







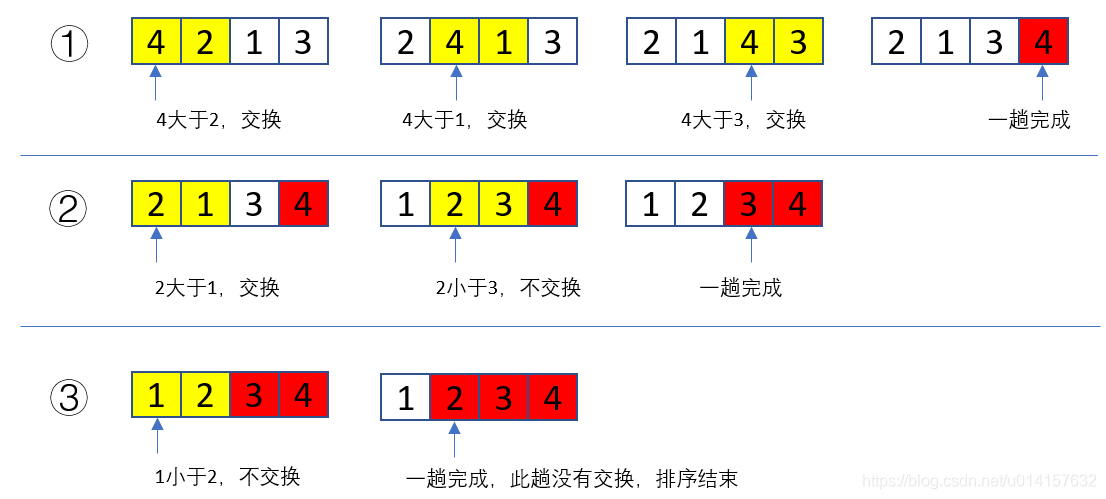
一、冒泡排序
排序过程:
- 列表每两个相邻的数,如果前者大于后者,则交换这两个数;遍历列表,完成一趟排序
- 继续从头遍历,重复上述过程,直到没有发生交换为止
def BubbleSort(a):
if len(a) == 0:
return None
for i in range(len(a) - 1):
exchange = False # 标志位,第i趟如果没有发生交换,则排序已经完成,不需要再进行后面的冒泡
for j in range(len(a) - i - 1):
if a[j] > a[j + 1]:
a[j], a[j + 1] = a[j + 1], a[j]
exchange = True
if exchange is False: # 没有发生交换,返回
return
复杂度分析:
- 最好情况: O ( n ) O(n) O(n)
- 最坏情况: O ( n 2 ) O(n^2) O(n2)
- 平均情况: O ( n 2 ) O(n^2) O(n2)
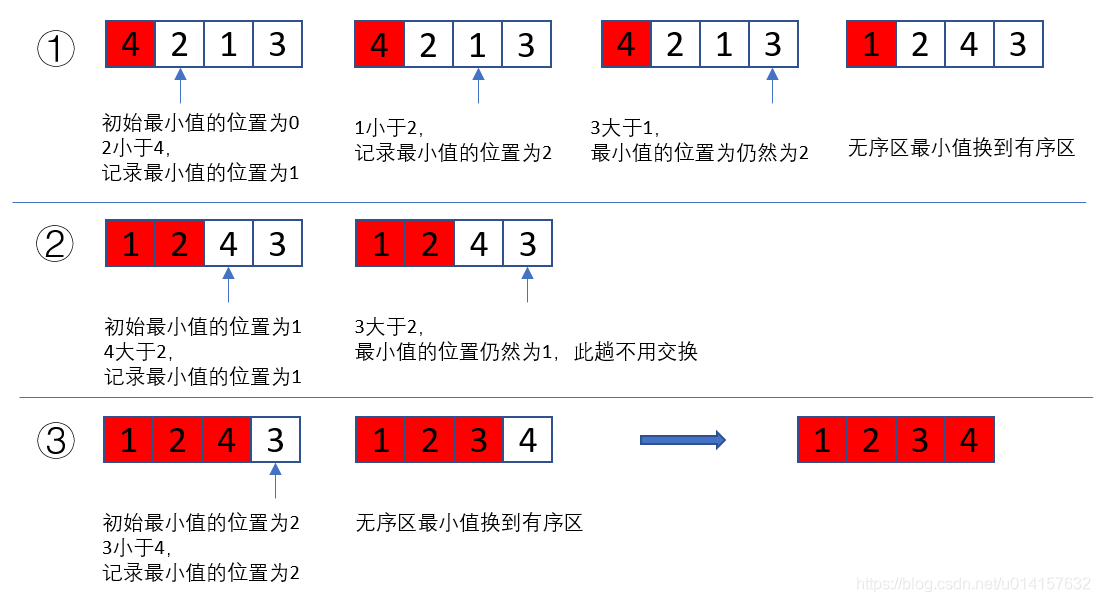
二、选择排序
排序过程:
- 一趟遍历记录最小的数,放到一个位置
- 再遍历一趟,记录无需去最小的数,放到有序区的第二个位置
- 重复以上过程,直到列表结束
def SelectionSort(a):
if len(a) == 0:
return None
for i in range(len(a) - 1):
min_index = i # 记录无序区最小数的位置
for j in range(i, len(a)):
if a[j] < a[min_index]:
min_index = j
if min_index != i:
a[i], a[min_index] = a[min_index], a[i]
复杂度分析:
- 最好情况: O ( n 2 ) O(n^2) O(n2)
- 最坏情况: O ( n 2 ) O(n^2) O(n2)
- 平均情况: O ( n 2 ) O(n^2) O(n2)
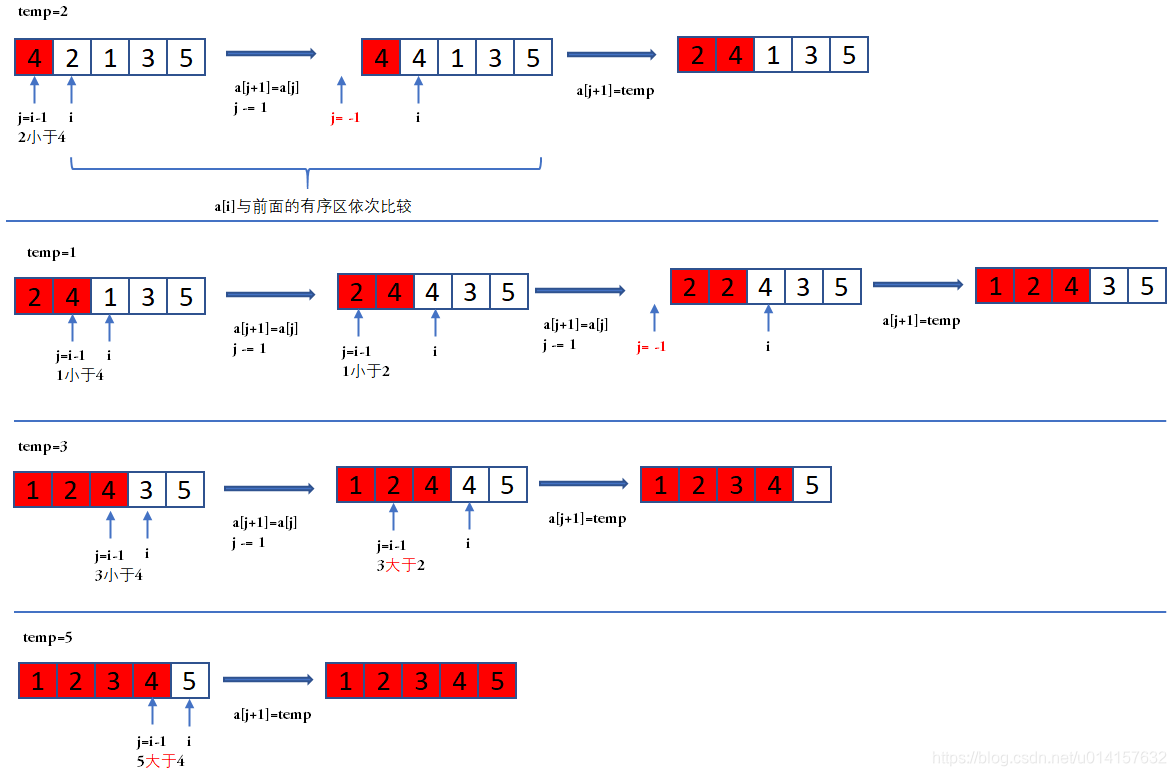
三、插入排序
排序过程:
- 步骤1:从第一个元素 a [ i ] , i = 0 a[i], i=0 a[i],i=0开始,该元素为有序区
- 步骤2:取下一个元素 a [ i + 1 ] a[i+1] a[i+1],在有序区的元素序列中从后向前扫描
- 步骤3:如果有序区元素 a [ j ] a[j] a[j]大于新元素 a [ i + 1 ] a[i+1] a[i+1],将该元素移到下一位置 a [ j − 1 ] a[j-1] a[j−1];
- 步骤4:重复步骤3,直到找到有序区的元素小于或者等于新元素的位置;
- 步骤5:将新元素 a [ i + 1 ] a[i+1] a[i+1]插入到该位置后;
