









决策树是基于树结构进行决策的,是人类在面临决策问题时的一种很自然的处理机制。当我们进行决策时,会考虑一系列因素并进行判断,得到我们的最终结论。
一颗决策树包含一根节点,若干个内部节点和若干个叶节点,叶节点对应于决策结果,其他每个节点则对应一个属性测试,每个节点包含样本集合根据属性测试的结果被划分到子节点中;根节点包含样本全集,从根节点到每个叶节点的路径对应了一个判断测试序列。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的分而治之策略。
决策树基本算法如图所示:

决策树的生成是一个递归过程,在决策树基本算法中,有三种情形会导致递归返回:
1.当前节点包含的样本全属于同一类别,无需划分
2.当前属性集为空,或是所有样本在属性上取值相同,无法划分
3.当前节点包含的样本集为空,不能划分
在情形2下,我们把当前节点标记为叶节点,并将其类别设定为该节点所包含样本最多的类别;在情形3下,同样把当前节点标记为叶节点,但将其设定为其父节点所含样本最多的类别。
注意:情形2是利用当前节点的后验分布,而情形3则是把父节点样本分布作为当前节点的先验分布。
我们希望决策树的分支节点所包含的样本尽可能属于同一类别,即节点纯度越来越高。
则有如下三种(信息增益,增益率,基尼指数)进行划分。
信息增益:
信息熵是度量样本集合纯度最常用的一种指标。假定当前样本集合D中第k类样本所占比例pk,则D信息熵等于 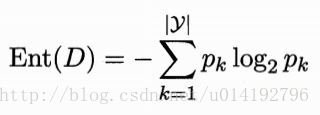
假定离散属性a有V个可能的取值{a1,a2,……av},若使用a来对样本D进行划分,则会产生v个分支节点,其中第v个分支节点包含了D所有在属性a上取值av的样本,集为Dv。
信息增益公式:
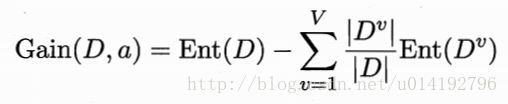
一般而言,信息增益越大,则意味着使用属性a来进行划分获得的纯度提升越大。著名的ID3算法就是以信息增益为准则来选择划分属性。
增益率:
信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,c4.5不采用信息增益,而是使用增益率来选择最优属性。
增益率表示如下:
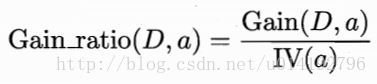
其中: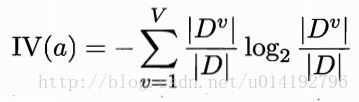
称为属性a的固有值,属性a可能取值数目越多,则IV(a)的值通常会越大。
注意:增益率准则对可取数目较少的值有所偏好,因此C4.5并不是直接选择增益率最大的候选话分属性,而是先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高。
基尼指数
数据集的基尼指数:
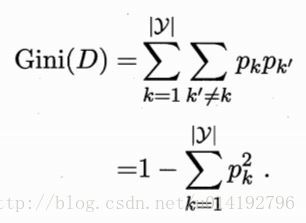
直观来说,Gini(D)反映了数据集D中随机抽取两个样本,其类别不一致的概率。因此Gini越小,则数据集纯度越高。
属性a的基尼指数定义:
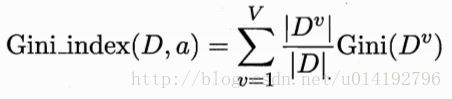
在候选集中,选择那个使得划分后基尼指数最小的属性作为最优划分属性。
以上内容摘自 周志华西瓜书
下面就来简单实践一下
数据集格式如下:
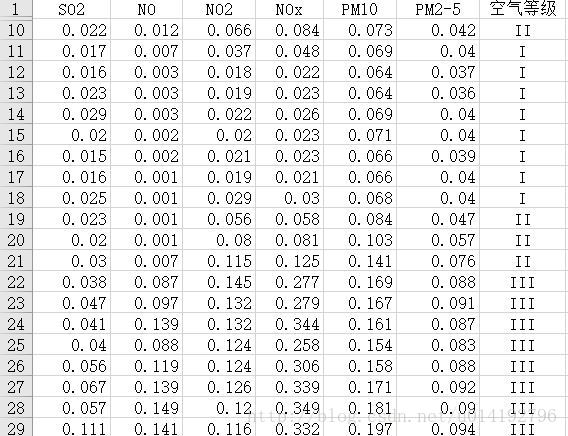
该经过处理后的数据集中有’SO2’,’NO’,’NO2’,’NOx’,’PM10’,’PM2-5’共计6个属性值,一个指标label空气等级。
导入pandas库
# -*- coding:utf-8 -*-
import pandas as pd由于数据的label是[‘I’,’II’,’III’,’IV’,’V’,’VI’,’VII’],不利于识别和计算,因此将其替换为[1,2,3,4,5,6,7])。
df=pd.read_excel(u'拓展思考样本数据.xls',encoding='utf-8')
data=df.replace(['I','II','III','IV','V','VI','VII'],[1,2,3,4,5,6,7])
