







Raw sockets provide three features not provided by normal TCP and UDP sockets:
- Raw sockets let us read and write ICMPv4, IGMPv4, and ICMPv6 packets.
- With a raw socket, a process can read and write IPv4 datagrams with an IPV4 protocol field that is not processed by the kernel.Most kernels only process datagrams containing values of 1 (ICMP), 2 (IGMP), 6 (TCP), and 17 (UDP). For example. The gated program that implements OSPF must use a raw socket to read and write these IP datagrams since they contain a protocol field the kernel knows nothing about. This capability carries over to IPv6 also.
- With a raw socket, a process can build its own IPv4 header using the IP_HDRINCL socket option. This can be used, for example, to build UDP and TCP packets
The steps involved in creating a raw socket are as follows:
- The socket function creates a raw socket when the second argument is SOCK_RAW. The third argument (the protocol) is normally nonzero. For example, to create an
IPv4 raw socket we would write
int sockfd; sockfd = socket(AF_INET, SOCK_RAW, protocol); // where protocol is one of the constants, IPPROTO_xxx, defined by including the <netinet/in.h> header, such as IPPROTO_ICMP.
Only the superuser can create a raw socket. This prevents normal users from writing their own IP datagrams to the network. - The IP_HDRINCL socket option can be set as follows:
const int on = 1; if (setsockopt(sockfd, IPPROTO_IP, IP_HDRINCL, &on, sizeof(on)) < 0) error - bind can be called on the raw socket, but this is rare. This function sets only the local address: There is no concept of a port number with a raw socket. With regard
to output, calling bind sets the source IP address that will be used for datagrams sent on the raw socket (but only if the IP_HDRINCL socket option is not set). If bind
is not called, the kernel sets the source IP address to the primary IP address of the outgoing interface.
- connect can be called on the raw socket, but this is rare. This function sets only the foreign address: Again, there is no concept of a port number with a raw socket. With
regard to output, calling connect lets us call write or send instead of sendto, since the destination IP address is already specified.
Output on a raw socket is governed by the following rules:
- Normal output is performed by calling sendto or sendmsg and specifying the destination IP address. write, writev, or send can also be called if the socket has
been connected. - If the IP_HDRINCL option is not set, the starting address of the data for the kernel to send specifies the first byte following the IP header because the kernel will build the
IP header and prepend it to the data from the process. The kernel sets the protocol field of the IPv4 header that it builds to the third argument from the call to socket. - If the IP_HDRINCL option is set, the starting address of the data for the kernel to send specifies the first byte of the IP header. The amount of data to write must
include the size of the caller's IP header. The process builds the entire IP header, except: (i) the IPv4 identification field can be set to 0, which tells the kernel to set
this value; (ii) the kernel always calculates and stores the IPv4 header checksum; and (iii) IP options may or may not be included; - The kernel fragments raw packets that exceed the outgoing interface MTU.
On Linux and OpenBSD, however, all the fields must be in network byte order.
With IPv4, it is the responsibility of the user process to calculate and set any header checksums contained in whatever follows the IPv4 header.
There are a few differences with raw IPv6 sockets
- All fields in the protocol headers sent or received on a raw IPv6 socket are in network byte order.
- There is nothing similar to the IPv4 IP_HDRINCL socket option with IPv6. Complete IPv6 packets (including the IPv6 header or extension headers) cannot be read or
written on an IPv6 raw socket. Almost all fields in an IPv6 header and all extension headers are available to the application through socket options or ancillary data
. Should an application need to read or write complete IPv6 datagrams, datalink access must be used. - Checksums on raw IPv6 sockets are handled differently.