- 步骤6:重复步骤2~5
def InsertionSort(a):
if len(a) == 0:
return None
for i in range(1, len(a)):
temp = a[i] # 取无序区的第一个数
j = i - 1 # 有序区的倒数第一个数索引为i-1
while j >= 0 and temp < a[j]: # 遍历有序区
a[j + 1] = a[j]
j -= 1
a[j + 1] = temp # 找到temp的位置
复杂度分析:
- 最好情况: O ( n ) O(n) O(n)
- 最坏情况: O ( n 2 ) O(n^2) O(n2)
- 平均情况: O ( n 2 ) O(n^2) O(n2)
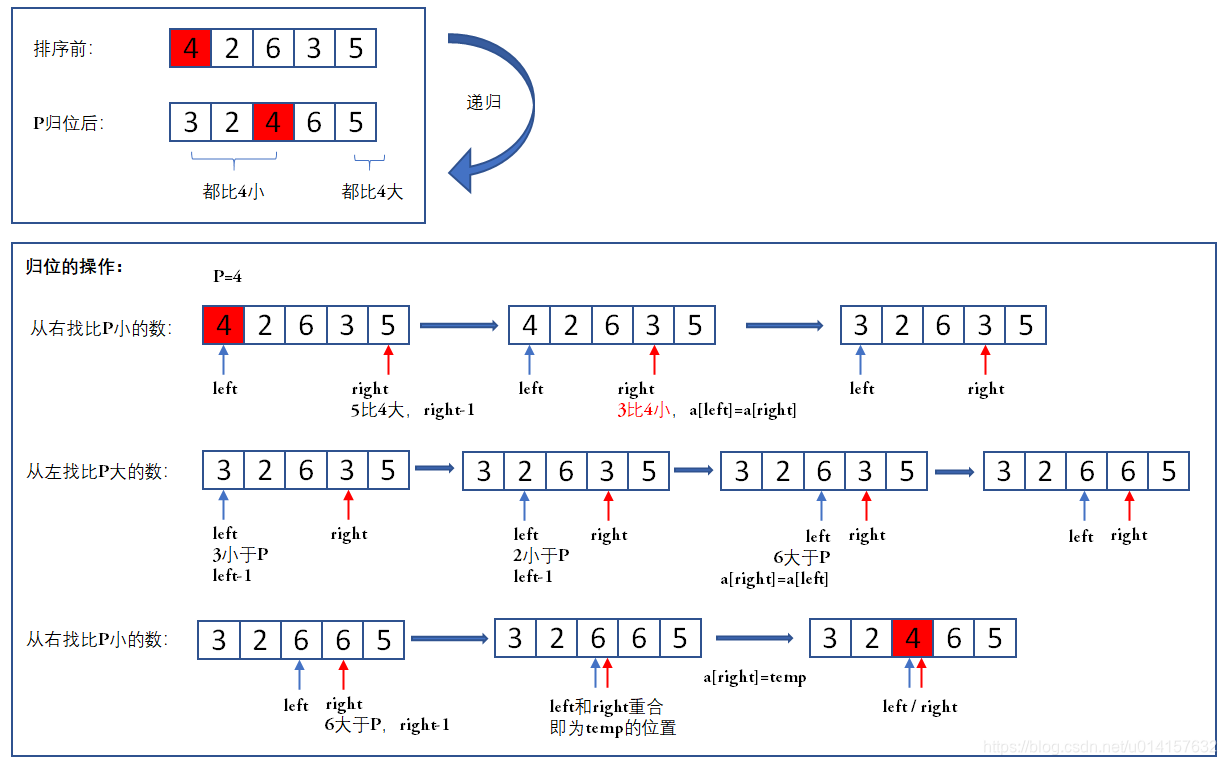
四、快速排序
排序过程:
- 取一个元素(一般为第一个元素)P,使元素归位
- 归位操作后的列表被P分为两部分,P左边的元素都比P小,右边的都比P大
- 递归地把小于P的子数列和大于P的子数列排序
def partition(a, left, right):
if len(a) == 0:
return None
temp = a[left]
while left < right:
# 从右边找比temp小的数
while left < right and a[right] >= temp:
right -= 1
a[left] = a[right]
# 从左边找比temp大的数
while left < right and a[left] <= temp:
left += 1
a[right] = a[left]
# 找到了temp的位置
a[left] = temp
# 返回temp1的位置, return right也可以,因为left和right重合
return left
def QuickSort(a, left, right):
if left < right:
# 选取a的第一个元素P,归位
mid = partition(a, left, right)
# 递归P的左边
QuickSort(a, left, mid - 1)
# 递归P的右边
QuickSort(a, mid + 1, right)
复杂度分析:
- 最佳情况: O ( n log n ) O(n \log n) O(nlogn)
- 最差情况: O ( n 2 ) O(n^2) O(n2)
- 平均情况: O ( n log n ) O(n \log n) O(nlogn)
五、堆排序
堆是一种特殊的完全二叉树。大根堆: 完全二叉树的任一节点都比其孩子节点大。小根堆: 完全二叉树的任一节点都比其孩子节点小。

堆的向下调整: 假设根节点的左右子树都是堆,但根节点不满足堆的性质,可以通过一次向下调整将其变成一个堆。
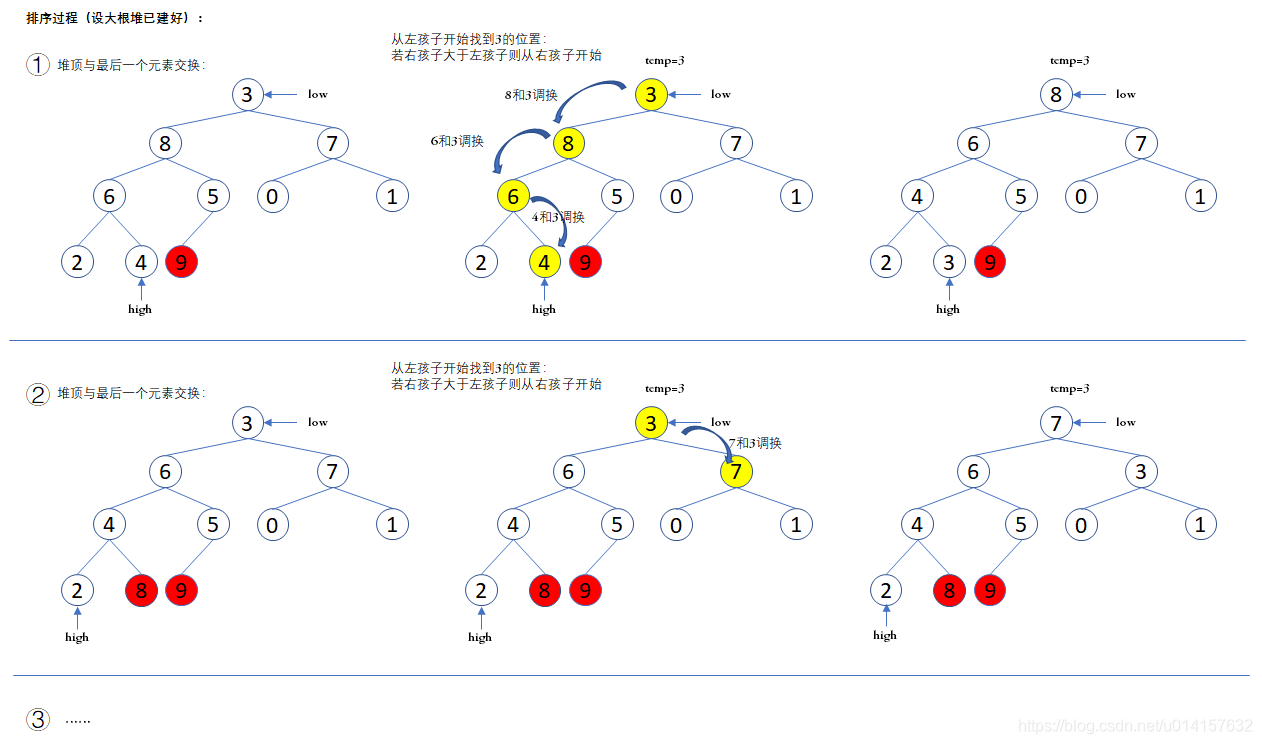
排序过程:
- 步骤1:建立大根堆
