










目录
一. Attention
Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射。在计算attention时主要分为三步,
第一步,是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;
第二步,使用一个softmax函数对这些权重进行归一化;
第三步,将权重和相应的键值value进行加权求和得到最后的attention。

二. Self-Attention
对于self-attention来讲,Q(Query), K(Key), V(Value)三个矩阵均来自同一输入。
将所有输入词向量合并成输入矩阵X(输入矩阵X的每一行表示输入句子的一个词向量),并且将其分别乘以权重矩阵,则所有query, key, value向量也可以合并为矩阵形式表示Q、K、V。
首先我们要计算Q和K的转置矩阵做点积,
然后为了防止其结果过大(梯度会更稳定),会除以一个尺度标度 ,其中
为一个query或key向量的维度。
再利用Softmax操作将其结果归一化为概率分布,
然后再乘以矩阵V就得到权重求和的表示。该操作可以表示为
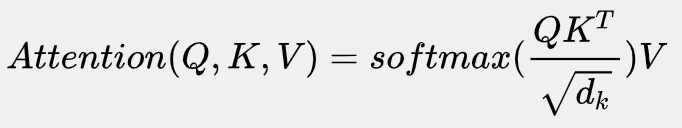

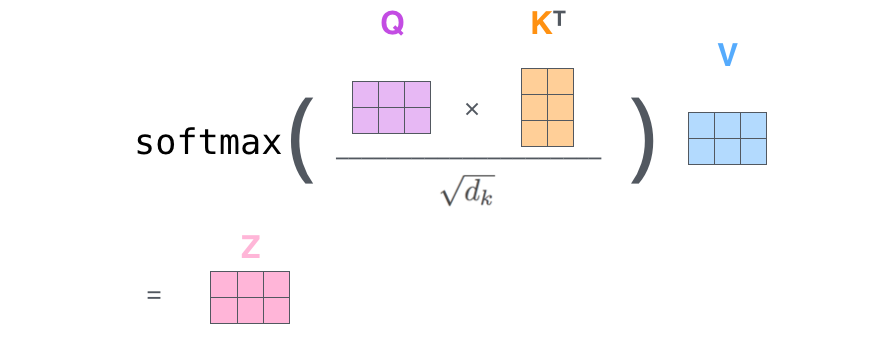
三. Transformer
接下来,介绍google2017年的论文《Attention is all you need》中提出的Transformer,是BERT等后续模型的基础。
对于使用自注意力机制的Transformer,有两点重要优势,提高了运行速度(降低每一层的计算复杂度,矩阵运算,多头可以并行),解决长距离依赖学习难题(最大的路径长度也都只是1)。
Transformer的整体结构如下图,还是由编码器和解码器组成。
在编码器的一个网络块中,由一个多头self-attention子层和一个前馈神经网络子层组成,整个编码器栈式搭建了N个块。
解码器,类似于编码器,只是解码器的一个网络块中多了一个多头attention层。
为了更好的优化深度网络,整个网络使用了残差连接和对层进行了规范化(Add&Norm)。
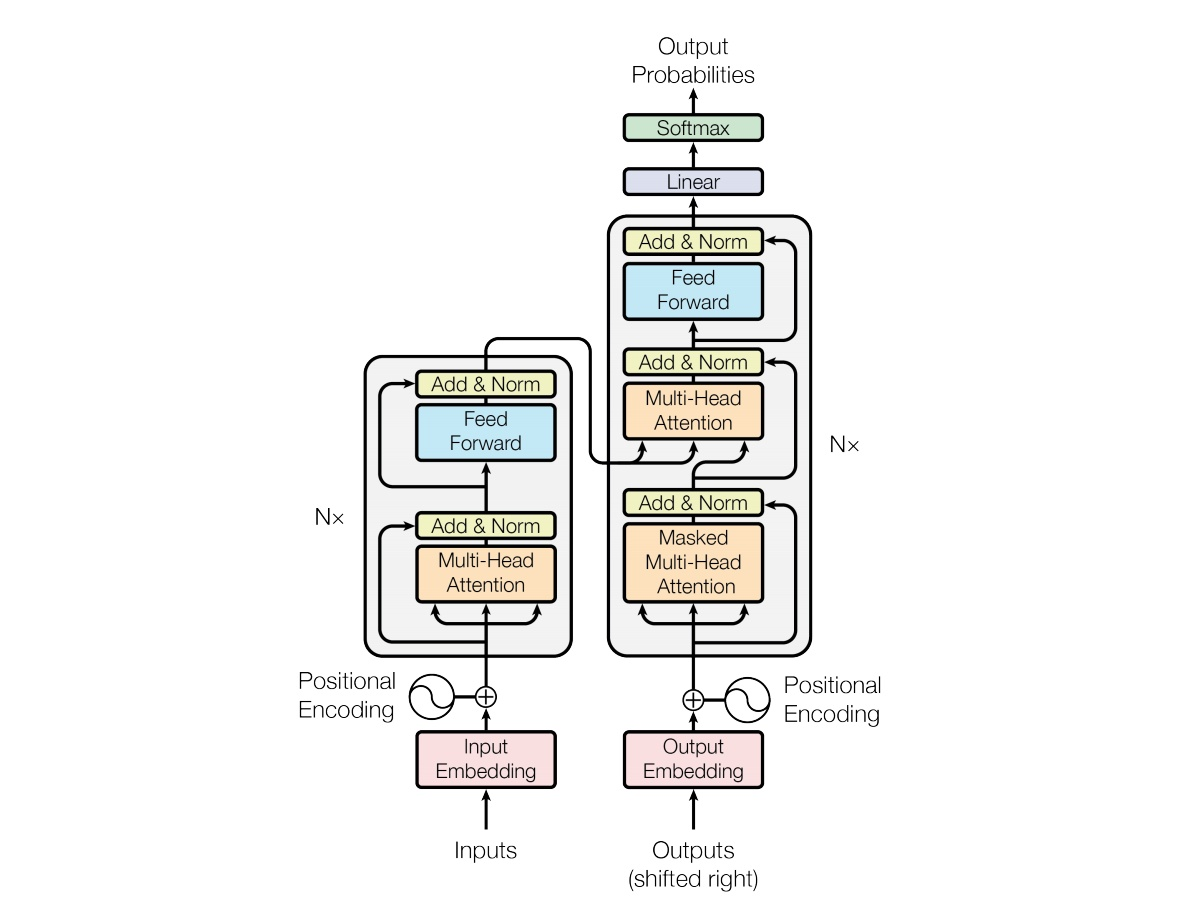
每一个编码器都可以拆解成以下两个字部分。
对输入序列做词的向量化之后,每个位置的词向量被送入self-attention模块,然后是前向网络,最后将输入传入下一个编码器。

