






预备步骤
创建anaconda虚拟环境
官网说目前stanza不支持Python3.8的anaconda 命令安装,这里安装Python3.7。
conda create -n test python=3.7
之后激活虚拟环境,开始安装stanza
下载stanza安装包
在虚拟环境中,使用官方提供的安装命令:
conda install -c stanfordnlp stanza
使用 conda list 命令检查是否安装了最新版本,如果不是,使用conda uninstall stanza 命令卸载,再用如下命令重装:
conda install -c stanfordnlp stanza==1.4.0
由于旧版本兼容会有一些问题,这里卸载重装最新的1.4.0版本。
安装包很大,需要一点时间。再次确认安装版本,

后面出现正确版本号,说明下载成功。
添加中文语言包
之后,需要在指定的~/resouces/ 文件夹下下载中文语言模型。
先使用如下代码进行测试:
>>> import stanza
>>> zh_nlp = stanza.Pipeline('zh')
报错:
stanza.resources.common.ResourcesFileNotFoundError: Resources file not found at: C:\Users\user\stanza_resources\resources.json Try to download the model again.
原因是没有找到resources.json文件, 这里去github上寻找该文件下载资源
stanza-resources,页面如下:

这里有多个版本,我们选择resources_1.4.0.json 下载,并改名为“resources.json”保存到错误提示中提到的C:\Users\user\stanza_resources文件夹中。
接着去Hugging Face网站找相应的中文语言模型下载页面stanza-zh-hans,下载default.zip文件。

