括mult,put,delete都要获取readlock,
所以写入操作与flush大部分代码都只能串行执行,并不能像流水号线一样边写入边flush。所以压测时就会一顿一顿的。
当然这是其中一个原因,我们先来解决这个原因,将flush变成多线程并行flush再来探讨另一个导致flush无法并行执行的原因。
https://issues.apache.org/jira/browse/HBASE-2832
于是我仿照Jonathan的patch在90.4上实现了muti thread memstore flush,Jonathan的实现目前用于trunk,且只针对上面我提到的原因做了改进。
实际测试时并不能达到并行flush的效果。
这一段的主要修改是在MemStoreFlusher 中添加了如下代码,同时每处flush都调用performFlush(HRegion)。
FlushRegionHandler的代码比较多,详细见patch,我会贴到git上https://github.com/ICT-Ope,也可以到微博上@我。
ExecutorService executor; public void performFlush(HRegion r) { executor.submit(new FlushRegionHandler(this.server, r,this)); }
第二步:修改HLog 获取sequenceId时的锁类型
这样做之后,遇到阻碍并行flush的第二个问题,HLog。但测试时发现一次flush的region并没有增加,依然没有效果。
我怀疑HLog中每次flush部分的检查可能还是限制了并发。并在regionserver.wal.HLog.startCacheFlush()中的一段代码找出了问题。
PS:即使用户在每次put时设定不写HLog,HLog也是要在每次flush之后检查有效log的位置,并roll log等操作也不会因此关闭。(测试中每次put时设定不写HLog)
在regionserver.wal.HLog中有如下代码:
[java] view plain copy
- <code class="language-java"> /**
- * By acquiring a log sequence ID, we can allow log messages to continue while
- * we flush the cache.
- *
- * Acquire a lock so that we do not roll the log between the start and
- * completion of a cache-flush. Otherwise the log-seq-id for the flush will
- * not appear in the correct logfile.
- *
- * @return sequence ID to pass {@link #completeCacheFlush(byte[], byte[], long, boolean)}
- * (byte[], byte[], long)}
- * @see #completeCacheFlush(byte[], byte[], long, boolean)
- * @see #abortCacheFlush()
- */
- public long startCacheFlush() {
- this.cacheFlushLock.lock();
- return obtainSeqNum();
- }</code>
这部分被HRegion的internalFlushcache调用,用以得到当前HLog的sequenceId,不得不说这个lock加得太大了,一个RegionServer共用一个HLog啊。。。
此处无非是得到log sequence 然后在store internalFlushcache时写到文件里,hlog roll时从而得知哪段已经写到磁盘了。
所以此处的cacheFlushLock 应当改为ReentrantReadWriteLock,并在此处只加readLock。rolllog时加writeLog。
-
this.updatesLock.writeLock().lock();//此处已经将本Region所有修改操作lock了。 -
final long currentMemStoreSize = this.memstoreSize.get(); -
List<StoreFlusher> storeFlushers = new ArrayList<StoreFlusher>(stores.size()); -
boolean compactionRequested = false; -
try { -
sequenceId = (wal == null)? myseqid: wal.startCacheFlush();//在这,上面那个方法又加了个RegionServer级的锁,且还不是RW锁。 -
completeSequenceId = this.getCompleteCacheFlushSequenceId(sequenceId); -
for (Store s : stores.values()) { -
storeFlushers.add(s.getStoreFlusher(completeSequenceId)); -
} -
// prepare flush (take a snapshot) -
for (StoreFlusher flusher : storeFlushers) { -
flusher.prepare(); -
}
做以上修改之后HBase多线程flush没有问题了。下面是第三步:
第三步:为compact添加线程池,顺便注释掉split部分。
不过随之而来的另外一个问题就是当flush频繁之后系统吞吐量显著提高,但生成的小文件数量变多,compaction的负担就大了。
由于下面这段代码,compact忙不过来时,flush也是会被阻塞的,如此写入也就被阻塞了。
-
private boolean flushRegion(final FlushRegionEntry fqe) { -
HRegion region = fqe.region; -
if (!fqe.region.getRegionInfo().isMetaRegion() && -
isTooManyStoreFiles(region)) { -
if (fqe.isMaximumWait(this.blockingWaitTime)) { -
LOG.info("Waited " + (System.currentTimeMillis() - fqe.createTime) + -
"ms on a compaction to clean up 'too many store files'; waited " + -
"long enough... proceeding with flush of " + -
region.getRegionNameAsString()); -
} else {
当StoreFile数到7(默认),flush就要等compact把StoreFile压到一个文件里。如此单线程的compact又成为瓶颈阻碍HBase的写入吞吐量了。所以最后又把compact也改成了线程池,同时顺便把split的代码给注释掉了。然后把blockflush的storefile数目从7改到两千,这样写入流水基本顺畅了。最后的效果是HBase压测时cpu一直利用充分。HBase中 multi flush compact的流水线基本并行化了。整个系统的吞吐量大幅度提升。此时当打开gz软件压缩(no native,用native压时,压缩是单线程的)时,系统的cpu利用率才充分一些。