这里能看到Transformer的一个关键特性,每个位置的词仅仅流过它自己的编码器路径。在self-attention层中,这些路径两两之间是相互依赖的。但前向网络层则没有这些依赖性,对每个向量都是完全相同的网络结构,这些路径在流经前向网络时可以并行执行。

解码器同样也有这些子层,但是在两个子层间增加了attention层,该层有助于解码器能够关注到输入句子的相关部分,与 Seq2Seq模型的Attention作用相似。
这里先明确一下decoder的输入输出和解码过程:
输出:对应i位置的输出词的概率分布;
输入:encoder的输出 & 对应i-1位置decoder的输出。所以中间的attention不是self-attention,它的K,V来自encoder,Q来自上一位置decoder的输出;
解码:这里要特别注意一下,编码可以并行计算,一次性全部encoding出来,但解码不是一次把所有序列解出来的,而是像rnn一样一个一个解出来的,因为要用上一个位置的输入当作attention的query。
3.1 multi-headed
论文进一步增加了multi-headed的机制到self-attention上,在多头下有多组,而非仅仅一组(论文中使用8-heads)。每一组都是随机初始化,经过训练之后,输入向量可以被映射到不同的子表达空间中。

将h次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。

3.2 Positional Encoding
除了主要的Encoder和Decoder,还有数据预处理的部分。Transformer加入了相对位置信息,提出两种Positional Encoding的方法,
(1)用不同频率的sine和cosine函数直接计算
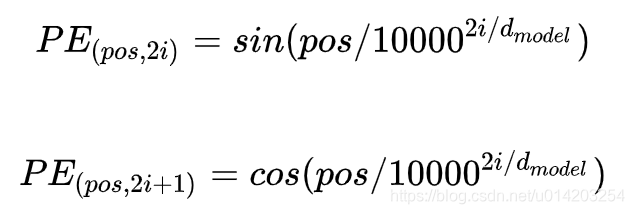
(2)学习出一份positional embedding
3.3 Add & Normalize
在每个子层中(slef-attention, ffnn),都有残差连接,并且紧跟着Layer Normalization。

