







python实现EM聚类算法
实验结果

当前的分类概率参数:PI_1:0.33334922292091,PI_2:0.66665077707909
当前的分类值: [0 0 1 0 1 1 1 1 1]
分类1 ['T100' 'T200' 'T400']
分类2 ['T300' 'T500' 'T600' 'T700' 'T800' 'T900']
基于下面的数据,采用EM算法将下面的数据聚成2类
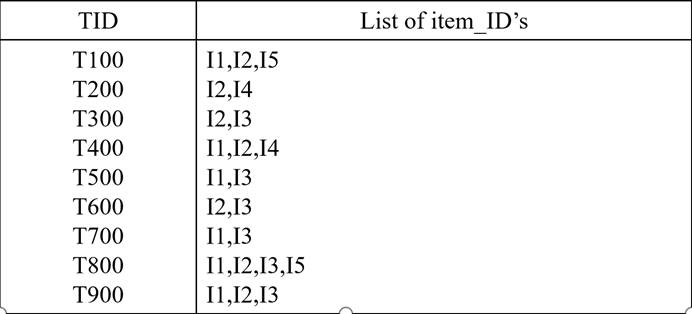

E步公式:

M步公式:

1 数据工程:
创建dataset.scv文件,文件内容如下。
T
I
D
TID
TID为用户购买id,
I
i
I_i
Ii表示商品类别,数字1表示用户购买了该商品

2 参数准备
- 该实验将类别分为2个分类,故设定
π
1
,
π
2
\pi_1,\pi_2
π1,π2为观察值来自两个类别中的概率。初始参数为
π
1
=
0.6
,
π
2
=
0.4
\pi_1=0.6,\pi_2=0.4
π1=0.6,π2=0.4
- 例如:
T100观察值来自类别 π 1 \pi_1 π1的概率为0.6
- 例如:
- x ( i ) j x(i)_j x(i)j 表示用户 i i i购买商品 j j j 的情况,取值为0或者1
- θ k j \theta_{kj} θkj 表示在第 k k k 个分类中观察到 j = 1 j=1 j=1 的概率
- p ( k ∣ i ) p(k|i) p(k∣i) 表示第 i 条数据属于第 k 个分量的概率
3 计算
由EM算法步骤可得,EM分为两部分,即E和M部分
-
E:对每个对象,计算它们属于各个分布的概率,即求出每一行对象,在分类1和2上面的概率
- 公式为: P ( C i ∣ x j ) = f ( x j ∣ μ i , σ i 2 ) ∙ P ( C i ) ∑ a = 1 k f ( x j ∣ μ a , σ a 2 ) ∙ P ( C a ) P(C_i|x_j)=\frac{f(x_j|\mu_i,\sigma_i^2)\bullet P(C_i) }{\sum_{a=1}^k f(x_j|\mu_a,\sigma_a^2)\bullet P(C_a)} P(Ci∣xj)=∑a=1kf(xj∣μa,σa2)∙P(Ca)f(xj∣μi,σi2)∙P(Ci)
- 计算公式为:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M4s6XbGG-1653982609027)(机器学习作业.assets/20220531091848.png)]
- 拆解计算
- P C 1 PC_1 PC1为当前用户使用分类1的概率乘以 参数分布情况概率的乘积
- P C 2 PC_2 PC2为当前用户使用分类2的概率乘以 参数分布情况概率的乘积
- P C 1 = P C 1 / ( P C 1 + P C 2 ) PC_1=PC_1/(PC_1+PC_2) PC1=PC1/(PC1+PC2) P C 2 = 1 − P C 1 PC_2=1-PC_1 PC2=1−PC1 表示对象在2类分类中的概率
- 得到所有对象的分类概率 P C PC PC
-
M: 根据上步得出的所有对象所属分类的概率,计算能够最大化似然 函数的新的参数估计,直到参数不再改变
- 计算新的
π
\pi
π
- 公式: π k = 1 n ∑ i = 1 n P ( k ∣ x ( i ) ) \pi_k=\frac{1}{n} \sum_{i=1}^{n} P(k|x(i)) πk=n1∑i=1nP(k∣x(i))
- 代码$ new_\pi[k]=mean(PC[:,k])$ 求当前每个分类下的均值,作为新的 π \pi π
- 更新 参数取值概率
- 公式: θ k j n e w = ∑ i = 1 n p ( k ∣ i ) x j ( i ) ∑ i = 1 n p ( k ∣ i ) \theta_{kj}^{new}=\frac{\sum_{i=1}^n p(k|i)x_j(i)}{\sum_{i=1}^{n}p(k|i)} θkjnew=∑i=1np(k∣i)∑i=1np(k∣i)xj(i)
- 代码$ \theta[k]=((np.matrix(observations).T*np.matrix(PC)).T.getA())[k]/sum(PC[:,k])$
- 计算新的
π
\pi
π
4 源代码:
# -*- coding: utf-8 -*-
# @Time : 2022/5/30 21:06
# @Author : PVINCE
# @File : NewEm.py
#@desc:使用EM聚类
import math
import numpy as np
import pandas as pd
def E(observations,pi,nums_k,theta):
ob_length=len(observations)
PC = np.zeros((ob_length, nums_k), float)
i = 0
for observation in observations:
j=0
PC_1=pi[0]
PC_2=pi[1]
for colums in observation:
PC_1*=math.pow(theta[0][j],colums) *math.pow((1-theta[0][j]),1-colums)
PC_2*=math.pow(theta[1][j],colums) *math.pow((1-theta[1][j]),1-colums)
j=j+1
PC[i][0]=PC_1/(PC_1+PC_2)#得到I对象属于类别1的概率
PC[i][1]=1-PC[i][0]##得到I对象属于类别2的概率
i=i+1
return PC#返回当前Pi下所有对象的预测值类别概率
def M(observations,PC,theta):
# 更新Pi和theta
new_pi=np.zeros(2,float)
new_pi[0]=np.mean(PC[:,0])
new_pi[1]=np.mean(PC[:,1])
theta[0]=((np.matrix(observations).T*np.matrix(PC)).T.getA())[0]/sum(PC[:,0])
theta[1]=((np.matrix(observations).T*np.matrix(PC)).T.getA())[1]/sum(PC[:,1])
return new_pi,theta
# ====以下为预设值========
observations=[[1,1,0,0,1],
[0,1,0,1,0],
[0,1,1,0,0],
[1,1,0,1,0],
[1,0,1,0,0]]
lable=['T100','T200',"T300","T400","T500"]
# ====预设值ENd======== 分类结果:分类1 ['T100' 'T200' 'T400']分类2 ['T300' 'T500']
# ========以下为CSV文件中的数据========
data_ori = pd.read_csv('./dataset.csv', encoding='utf-8')
features_scv = data_ori.columns[1:]
observations = data_ori[features_scv].values
lable=data_ori[data_ori.columns[0]].values
#=========csv结束====== 分类结果:分类1 ['T100' 'T200' 'T400'],分类2 ['T300' 'T500' 'T600' 'T700' 'T800' 'T900']
#分类个数
nums_k=2
# 类别概率
pi=[0.6,0.4]
#类别属性选择概率:类别为k,故参数k行
theta=[[0.6,0.6,0.3,0.5,0.3],
[0.4,0.4,0.7,0.5,0.7]
]
new_pi=np.array(pi)
# 比较两个分类参数的精度设置
dot_count=4
# 循环次数
count=0
while True:
print("{}当前的分类概率参数:PI_1:{},PI_2:{}".format(count,new_pi[0], new_pi[1]))
print("{}当前的特征参数概率:".format(count), np.array(theta))
count=count+1
last_pi=new_pi
PC = E(observations, new_pi, nums_k, theta)
new_pi, theta = M(observations, PC, theta)
if (new_pi <= 0).any():break
if(np.round(new_pi,dot_count)==np.round(last_pi,dot_count)).all():break
print("当前的分类概率参数:PI_1:{},PI_2:{}".format(last_pi[0], last_pi[1]))
print("当前的分类值:",np.argmax(np.array(PC),axis=1))
catat1=[]
catat2=[]
i=0
for idx in np.argmax(np.array(PC),axis=1):
if idx==0:catat1.append(lable[i])
if idx==1:catat2.append(lable[i])
i=i+1
print("分类1",np.array(catat1))
print("分类2",np.array(catat2))
5 实验结果
inputs:k=2,pi=[0.6,0.4] ,
theta=[[0.6,0.6,0.3,0.5,0.3],
[0.4,0.4,0.7,0.5,0.7]]
outputs:
当前的分类概率参数:PI_1:0.33334922292091,PI_2:0.66665077707909
当前的分类值: [0 0 1 0 1 1 1 1 1]
分类1 ['T100' 'T200' 'T400']
分类2 ['T300' 'T500' 'T600' 'T700' 'T800' 'T900']