- 步骤2:得到对顶元素,为最大元素
- 步骤3:堆顶元素和堆的最后一个元素交换,交换后可以通过一次调整使堆有序(不包括刚才及之前被换到堆后面的元素)
- 步骤4:堆顶元素为第二大元素,重复步骤3,直到堆变空
def adjustHeap(a, low, high):
i = low # 指向根节点
j = 2 * i + 1 # 指向根节点的左孩子
temp = a[i]
while j <= high:
# 如果有右孩子,并且右孩子比左孩子大
if j + 1 <= high and a[j+1] > a[j]:
j += 1 # 指向右孩子
# 如果子节点比temp大,交换a[i]和a[j]
if a[j] > temp:
a[i] = a[j]
i = j
j = 2 * i + 1
else:
break
a[i] = temp
def HeapSort(a):
if len(a) == 0:
return None
n = len(a)
# 从底向上地建立大根堆,从最后一个非叶子节点开始,即(n-2)//2
for i in range((n - 2) // 2, -1, -1):
adjustHeap(a, i, n-1)
# 从最后一个元素开始,与堆顶调换
for i in range(n-1, -1, -1):
a[0], a[i] = a[i], a[0] # 堆顶与a[i]调换
adjustHeap(a, 0, i-1)
复杂度分析:
- 最佳情况: O ( n log n ) O(n \log n) O(nlogn)
- 最差情况: O ( n log n ) O(n \log n) O(nlogn)
- 平均情况: O ( n log n ) O(n \log n) O(nlogn)
python里堆的内置模块:heapq
# 堆的内置模块
import heapq
a = list(range(100))
random.shuffle(a)
heapq.heapify(a) # 建堆
# 依次出数
for i in range(len(a)):
print(heapq.heappop(a), end=',')
top-k问题: 有n个数,取前k大的数(k<n)
- 取列表前k个元素建立一个小根堆
- 从第k+1个开始依次向后遍历原列表,如果小于堆顶,则跳过改元素;如果大于堆顶,则将该元素放到堆顶,进行一次调整
- 遍历结束后,倒序弹出堆顶
# 调整小根堆
def adjustHeap(a, low, high):
i = low # 指向根节点
j = 2 * i + 1 # 指向根节点的左孩子
temp = a[i]
while j <= high:
# 如果有右孩子,并且右孩子比左孩子小
if j + 1 <= high and a[j+1] < a[j]:
j += 1 # 指向右孩子
# 如果子节点比temp小,交换a[i]和a[j]
if a[j] < temp:
a[i] = a[j]
i = j