IPV6_CHECKSUM Socket Option
For an ICMPv6 raw socket, the kernel always calculates and stores the checksum in the ICMPv6 header. This differs from an ICMPv4 raw socket, where the application must do this itself While ICMPv4 and ICMPv6 both require the sender to calculate the checksum, ICMPv6 includes a pseudoheader in its checksum One of the fields in this pseudoheader is the source IPv6 address, and normally the application lets the kernel choose this value. To prevent the application from having to try to choose this address just to calculate the checksum, it is easier to let the kernel calculate the checksum. For other raw IPv6 sockets (i.e., those created with a third argument to socket other than
IPPROTO_ICMPV6), a socket option tells the kernel whether to calculate and store a checksum in outgoing packets and verify the checksum in received packets. By default,
this option is disabled, and it is enabled by setting the option value to a nonnegative value, as in
int offset = 2;
if (setsockopt(sockfd, IPPROTO_IPV6, IPV6_CHECKSUM,
&offset, sizeof(offset)) < 0)
errorThis not only enables checksums on this socket, it also tells the kernel the byte offset of the 16-bit checksum: 2 bytes from the start of the application data in this example. To
disable the option, it must be set to -1. When enabled, the kernel will calculate and store the checksum for outgoing packets sent on the socket and also verify the checksums for packets received on the socket.
Raw Socket Input
The following rules apply:
- Received UDP packets and received TCP packets are never passed to a raw socket. If a process wants to read IP datagrams containing UDP or TCP packets, the packets must be read at the datalink layer
- Most ICMP packets are passed to a raw socket after the kernel has finished processing the ICMP message.
- All IGMP packets are passed to a raw socket after the kernel has finished processing the IGMP message.
- All IP datagrams with a protocol field that the kernel does not understand are passed to a raw socket. The only kernel processing done on these packets is the
minimal verification of some IP header fields: the IP version, IPv4 header checksum, header length, and destination IP address - If the datagram arrives in fragments, nothing is passed to a raw socket until all fragments have arrived and have been reassembled.
When the kernel has an IP datagram to pass to the raw sockets, all raw sockets for all processes are examined, looking for all matching sockets.The following tests are performed for each raw socket and only if all three tests are true is the datagram delivered to the socket:
- If a nonzero protocol is specified when the raw socket is created (the third argument to socket), then the received datagram's protocol field must match this value.
- If a local IP address is bound to the raw socket by bind, then the destination IP address of the received datagram must match this bound address.
- If a foreign IP address was specified for the raw socket by connect, then the source IP address of the received datagram must match this connected address.
Notice that if a raw socket is created with a protocol of 0, and neither bind nor connect is called, then that socket receives a copy of every raw datagram the kernel passes to raw
sockets.
Whenever a received datagram is passed to a raw IPv4 socket, the entire datagram, including the IP header, is passed to the process. For a raw IPv6 socket, only the payload
(i.e., no IPv6 header or any extension headers) is passed to the socket
In the IPv4 header passed to the application, Under Linux, all fields are left in network byte order.
ICMPv6 Type Filtering
ICMPv6
is a superset of ICMPv4, including the functionality of ARP and IGMP. To reduce the number of packets passed from the kernel to the application across a raw
ICMPv6 socket, an application-specified filter is provided. A filter is declared with a datatype of struct icmp6_filter
#include <netinet/icmp6.h>
void ICMP6_FILTER_SETPASSALL (struct icmp6_filter *filt);
void ICMP6_FILTER_SETBLOCKALL (struct icmp6_filter *filt);
void ICMP6_FILTER_SETPASS (int msgtype, struct icmp6_filter *filt);
void ICMP6_FILTER_SETBLOCK (int msgtype, struct icmp6_filter *filt);
int ICMP6_FILTER_WILLPASS (int msgtype, const struct icmp6_filter *filt);
int ICMP6_FILTER_WILLBLOCK (int msgtype, const struct icmp6_filter *filt);
Both return: 1 if filter will pass (block) message type, 0 otherwise
The SETPASSALL macro specifies that all message types are to be passed to the application, while the SETBLOCKALL macros specifies that no message types are to be passed. The SETPASS macro enables one specific message type to be passed to the application while the SETBLOCK macro blocks one specific message type. The WILLPASS macro returns 1 if the specified message type is passed by the filter, or 0 otherwise; the WILLBLOCK macro returns 1 if the specified message type is blocked by the filter, or 0 otherwise.