参数变化
类别1的概率变化
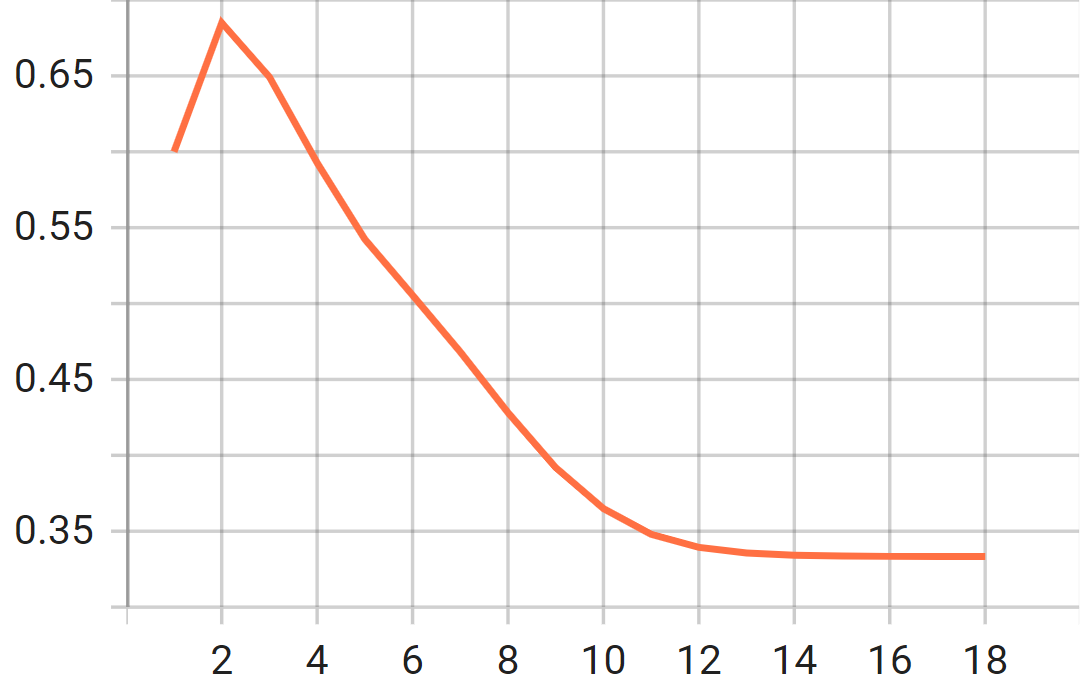
类别2的概率变化

















 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











