







1. 生成式模型
1.1 概述
机器学习方法可以分为生成方法(generative approach)和判别方法(discriminative approach),所学到的模型分别称为生成式模型(generative model)和判别式模型(discriminative model)[1 李航]。
生成方法通过观测数据学习样本与标签的联合概率分布P(X, Y),训练好的模型能够生成符合样本分布的新数据,它可以用于有监督学习和无监督学习。
在有监督学习任务中,根据贝叶斯公式由联合概率分布P(X,Y)求出条件概率分布P(Y|X),从而得到预测的模型,典型的模型有朴素贝叶斯、混合高斯模型和隐马尔科夫模型等。无监督生成模型通过学习真实数据的本质特征,从而刻画出样本数据的分布特征,生成与训练样本相似的新数据。生成模型的参数远远小于训练数据的量,因此模型能够发现并有效内化数据的本质,从而可以生成这些数据。生成式模型在无监督深度学习方面占据主要位置,可以用于在没有目标类标签信息的情况下捕捉观测到或可见数据的高阶相关性。
深度生成模型可以通过从网络中采样来有效生成样本,例如受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)、深度信任网络(Deep Belief Network, DBN)、深度玻尔兹曼机(Deep Boltzmann Machine, DBM)和广义除噪自编码器(Generalized Denoising Autoencoders)。近两年来流行的生成式模型主要分为三种方法[OpenAI 首批研究]:
1.1.1 生成对抗网络(GAN:Generative Adversarial Networks)
GAN启发自博弈论中的二人零和博弈,由[Goodfellow et al, NIPS 2014]开创性地提出,包含一个生成模型(generative model G)和一个判别模型(discriminative model D)。生成模型捕捉样本数据的分布,判别模型是一个二分类器,判别输入是真实数据还是生成的样本。这个模型的优化过程是一个“二元极小极大博弈(minimax two-player game)”问题,训练时固定一方,更新另一个模型的参数,交替迭代,使得对方的错误最大化,最终,G 能估测出样本数据的分布。
1.1.2 变分自编码器(VAE: Variational Autoencoders)
在概率图形模型(probabilistic graphical models )的框架中对这一问题进行形式化——在概率图形模型中,我们在数据的对数似然上最大化下限(lower bound)。
1.1.3 自回归模型(Autoregressive models)
PixelRNN 这样的自回归模型则通过给定的之前的像素(左侧或上部)对每个单个像素的条件分布建模来训练网络。这类似于将图像的像素插入 char-rnn 中,但该 RNN 在图像的水平和垂直方向上同时运行,而不只是字符的 1D 序列。
1.2 生成式模型的分类[重磅 | Yoshua Bengio深度学习暑期班]
1.2.1 全观察模型(Fully Observed Models)
模型在不引入任何新的非观察局部变量的情况下直接观察数据。这类模型能够直接编译观察点之间的关系。对于定向型图模型,很容易就能扩展成大模型,而且因为对数概率能被直接计算(不需要近似计算),参数学习也很容易。对于非定向型模型,参数学习就困难,因为我们需要计算归一化常数。全观察模型中的生成会很慢。下图展示了不同的全观察生成模型[图片来自Shakir Mohamed的展示]:

1.2.2 变换模型( Transformation Models)
模型使用一个参数化的函数对一个非观察噪音源进行变换。很容易做到(1):从这些模型中取样 (2):在不知道最终分布的情况下仅算期望值。它们可用于大型分类器和卷积神经元网络。然而,用这些模型维持可逆性并扩展到一般数据类型就很难了。下图显示了不同的变换生成模型[图片来自Shakir Mohamed的展示]:
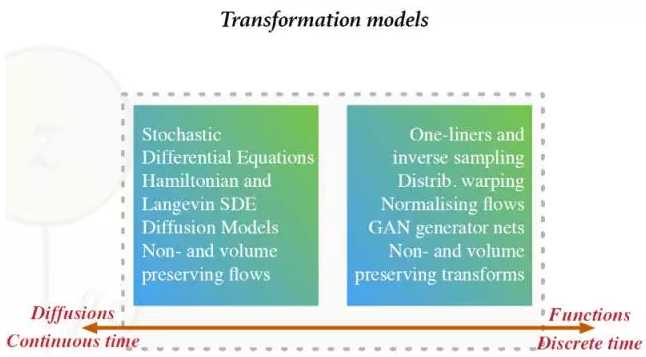
1.2.3 隐变量模型( Latent Variable Models)
这些模型中引入了一个代表隐藏因素的非观察局部随机变量。从这些模型中取样并加入层级和深度是很容易的。也可以使用边缘化概率进行打分和模型选择。然而,决定与一个输入相联系的隐变量却很难。下图显示了不同的隐变量生成模型[图片来自Shakir Mohamed的展示]:
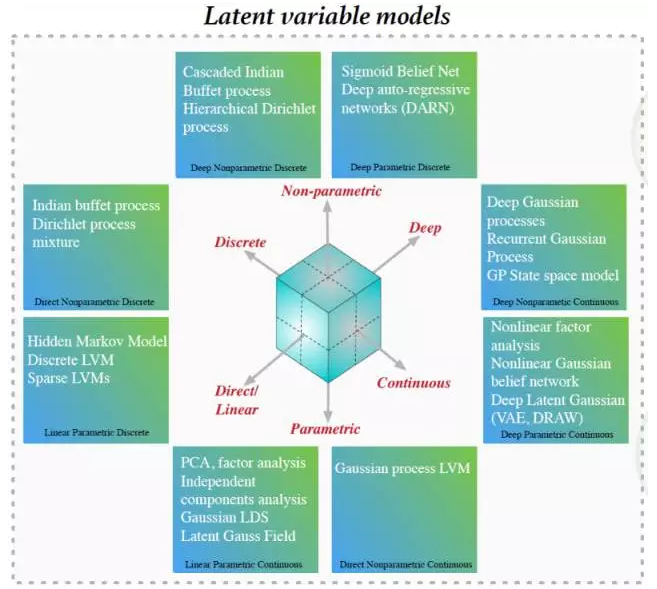
1.3 生成式模型的应用
我们需要生成(Generative models)模型,这样就能从关联输入移动到输出之外,进行半监督分类(semi-supervised classification)、数据操作(data operating)、填空(filling in the blank)、图像修复(inpainting)、去噪(denoising)、one-shot生成 [Rezende et al, ICML 2016]、和其它更多的应用。下图展示了生成式模型的进展(注意到纵轴应该是负对数概率)[图片来自Shakir Mohamed的展示]:
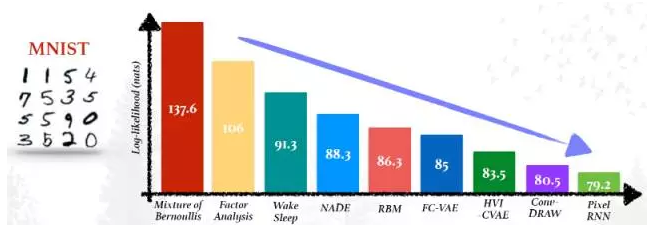
另据2016 ScaledML会议IIya Sutskever的演讲报告“生成模型的近期进展”介绍,生成模型主要有以下功能:
- Structured prediction,结构化预测(例如,输出文本);
- Much more robust 更鲁棒的预测
- Anomaly detection,异常检测
Model-based RL,基于模型的增强学习
生成模型未来推测可以加以应用的领域:
Really good feature learning, 非常好的特征学习
- Exploration in RL, 在强化学习中的探索
- Inverse RL, 逆向增强学习
- Transfer learning, 迁移学习















 6228
6228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