struct icmp6_filter myfilt;
fd = socket (AF_INET6, SOCK_RAW, IPPROTO_ICMPV6);
ICMP6_FILTER_SETBLOCKALL (&myfilt);
ICMP6_FILTER_SETPASS (ND_ROUTER_ADVERT, &myfilt);
Setsockopt (fd, IPPROTO_ICMPV6, ICMP6_FILTER. &myfilt, sizeof (myfilt));ping Program
The operation of ping is extremely simple: An ICMP echo request is sent to some IP address and that node responds with an ICMP echo reply.
Format of ICMPv4 and ICMPv6 echo request and echo reply messages

The program operates in two parts: One half reads everything received on a raw socket, printing the ICMP echo replies, and the other half sends an ICMP echo request once per second. The second half is driven by a SIGALRM signal once per second.
we set the identifier to the PID of the ping process and we increment the sequence number by one for each packet we send. We store the 8-byte timestamp of when the packet is sent as the optional data.
We set the amount of optional data that gets sent with the ICMP echo request to 56 bytes. This will yield an 84-byte IPv4 datagram (20-byte IPv4 header and 8-byte ICMP
header) or a 104-byte IPv6 datagram. Any data that accompanies an echo request must be sent back in the echo reply. We will store the time at which we send an echo request in the first 8 bytes of this data area and then use this to calculate and print the RTT when the echo reply is received.
The IPv4 header length field is multiplied by 4, giving the size of the IPv4 header in bytes. (Remember that an IPv4 header can contain options.) This lets us set icmp to point
to the beginning of the ICMP header. We make sure that the IP protocol is ICMP and that there is enough data echoed to look at the timestamp we included in the echo request.

#include <signal.h>
#include <sys/time.h>
#include <netinet/ip_icmp.h>
#include <arpa/inet.h>
#include <netdb.h>
#include <iostream>
#include <cerrno>
#include <cstdlib>
#include <string.h>
using namespace std;
typedef void (*sign_handle)( int sign );
const int BUFSIZE = 1500;
char sendbuf[ BUFSIZE ];
int datalen = 56;
int nsend;
int sockfd;
pid_t pid;
struct sockaddr *sasend;
socklen_t salen;
struct sockaddr *sarecv;
char *sock_ntop_host( struct sockaddr *sa, socklen_t salen)
{
static char str[ 128 ];
struct sockaddr_in *sin = (struct sockaddr_in *) sa;
if ( inet_ntop( AF_INET, &sin->sin_addr, str, sizeof( str ) ) == 0 )
{
cout << "sock_ntop_host error" << endl;
exit( 1 );
}
return str;
}
void tv_sub( struct timeval *out, struct timeval *in )
{
if ( ( out->tv_usec -= in->tv_usec ) < 0 )
{
--out->tv_sec;
out->tv_usec += 1000000;
}
out->tv_sec -= in->tv_sec;
}
void proc_v4( char *ptr, ssize_t len, struct msghdr *msg, struct timeval *tvrecv )
{
struct ip *ip = (struct ip*) ptr;
if ( ip->ip_p != IPPROTO_ICMP )
{
return;
}
int hlenl = ip->ip_hl << 2;
struct icmp *icmp = (struct icmp*)( ptr + hlenl );
int icmplen = len - hlenl;
if ( icmplen < 8 )
{
return;
}
if ( icmp->icmp_type == ICMP_ECHOREPLY )
{
if ( icmp->icmp_id != pid )
{
return;
}
if ( icmplen < 16 )
{
return;
}
struct timeval *tvsend = (struct timeval *)icmp->icmp_data;
tv_sub( tvrecv, tvsend );
double rtt = tvrecv->tv_sec * 1000.0 + tvrecv->tv_usec / 1000.0;
cout << icmplen << " bytes form " << sock_ntop_host( sarecv, salen ) << " : seq = " << icmp->icmp_seq;