data=data.as_matrix()#向量形式随机打乱顺序,抽取训练集和测试集,并划分特征与标签
from numpy.random import shuffle #引入随机函数
shuffle(data) #随机打乱数据
data_train = data[:int(0.8*len(data)), :] #选取前80%为训练数据
data_test = data[int(0.8*len(data)):, :] #选取前20%为测试数据
#构造特征和标签
x_train = data_train[:, :6]
y_train = data_train[:,6]
x_test = data_test[:,:6]
y_test = data_test[:,6]训练模型
#导入模型相关的函数,建立并且训练模型
from sklearn import tree
clf=tree.DecisionTreeClassifier(criterion='gini')
clf.fit(x_train,y_train) 保存模型
import pickle
pickle.dump(clf, open('tree.model','wb'))引入混淆矩阵,直观反映判断准确率
from sklearn import metrics
cm_train = metrics.confusion_matrix(y_train, clf.predict(x_train))
cm_test = metrics.confusion_matrix(y_test, clf.predict(x_test))
pd.DataFrame(cm_train).to_excel('cm_train.xls')
pd.DataFrame(cm_test).to_excel('metrics_test.xls')接下来介绍一个比较实用的决策树可视化库graphviz
这个库可以直接将决策树模型导出为树状图
下面是两种使用方法:
1
import graphviz
dot_data = tree.export_graphviz(clf, out_file='tree_1.dot')
graph = graphviz.Source(dot_data) 2
dot_data = tree.export_graphviz(clf, out_file='tree.dot',
feature_names=['SO2','NO','NO2','NOx','PM10','PM2-5'],
class_names=['1','2','3','4','5','6','7'],
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data) 最后介绍一种python中直接使用cmd的方法
dot格式的文件其实是一种类似文本格式的文件,我们还需要通过cmd命令来将其转化成图片形式,方便我们在线显示。但是切换出去实在是比较麻烦,忍不住要说句mmp了。后来发现os库的妙用,直接调用os.system(‘commend’) 来执行,其中commend为windows命令。这就相当于在cmd窗口中执行命令了。
import matplotlib.pyplot as plt # plt 用于显示图片
import matplotlib.image as mpimg # mpimg 用于读取图片
%matplotlib inline#在线显示 nootbook
plt.rcParams['figure.figsize'] = (20.0, 15.0)#定义图的大小
import os
os.system('dot -Tpng tree.dot -o tree_1.png')
dot = mpimg.imread('tree_1.png')
plt.imshow(dot)决策树图如下所示
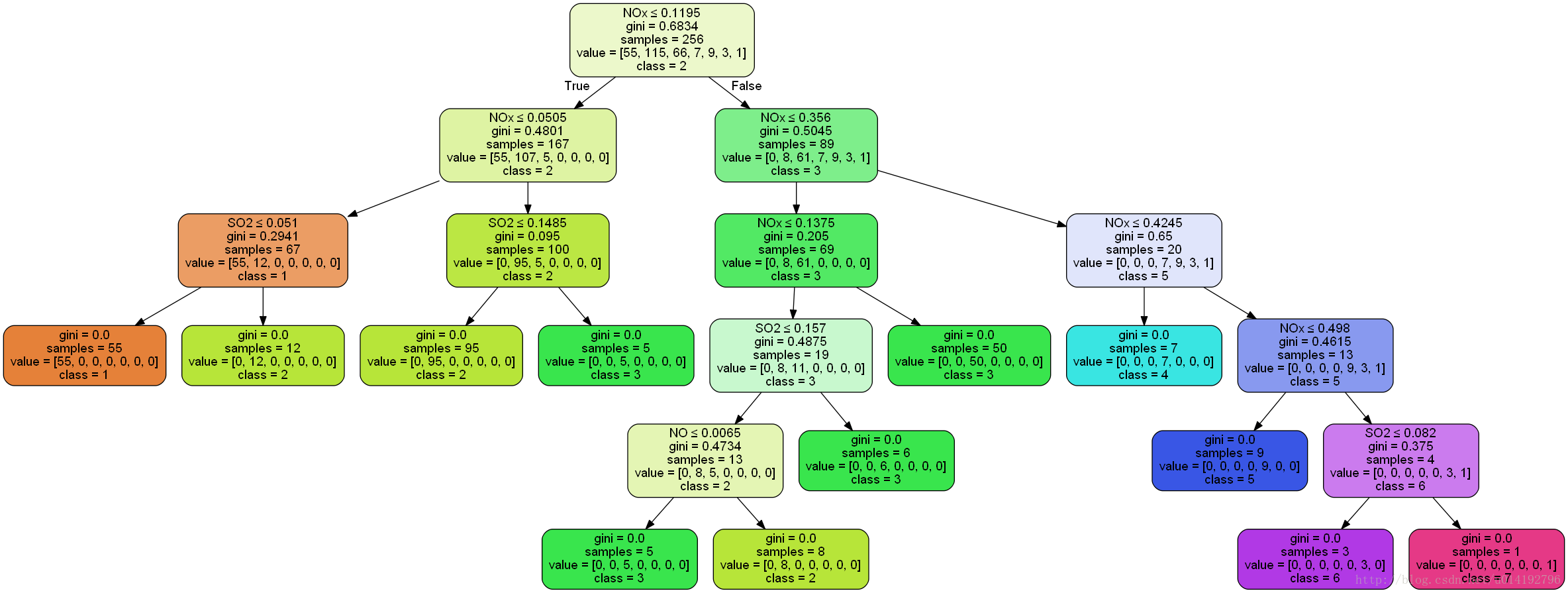















 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