如果我们可视化向量和layer-norm操作,将如下所示:
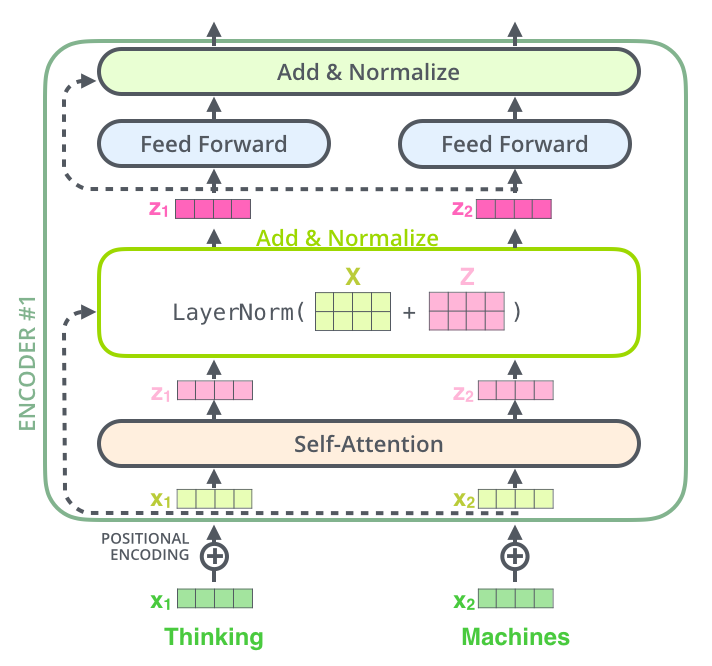
其中Add代表了Residual Connection,是为了解决多层神经网络训练困难的问题,通过将前一层的信息无差的传递到下一层,可以有效的仅关注差异部分。
而Norm则代表了Layer Normalization,通过对层的激活值的归一化,可以加速模型的训练过程,使其更快的收敛,可参考这篇论文Layer Normalization。
残差网络
参考 https://blog.csdn.net/wspba/article/details/57074389
深层模型在很多任务发挥优势效果,随“深”而来的一个问题就是,梯度消失/梯度爆炸,这从一开始便阻碍了模型的收敛。各种Normalization方法在很大程度上解决了这一问题,它使得数十层的网络在反向传播的随机梯度下降(SGD)上能够收敛。然而,当深层网络能够收敛时,一个退化问题又出现了:随着网络深度的增加,准确率达到饱和(不足为奇)然后迅速退化。意外的是,这种退化并不是由过拟合造成的,并且在一个合理的深度模型中增加更多的层却导致了更高的错误率。
退化的出现(训练准确率)表明了并非所有的系统都是很容易优化的。让我们来比较一个浅层的框架和它的深层版本。对于更深的模型,这有一种通过构建的解决方案:恒等映射(identity mapping)来构建增加的层,而其它层直接从浅层模型中复制而来。这个构建的解决方案也表明了,一个更深的模型不应当产生比它的浅层版本更高的训练错误率。实验表明,我们目前无法找到一个与这种构建的解决方案相当或者更好的方案(或者说无法在可行的时间内实现)。
深度残差学习框架来解决这个退化问题。我们明确的让某些层来拟合残差映射(residual mapping),而不是让每一个堆叠的层直接来拟合所需的底层映射(desired underlying mapping)。
假设所需的底层映射为H(x),我们让堆叠的非线性层来拟合另一个映射:F(x):=H(x)−x。 因此原来的映射转化为: F(x)+x。我们推断残差映射比原始未参考的映射(unreferenced mapping)更容易优化。在极端的情况下,如果某个恒等映射是最优的,那么将残差变为0 比用非线性层的堆叠来拟合恒等映射更简单。

公式 F(x)+x 可以通过前馈神经网络的“shortcut连接”来实现。Shortcut连接就是跳过一个或者多个层。
Layer Normalization
参考 https://zhuanlan.zhihu.com/p/54530247 很清晰
一层的权值 w 的梯度高度依赖于前一层神经元的输出,梯度容易受样本数据的影响,导致权值难以快速的收敛( covariate shift 现象)。那么我们可以通过固定一层神经元的输入均值和方差来降低 covariate shift 的影响。
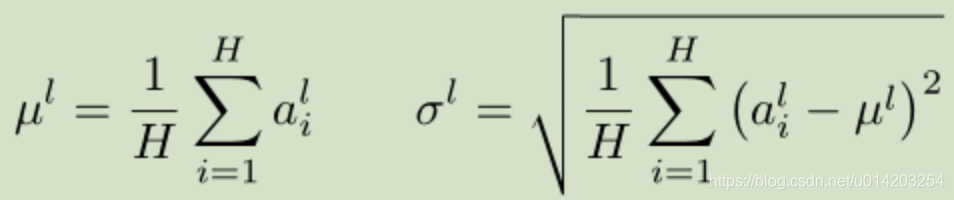
上面公式中 H 是 一层神经元的个数。这里一层网络 共享一个均值和方差,不同训练样本对应不同的均值和方差,这是和 Batch normalization 的最大区别。
参考文献:
- Attention Is All You Need https://arxiv.org/abs/1706.03762
- http://www.likecs.com/show-59320.html
- https://blog.csdn.net/yujianmin1990/article/details/85221271
- https://www.cnblogs.com/robert-dlut/p/8638283.html
- https://www.cnblogs.com/ydcode/p/11038064.html
- https://www.tensorflow.org/tutorials/text/nmt_with_attention#%E7%BC%96%E5%86%99%E7%BC%96%E7%A0%81%E5%99%A8_%EF%BC%88encoder%EF%BC%89_%E5%92%8C%E8%A7%A3%E7%A0%81%E5%99%A8_%EF%BC%88decoder%EF%BC%89_%E6%A8%A1%E5%9E%8B

















 1146
1146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