cout << ", ttl = " << ip->ip_ttl << ", rtt = " << rtt << " ms" << endl;
}
}
uint16_t in_cksum( uint16_t *addr, int len )
{
int nleft = len;
uint32_t sum = 0;
uint16_t *w = addr;
uint16_t answer = 0;
while ( nleft > 1 )
{
sum += *w++;
nleft -= 2;
}
if ( nleft == 1 )
{
*(unsigned char*)( &answer ) = *(unsigned char*)w;
sum += answer;
}
sum = ( sum >> 16 ) + ( sum & 0xffff );
sum += ( sum >> 16 );
answer = ~sum;
return answer;
}
void sig_alrm( int signo )
{
struct icmp *icmp = (struct icmp *)sendbuf;
icmp->icmp_type = ICMP_ECHO;
icmp->icmp_code = 0;
icmp->icmp_id = pid;
icmp->icmp_seq = nsend++;
memset( icmp->icmp_data, 0xa5, datalen );
gettimeofday( (struct timeval*)icmp->icmp_data, 0 );
int len = 8 + datalen;
icmp->icmp_cksum = 0;
icmp->icmp_cksum = in_cksum( (u_short*)icmp, len );
sendto( sockfd, sendbuf, len, 0, sasend, salen );
alarm( 1 );
}
int main( int argc, char *argv[] )
{
if ( 2 != argc )
{
cout << "usage : ping <ipaddr>" << endl;
exit( 1 );
}
struct sigaction act;
act.sa_handler = sig_alrm;
act.sa_flags = 0;
sigemptyset( &act.sa_mask );
sigaction( SIGALRM, &act, 0 );
pid = getpid() & 0xffff;
struct addrinfo hints;
bzero( &hints, sizeof ( struct addrinfo ) );
hints.ai_flags = AI_CANONNAME;
hints.ai_family = 0;
hints.ai_socktype = 0;
struct addrinfo *ai = 0;
const char *host = argv[ 1 ];
if ( 0 != getaddrinfo( host, 0, &hints, &ai ) )
{
cout << "error: getaddrinfo" << endl;
exit( 1 );
}
if ( AF_INET != ai->ai_family )
{
cout << "not ipv4" << endl;
exit( 1 );
}
char *h = sock_ntop_host( ai->ai_addr, ai->ai_addrlen );
cout << "ping " << ( ai->ai_canonname ? ai->ai_canonname : h ) << "( " << h << " ) " << datalen << " data bytes" << endl;
sasend = ai->ai_addr;
sarecv = ( struct sockaddr* )calloc( 1, ai->ai_addrlen );
salen = ai->ai_addrlen;
sockfd = socket( AF_INET, SOCK_RAW, IPPROTO_ICMP );
setuid( getuid() );
int size = 60 * 1024;
setsockopt( sockfd, SOL_SOCKET, SO_RCVBUF, &size, sizeof( size ) );
sig_alrm( SIGALRM );
char recvbuf[ BUFSIZE ];
char controlbuf[ BUFSIZE ];
struct iovec iov;
iov.iov_base = recvbuf;
iov.iov_len = sizeof( recvbuf );
struct msghdr msg;
msg.msg_name = sarecv;
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
msg.msg_control = controlbuf;
while ( 1 )
{
msg.msg_namelen = salen;
msg.msg_controllen = sizeof( controlbuf );
int n = recvmsg( sockfd, &msg, 0 );
if ( n < 0 )
{
if ( EINTR == errno )
{
continue;
}
else
{
cout << "recvmsg error" << endl;
exit( 0 );
}
}
struct timeval tval;
gettimeofday( &tval, 0 );
proc_v4( recvbuf, n, &msg, &tval );
}
return 0;
}
traceroute
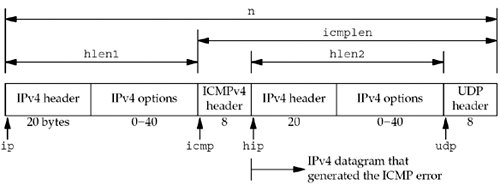
traceroute uses the IPv4 TTL field and two ICMP messages. It starts by sending a UDP datagram to the destination with a TTL (or hop limit) of 1. This datagram causes the first-hop router to return an ICMP "time exceeded in transit" error. The TTL is then increased by one and another UDP datagram is sent, which locates the next router in the path. When the UDP datagram reaches the final destination, the goal is to have that host return an ICMP "port unreachable" error. This is done by sending the UDP datagram to a random port that is (hopefully) not in use on that host.