j = 2 * i + 1
else:
break
a[i] = temp
def top_k(a, k):
if len(a) == 0:
return None
heap = a[:k]
# 建堆
for i in range((k - 2) // 2, -1, -1):
adjustHeap(heap, i, k-1)
# 遍历
for i in range(k, len(a) - 1):
if a[i] > heap[0]:
heap[0] = a[i]
adjustHeap(heap, 0, k-1)
# 出数
for i in range(k - 1, -1, -1):
heap[0], heap[i] = heap[i], heap[0]
adjustHeap(heap, 0, i - 1)
return heap
六、归并排序
归并: 将两段有序列表合并成一个有序列表
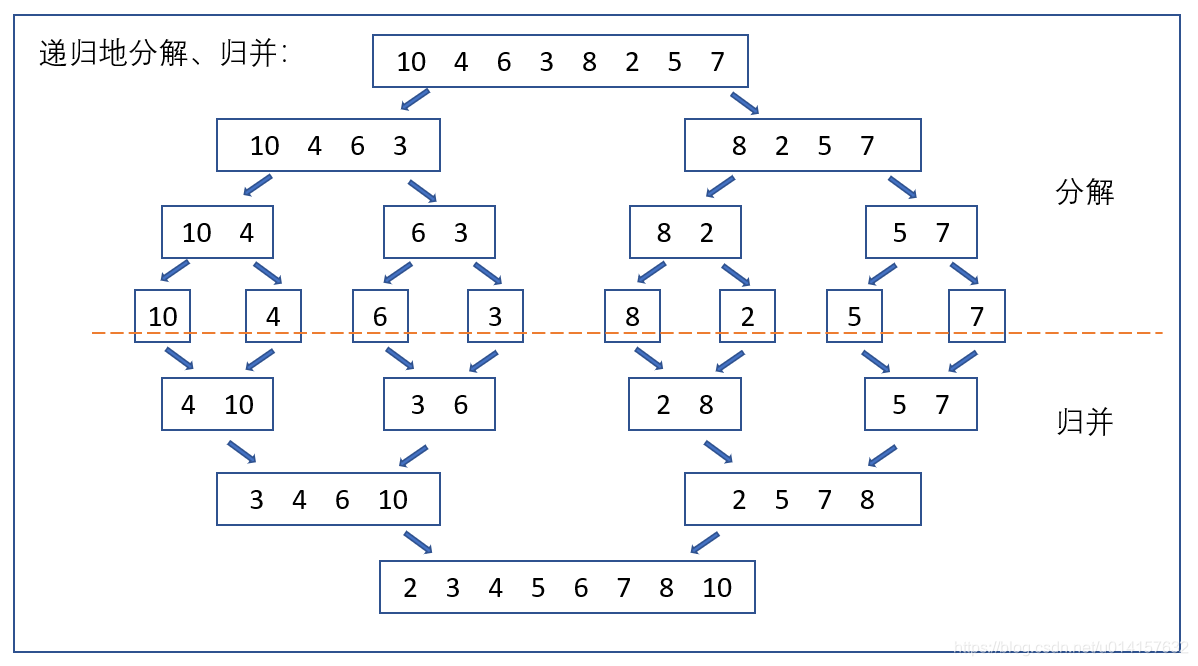
排序过程:
- 把长度为n的输入列表分为长度为n//2的子序列
- 对这两个子序列分别采用归并排序
- 将两个排序好的子序列合并成一个最终的排序序列
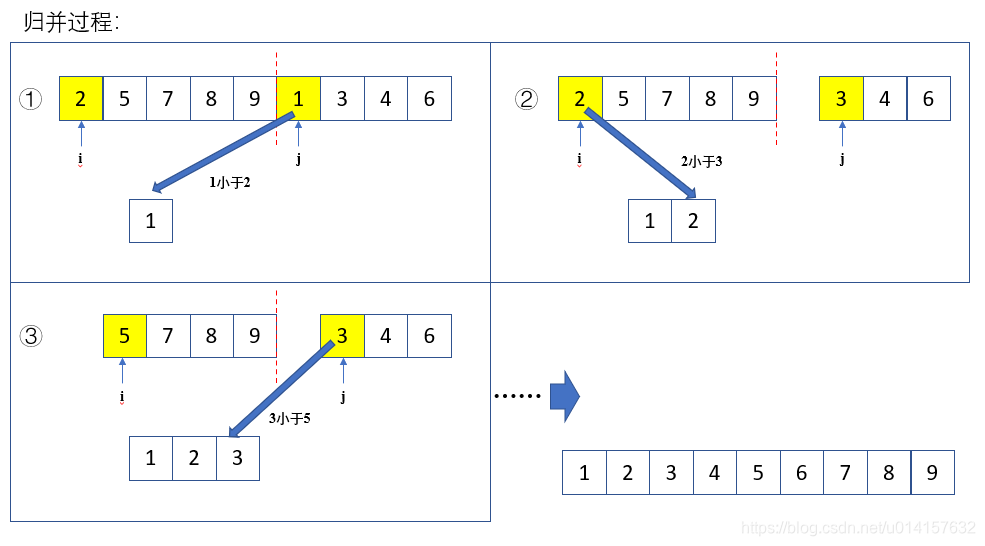
def merge(a, low, mid, high):
# a的左右半边子序列已为有序
i, j = low, mid + 1
temp = []
# 依次比较
while i <= mid and j <= high: # 只要两个子序列还有数
if a[i] < a[j]:
temp.append(a[i])
i += 1
else:
temp.append(a[j])
j += 1
# 上面循环结束后至少有一个子序列已被完全遍历
# 下面将可能剩下的部分添加到temp
temp.extend(a[i:mid+1])
temp.extend(a[j:high+1])
#print(len(a[i:mid+1]), len(a[j:high]), len(a[low:high+1]), len(temp))
# 替换原数组
a[low:high+1] = temp
def MergeSort(a, low, high):
if len(a) == 0:
return None
if low < high:
# low为a的最左边,high为a的最右边,mid为左半边子序列的最右边
mid = (low + high) // 2
# 归并左半边子序列
MergeSort(a, low, mid)
# 归并右半边子序列
MergeSort(a, mid+1, high)
# 合并两个有序子序列
merge(a, low, mid, high)
复杂度分析:
- 最佳情况: O ( n ) O(n) O(n)
- 最差情况: O ( n log n ) O(n \log n) O(nlogn)
- 平均情况: O ( n log n ) O(n \log n) O(nlogn)