第四步:为HBaseClient添加到RegoinServer的连接池。
但即使如此,cpu也没有用到100%啊,既然是压测那一定要达到某个硬件瓶颈才算压出效果吧。此时突然意识到HBaseClient端的一个问题:所有线程共用一个socket连接与RS交换数据,so果端修改了HBaseClient的代码使用了连接池。(线上系统如非某应用独占,最好不要改这个地方)。改完之后用70个线程压测时总算达到了我要的效果,RS 16核2.4GHz的CPU满载(no compression,multi-thread flush and compact)。更详细的测试报告我将会在后续的博文中放出,测试的效果大概是写入吞吐量有两到三倍提升。

| CPU | 16* Intel(R) Xeon(R) CPU E5620 @ 2.40GHz |
|---|---|
| MEMORY | 48GB |
| DISK | 12*SATA 2TB |
| NET | 4*1Gb Ethernet |
测试数据:
| 类型 | 国内某视频网站近半年用户访问日志 |
| 结构 | 一行九列,包括用户访问页,关键词及其它用户信息。对应HBase一个family下9个column,一行120到180字节 |
| 数据量 | 每次测试写入10亿条数据,原始数据约110GB,写到HBase中一张不加压缩的表里HDFS中单副本约480GB (dus结果) |
集群结构
| RegionServer | 1个 hostname: data2 |
| DataNode | 5个hostname: data12~data16 |
这样设设计的集群结构,主要目的就是要压测Region Server。以下所有测试客户端put关HLog,服务端不split。
第一组:(原始情况)
这是最初HBase的情况,没有对服务端代码做修改,在配置参数上稍稍改动了类似于MemStore up water level,low water level,以及handler数目和HFile的最大Size值。可以看出虽然是压测,HBase所有地方都很闲,内部的情况是就Multi写入数据了之后MemStore大了等flush,flush的store file多了就等compact。各种等也就各种闲。
最后写入10亿行数据用时6小时48分。整个表在HDFS dus出的大小约440GB。


第二组:(配置项修改)
下面的图是继上面情况之后修改了
<property>
<name>hbase.hstore.blockingStoreFiles</name>
<value>2000</value>
</property>
把block flush的storefile数从默认的7改到了2000,已经不让split了,还不许storefile数多一点,太没人性了。此时前段时间写入的性能有些改善,但毕竟还是单线程的flush和compact治标不治本。
最后写入10亿行数据用时5小时54分,比上一组实验缩短了1个小时。整个表在HDFS dus出的大小约480GB,原因应当是flush被阻塞的次数减少,flush得更频繁了,写入流量也稍增,但没来得及compact的store file更多,所以整个表大了40G( 约9%)。


第三组:(代码修改)
最后来治标治本吧。后面的实验中配置参数与上一组相同,同时服务端修改代码,为flush和compact添加了线程池。并新加入两个配置项:
25 <property>
26 <name>hbase.hstore.flush.thread</name>
27 <value>20</value>
28 </property>
29 <property>
30 <name>hbase.hstore.compaction.thread</name>
31 <value>15</value>
32 </property>
再看压测情况CPU基本满载。唉这才是压测啊!!
如此这般下来写入10亿行数据用时2小时58分,不到第一组一半的时间。表大小约410GB
由于compact做得及时,表大小比第一组小30GB,比第二组小70GB。


第四组:(代码修改加压缩)
接着按第三组的情况加上GZ的软压缩(为什么挑GZ请参第五组测试),这组估计CPU都要冒烟了。
写入10亿行数据耗时3小时5分,比上一组多了7分钟。但表的size为71GB !差不多是上一组的六分之一,尽然压缩到了原数据的17%大小。
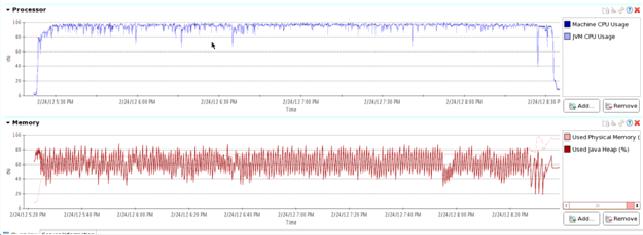
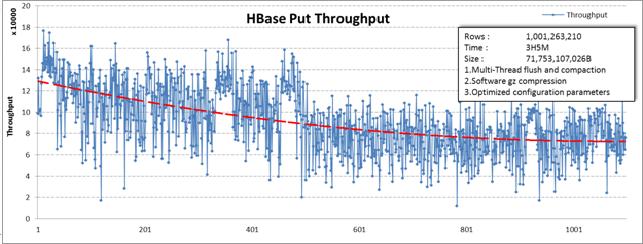
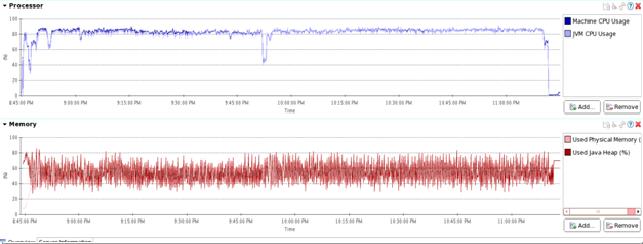
第五组:(第五组大家自己研究吧)
这一组最强悍,采用了一些特殊的硬件改了改HDFS,HBase的修改与上两组相同。
写入10亿行数据耗时2小时24分钟。差不多是第一组时间的1/3。文件size为111GB,压到了第一组的1/4。且CPU也没到冒烟的状态,应当还能加压。关于这个组今后还将有更详细的测试结果放出。现在先不详细介绍了。
















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