#include <signal.h>
#include <sys/time.h>
#include <netinet/ip_icmp.h>
#include <arpa/inet.h>
#include <netdb.h>
#include <iostream>
#include <cerrno>
#include <cstdlib>
#include <string.h>
#include <netinet/udp.h>
using namespace std;
struct sockaddr *sarecv = 0;
int salen = 0;
int recvfd = 0;
int sport = 0;
int dport = 32768 + 666;
char recvbuf[ 1500 ];
struct rec
{
u_short rec_seq;
u_short rec_ttl;
struct timeval rec_tv;
};
char *sock_ntop_host( struct sockaddr *sa, socklen_t salen)
{
static char str[ 128 ];
struct sockaddr_in *sin = (struct sockaddr_in *) sa;
if ( inet_ntop( AF_INET, &sin->sin_addr, str, sizeof( str ) ) == 0 )
{
cout << "sock_ntop_host error" << endl;
exit( 1 );
}
return str;
}
int gotalarm;
void sig_alrm( int signo )
{
gotalarm = 1;
}
int recv( int seq, struct timeval *tv )
{
int ret = 0;
gotalarm = 0;
alarm( 3 );
while ( 1 )
{
if ( gotalarm )
{
return -3;
}
socklen_t len = salen;
int n = recvfrom( recvfd, recvbuf, sizeof( recvbuf ), 0, sarecv, &len );
if ( n < 0 )
{
if ( EINTR == errno )
{
continue;
}
cout << "recvfrom error" << endl;
exit( 1 );
}
struct ip *ip = (struct ip*) recvbuf;
if ( ip->ip_p != IPPROTO_ICMP )
{
continue;
}
int hlen1 = ip->ip_hl << 2;
struct icmp *icmp = (struct icmp*)( recvbuf + hlen1 );
int icmplen = n - hlen1;
if ( icmplen < 8 )
{
continue;
}
if ( ICMP_TIMXCEED == icmp->icmp_type && ICMP_TIMXCEED_INTRANS == icmp->icmp_code )
{
if ( icmplen < 8 + sizeof( struct ip ) )
{
continue;
}
struct ip *hip = (struct ip*)( recvbuf + hlen1 + 8 );
int hlen2 = hip->ip_hl << 2;
if ( icmplen < 8 + hlen2 + 4 )
{
continue;
}
struct udphdr* udp = (struct udphdr*)( recvbuf + hlen1 + 8 + hlen2 );
if ( IPPROTO_UDP == hip->ip_p && htons( sport ) == udp->source && htons( dport + seq ) == udp->dest )
{
ret = -2;
break;
}
}
else if ( ICMP_UNREACH == icmp->icmp_type )
{
if ( icmplen < 8 + sizeof( struct ip ) )
{
continue;
}
struct ip *hip = (struct ip*)( recvbuf + hlen1 + 8 );
int hlen2 = hip->ip_hl << 2;
if ( icmplen < 8 + hlen2 + 4 )
{
continue;
}
struct udphdr* udp = (struct udphdr*)( recvbuf + hlen1 + 8 + hlen2 );
if ( IPPROTO_UDP == hip->ip_p && htons( sport ) == udp->source && htons( dport + seq ) == udp->dest )
{
if ( ICMP_UNREACH_PORT == icmp->icmp_code )
{
ret = -1;
}
else
{
ret = icmp->icmp_code;
}
break;
}
}
} // while
alarm( 0 );
gettimeofday( tv, 0 );
return ret;
}
void tv_sub( struct timeval *out, struct timeval *in )
{
if ( ( out->tv_usec -= in->tv_usec ) < 0 )
{
--out->tv_sec;