七、希尔排序
希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破 O ( n 2 ) O(n^2) O(n2)的第一批算法之一。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序。希尔排序是把记录按下表的一定增量分组,对每组使用直接插入排序算法排序。
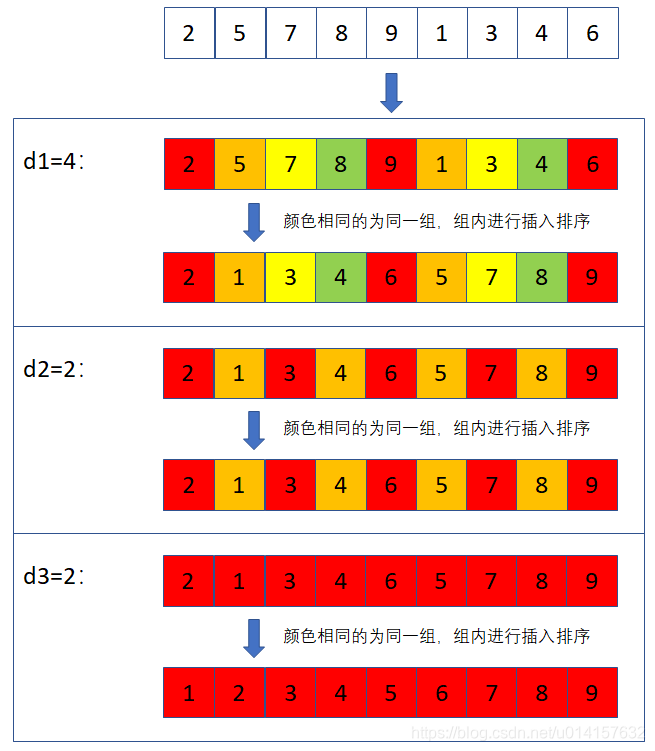
排序过程:
- 首先取一个整数 d 1 = n / / 2 d_1= n // 2 d1=n//2,将列表分为 d 1 d_1 d1个组,每组相邻元素之间距离为 d 1 d_1 d1,在每组里进行插入排序
- 去第二个整数 d 2 = d 1 / / 2 d_2=d_1 // 2 d2=d1//2,重复上述分组排序过程,直到 d i = 1 d_i=1 di=1,即所有元素都在同一组内插入排序
- 希尔排序每趟使列表整体越来越接近有序
def InsertSortWithGap(a, gap):
if len(a) == 0:
return None
for i in range(1, len(a)):
temp = a[i] # 取无序区的第一个数
j = i - gap # 有序区的倒数第一个数索引为i-gap
while j >= 0 and temp < a[j]: # 遍历有序区
a[j + gap] = a[j]
j -= gap
a[j + gap] = temp # 找到temp的位置
def ShellSort(a):
if len(a) == 0:
return None
d = len(a) // 2
while d >= 1:
InsertSortWithGap(a, d)
d //= 2
复杂度分析: 希尔排序的复杂度分析是个难题,根据选取的分组整数序列 d 1 , d 2 , ⋯ , d i d_1, d_2, \cdots, d_i d1,d2,⋯,di的不同,其时间复杂度也不同,有的复杂度由于数学上的难题仍然没有定论。对于我们介绍的一直除2的这种方式:
- 最佳情况: O ( n log 2 n ) O(n \log ^2 n) O(nlog2n)
- 最坏情况: O ( n log 2 n ) O(n \log ^2 n) O(nlog2n)
- 平均情况: O ( n log n ) O(n \log n) O(nlogn)
八、计数排序
基数排序要求已知列表中数的范围在0到 k k k之间
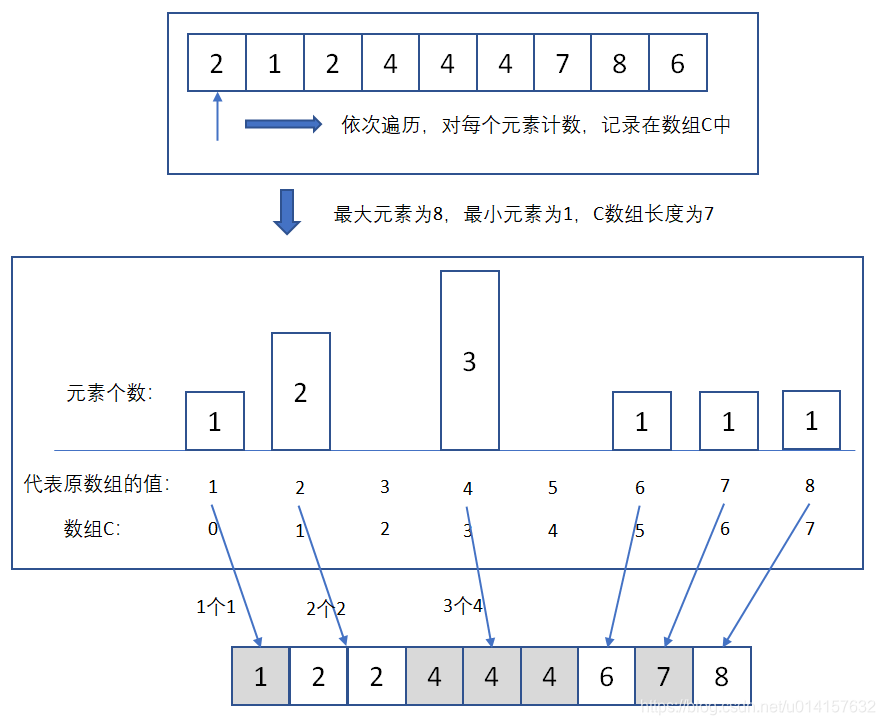
排序过程:
- 步骤1:找出待排序的列表中最大和最小的元素;
- 步骤2:统计数组中每个值为 i i i的元素出现的次数,存入数组 C C C的第 i i i项;
- 步骤3:遍历列表,对所有元素的计数累加;