将default.zip解压后,在上文中的 C:\Users\user\stanza_resources目录下新建一个名为“zh-hans”的文件夹,将解压后的文件全部复制到zh-hans文件夹。
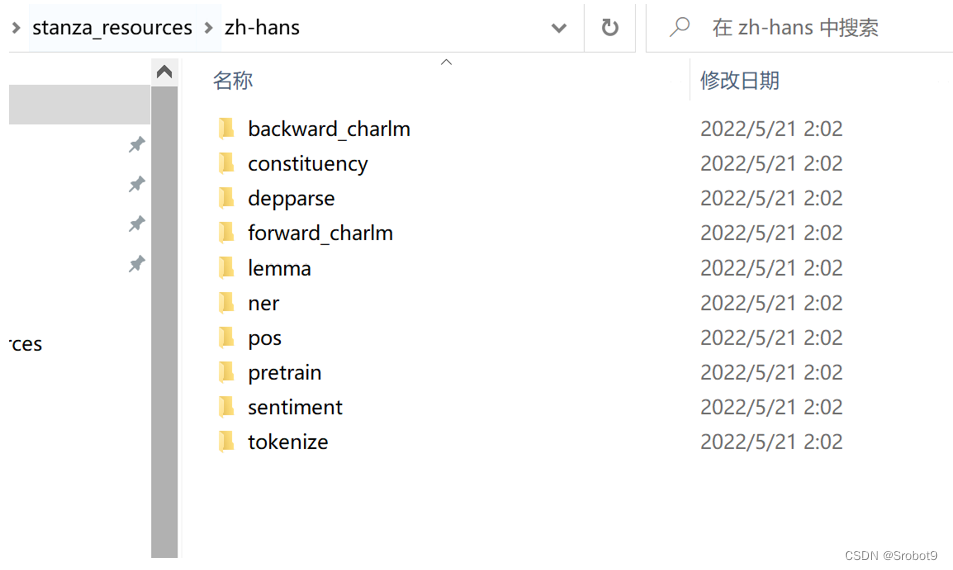
测试
到此,所有安装文件都已准备完毕,继续使用上文的测试代码测试
>>> import stanza
>>> zh_nlp = stanza.Pipeline('zh')
这时,仍然报错:
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='raw.githubusercontent.com', port=443): Max retries exceeded with url: /stanfordnlp/stanza-resources/main/resources_1.4.0.json (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x000001A6708B8708>: Failed to establish a new connection: [Errno 11004] getaddrinfo failed'))
这个错误是说,程序试图通过githubusercontent.com这个域名下载resources_1.4.0.json 时连接失败。这里需要修改程序。让模型去调用我们自己下载的resources.json文件。 具体做法如下:
打开虚拟环境所在目录,找到 ~\Lib\site-packages\stanza\resources\commom,py文件,注释掉download_resources_json()这个函数中的request_file()方法。
原文出处:https://github.com/stanfordnlp/stanza/issues/331#issuecomment-694155072
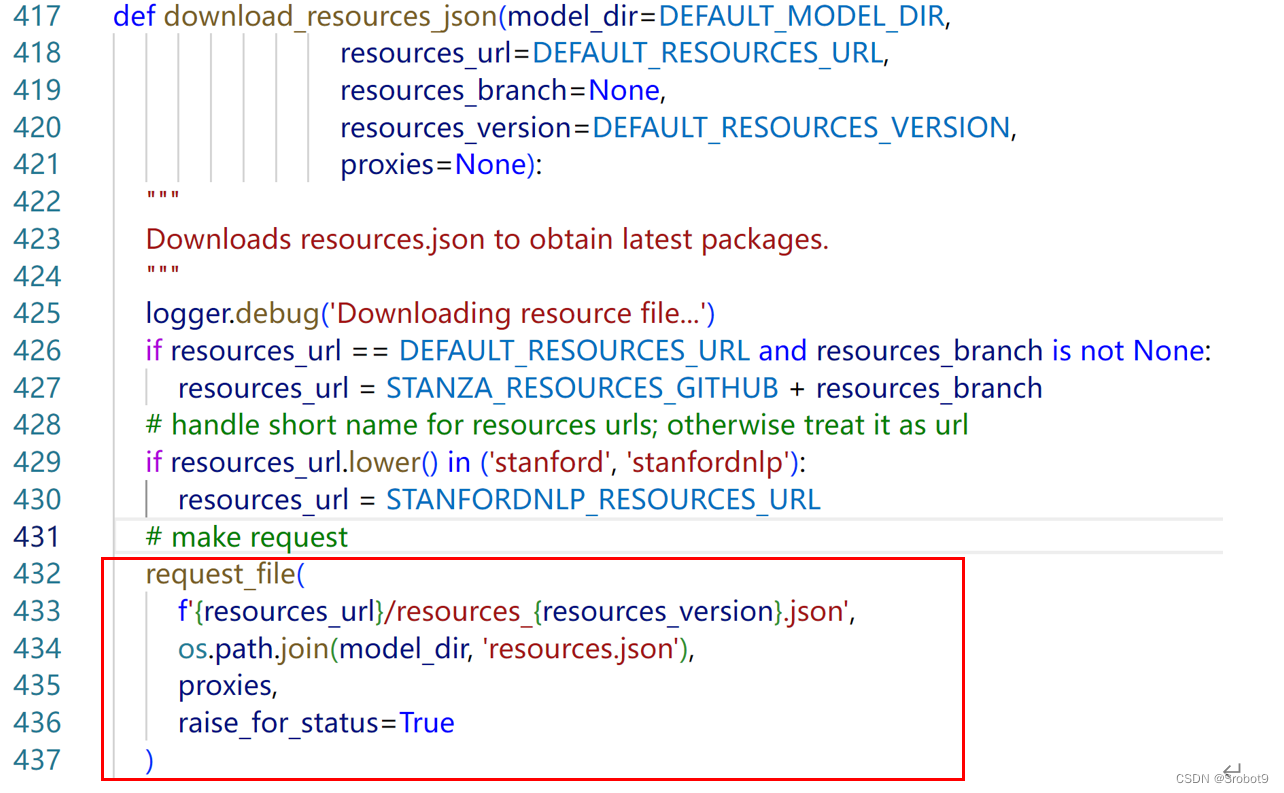
修改好后,重新启动虚拟环境,再次测试:
>>> import stanza
>>> zh_nlp = stanza.Pipeline('zh')
>>> doc = zh_nlp('我喜欢自然语言处理。')
>>> print(doc)
出现以下结果:
[
[
{
"id": 1,
"text": "我",
"lemma": "我",
"upos": "PRON",
"xpos": "PRP",
"feats": "Person=1",
"head": 2,
"deprel": "nsubj",
"start_char": 0,
"end_char": 1,
"ner": "O",
"multi_ner": [
"O"
]
},
{
"id": 2,
"text": "喜欢",
"lemma": "喜欢",
"upos": "VERB",
"xpos": "VV",
"head": 0,
"deprel": "root",
"start_char": 1,
"end_char": 3,
"ner": "O",
"multi_ner": [
"O"
]
},
{
"id": 3,
"text": "自然",
"lemma": "自然",
"upos": "NOUN",
"xpos": "NN",
"head": 4,
"deprel": "nmod",
"start_char": 3,
"end_char": 5,
"ner": "O",
"multi_ner": [
"O"
]
},
{
"id": 4,
"text": "语言",
"lemma": "语言",
"upos": "NOUN",
"xpos": "NN",
"head": 5,
"deprel": "nsubj",
"start_char": 5,
"end_char": 7,
"ner": "O",
"multi_ner": [
"O"
]
},
{
"id": 5,
"text": "处理",
"lemma": "处理",
"upos": "VERB",
"xpos": "VV",
"head": 2,
"deprel": "ccomp",
"start_char": 7,
"end_char": 9,
"ner": "O",
"multi_ner": [
"O"
]
},
{
"id": 6,
"text": "。",
"lemma": "。",
"upos": "PUNCT",
"xpos": ".",
"head": 2,
"deprel": "punct",
"start_char": 9,
"end_char": 10,
"ner": "O",
"multi_ner": [
"O"
]
}
]
]
说明安装成功,这样就可以开始使用stanza处理中文啦。














 1560
1560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