out->tv_usec += 1000000;
}
out->tv_sec -= in->tv_sec;
}
int main( int argc, char *argv[] )
{
if ( 2 != argc )
{
cout << "usage : ping <ipaddr>" << endl;
exit( 1 );
}
struct sigaction act;
act.sa_handler = sig_alrm;
act.sa_flags = 0;
sigemptyset( &act.sa_mask );
sigaction( SIGALRM, &act, 0 );
struct addrinfo hints;
bzero( &hints, sizeof ( struct addrinfo ) );
hints.ai_flags = AI_CANONNAME;
hints.ai_family = 0;
hints.ai_socktype = 0;
struct addrinfo *ai = 0;
const char *host = argv[ 1 ];
if ( 0 != getaddrinfo( host, 0, &hints, &ai ) )
{
cout << "error: getaddrinfo" << endl;
exit( 1 );
}
if ( AF_INET != ai->ai_family )
{
cout << "not ipv4" << endl;
exit( 1 );
}
char *h = sock_ntop_host( ai->ai_addr, ai->ai_addrlen );
cout << "traceroute to " << ( ai->ai_canonname ? ai->ai_canonname : h ) << "( " << h << " ): 30 hops max, 24 data bytes" << endl;
struct sockaddr *sasend = ai->ai_addr;
salen = ai->ai_addrlen;
recvfd = socket( AF_INET, SOCK_RAW, IPPROTO_ICMP );
setuid( getuid() );
int sendfd = socket( AF_INET, SOCK_DGRAM, 0 );
sport = getpid() & 0xffff | 0x8000;
sarecv = (struct sockaddr*)calloc ( 1, salen );
struct sockaddr_in *sabind = (struct sockaddr_in*)calloc ( 1, salen );
sabind->sin_port = htons( sport );
bind( sendfd, (struct sockaddr*)sabind, salen );
sig_alrm( SIGALRM );
char *sendbuf = new char[ 1500 ];
int seq = 0;
int datalen = sizeof( struct rec );
struct timeval tvrecv;
int done = 0;
for ( int ttl = 1; ttl < 30 && 0 == done; ++ttl )
{
setsockopt( sendfd, IPPROTO_IP, IP_TTL, &ttl, sizeof( int ) );
cout << ttl << endl;
for ( int probe = 0; probe < 3; ++probe )
{
struct rec *rec = (struct rec*)sendbuf;
rec->rec_seq = ++seq;
rec->rec_ttl = ttl;
gettimeofday( &rec->rec_tv, 0 );
( (struct sockaddr_in*)sasend )->sin_port = htons( dport + seq );
sendto( sendfd, sendbuf, datalen, 0, sasend, salen );
int code = recv( seq, &tvrecv );
if ( -3 == code )
{
cout << " *";
}
else
{
if ( AF_INET == sarecv->sa_family )
{
char str[ 256 ];
int a = getnameinfo( sarecv, salen, str, sizeof( str ), 0, 0, 0 );
if ( 0 == a )
{
cout << " " << str << " ( " << sock_ntop_host( sarecv, salen ) << " ) ";
}
else
{
cout << " " << sock_ntop_host( sarecv, salen );
}
}
tv_sub( &tvrecv, &rec->rec_tv );
double rtt = tvrecv.tv_sec * 1000.0 + tvrecv.tv_usec / 1000.0;
cout << " " << rtt << " ms";
if ( -1 == code )
{
++done;
}
}
cout << endl;
}
} // for
return 0;
}















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