- 步骤4:填充目标列表:将每个元素 i i i放在新列表的第 C ( i ) C(i) C(i)项,每放一个元素就将 C ( i ) C(i) C(i)减去1。
def CountingSort(a):
if len(a) == 0:
return None
# 找最大最小值
min_, max_ = a[0], a[0]
for num in a:
if num > max_:
max_ = num
if num < min_:
min_ = num
# 初始化计数数组
C = [0] * (max_ - min_ + 1)
# 遍历数组
for num in a:
C[num] += 1
# 填充原数组
a.clear()
for i, c in enumerate(C):
for j in range(c):
a.append(i)
复杂度分析:
- 最佳情况: O ( n + k ) O(n+k) O(n+k)
- 最差情况: O ( n + k ) O(n+k) O(n+k)
- 平均情况: O ( n + k ) O(n+k) O(n+k)
九、桶排序
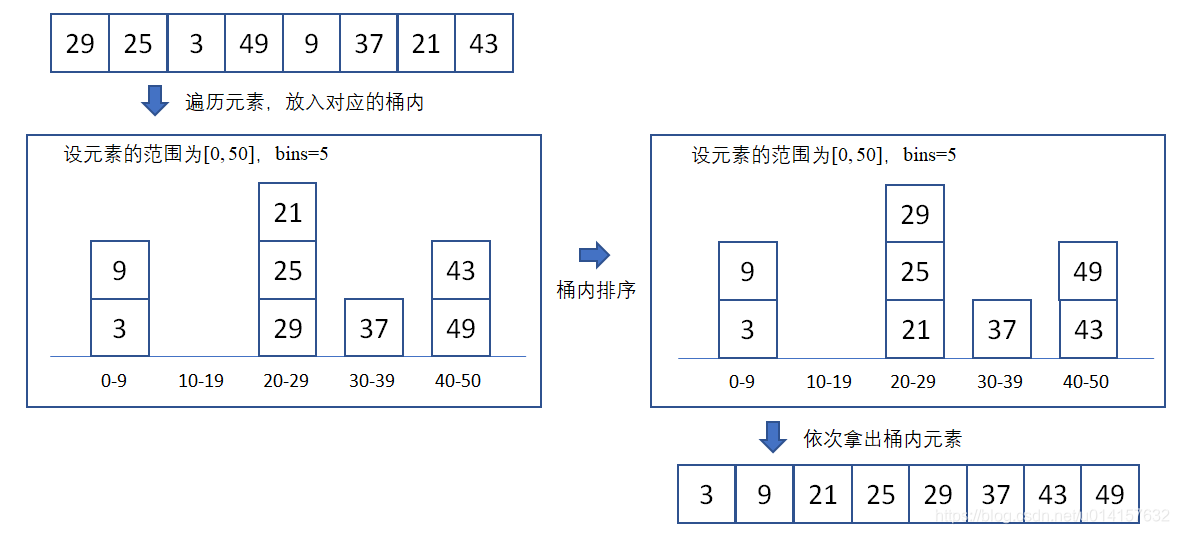
假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序
排序过程:
- 步骤1:人为设置一个bins,即有多少个桶。比如 [ 0 , 1 , ⋯ , 9 , 10 ] [0,1, \cdots, 9, 10] [0,1,⋯,9,10]这个列表,bins=5,那么第一个桶放0、1,第二个桶放2、3,第三个桶放4、5,依次类推;
- 步骤2:遍历列表,并且把元素一个一个放到对应的桶里去;
- 步骤3:对每个不是空的桶进行排序,可以使用其它排序方法,也可以递归使用桶排序;
- 步骤4:从不是空的桶里把排好序的数据拼接起来。
def BucketSort(a, bins):
if len(a) == 0:
return None
# 初始化桶
buckets = [[] for _ in range(bins)]
# 找到最大值最小值
min_, max_ = a[0], a[0]
for num in a:
if num > max_:
max_ = num
if num < min_:
min_ = num
# 遍历
for num in a:
i = min(num // (max_ // bins), bins-1) # 第几号桶
buckets[i].append(num)
# 保持桶内顺序
for j in range(len(buckets[i]) - 1, 0,-1):
if buckets[i][j] < buckets[i][j - 1]: # 桶内下小上大
buckets[i][j], buckets[i][j - 1] = buckets[i][j - 1], buckets[i][j]
else:
break
# 从桶内拿出
sorted_a = []
for bucket in buckets:
sorted_a.extend(bucket)
return sorted_a
复杂度分析:
- 最佳情况: O ( n + k ) O(n+k) O(n+k)
- 最差情况: O ( n 2 ) O(n^2) O(n2)
- 平均情况: O ( n + k ) O(n+k) O(n+k)
十、基数排序
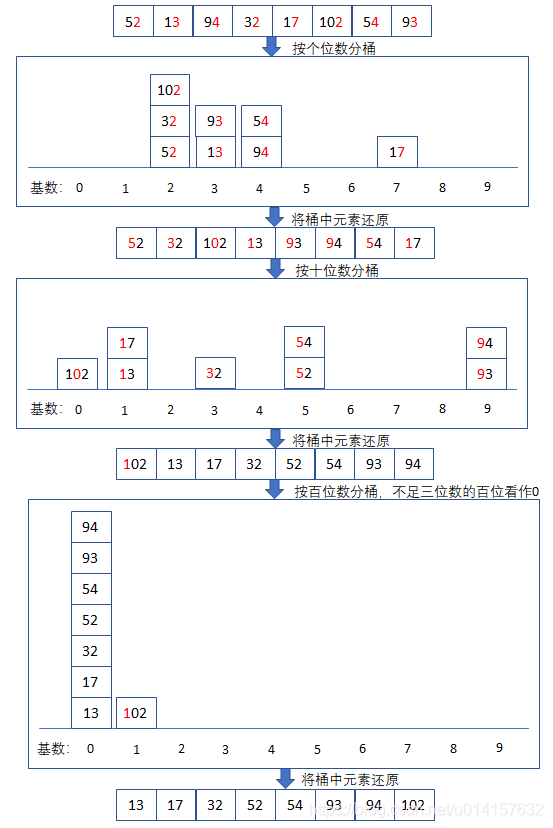
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。
排序过程:
- 步骤1:取得数组中的最大数,并取得位数;
- 步骤2:取列表中元素的最低位,按最低位对元素进行分桶(10个桶,0-9);
- 步骤3:按桶的顺序还原列表,然后取元素的导数第二位,对元素再次分桶;
- 步骤4:重复上述分桶、还原的过程,直到最大元素的最高位
def RadixSort(a):
if len(a) == 0:
return None
max_ = max(a)
it = 0
while 10 ** it <= max_:
# 按倒数第it位分桶
buckets = [[] for _ in range(10)]
for num in a:
digit = (num // 10 ** it) % 10 # 取倒数第it位数
buckets[digit].append(num)
it += 1
# 出桶
a.clear()
for bucket in buckets:
a.extend(bucket)
复杂度分析:
- 最佳情况: O ( n × k ) O(n \times k) O(n×k)
- 最差情况: O ( n × k ) O(n \times k) O(n×k)
- 平均情况: O ( n × k ) O(n \times k) O(n×k)
十一、总结
| 排序算法 | 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 | 排序方式 | 稳定 |
|---|---|---|---|---|---|---|
| 冒泡排序 | O ( n 2 ) O(n^2) O(n2) | O(n) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | in-place | 稳定 |
| 选择排序 | O ( n 2 ) O(n^2) O(n2) | O(n^2) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | in-place | 不稳定 |
| 插入排序 | O ( n 2 ) O(n^2) O(n2) | O(n) | O ( n 2 ) O(n^2) O(n2) | O ( 1 ) O(1) O(1) | in-place | 稳定 |
| 快速排序 | O ( n log n ) O(n \log n) O(nlogn) | O ( n log n ) O(n \log n) O(nlogn) | O ( n 2 ) O(n^2) O(n2) | O ( log n ) O(\log n) O(logn) | in-place | 不稳定 |
| 堆排序 | O ( n log n ) O(n \log n) O(nlogn) | O ( n log n ) O(n \log n) O(nlogn) | O ( n log n ) O(n \log n) O(nlogn) | O ( 1 ) O(1) O(1) | in-place | 不稳定 |
| 归并排序 | O ( n log n ) O(n \log n) O(nlogn) | O ( n log n ) O(n \log n) O(nlogn) | O ( n log n ) O(n \log n) O(nlogn) | O ( n ) O(n) O(n) | out-place | 稳定 |
| 希尔排序 | O ( n log n ) O(n \log n) O(nlogn) | O ( n log 2 n ) O(n \log^2 n) O(nlog2n) | O ( n log 2 n ) O(n \log^2 n) O(nlog2n) | O ( 1 ) O(1) O(1) | in-place | 不稳定 |
| 计数排序 | O ( n + k ) O(n+k) O(n+k) | O(n+k) | O ( n + k ) O(n+k) O(n+k) | O ( k ) O(k) O(k) | out-place | 稳定 |
| 桶排序 | O ( n + k ) O(n+k) O(n+k) | O(n+k) | O ( n 2 ) O(n^2) O(n2) | O ( n + k ) O(n+k) O(n+k) | out-place | 稳定 |
| 基数排序 | O ( n × k ) O(n \times k) O(n×k) | O ( n × k ) O(n \times k) O(n×k) | O ( n × k ) O(n \times k) O(n×k) | O ( n + k ) O(n+k) O(n+k) | out-place | 稳定 |
上表中,in-place表示占用常数内存,不占额外内存(递归内存除外),out-place表示占用额外内存; k k k为桶的个数;稳定表示如果a原本在b前面且a==b,排序后a仍然在b前面,不稳定则是a可能出现在b后面。
参考文献
[1] https://blog.csdn.net/weixin_41190227/article/details/86600821
[2] https://edu.csdn.net/course/detail/24449














 1911
1911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









