







位置:include/linux/skbuff.h
net/core/skbuff.c
总述:传输包的所有信息都保存在sk_buff结构中,这一结构被所有网络层使用。内核中,所有的sk_buff结构都被组织在一个双向链表中,见下图:
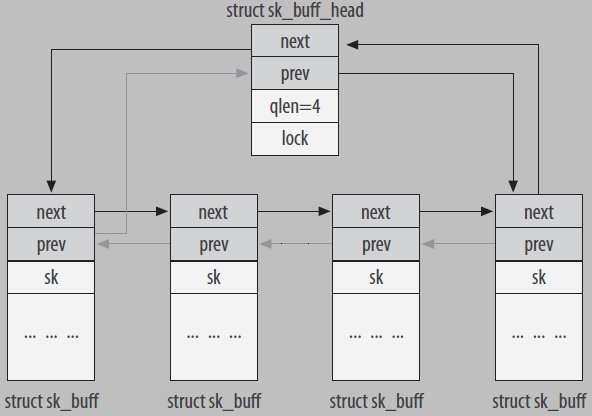
其中的sk_buff_head是链表头,定义如下:
struct sk_buff_head {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
__u32 qlen; // 链表中的元素数量(sk_buff对象的数量)
spinlock_t lock; // 访问列表时的同步锁
};
下面是struct sk_buff 的成员:
| struct sk_buff *next; struct sk_buff *prev; | 这两个和sk_buff_head的next,prev,共同构成双向列表。 |
| ktime_t tstamp; | 时间戳,包到达的时间或包开始传输时的时间 |
| struct sock *sk; | 当通过socket接口发送和接收数据时,用sk指向对应的sock结构, 当只是转发一个包,sk为空 |
| struct net_device *dev; | 指向网格设备 |
| char cb[48] __aligned(8); | This is the control buffer. It is free to use for every layer. Please put your private variables there. If you want to keep them across layers you have to do a skb_clone() first. This is owned by whoever has the skb queued ATM. 提供一个48字节的空间,可灵活使用 如 #define NAPI_GRO_CB(skb) ((struct napi_gro_cb *)(skb)->cb) |
| unsigned long _skb_refdst; | |
| #ifdef CONFIG_XFRM struct sec_path *sp; #endif | |
| unsigned int len; | 为数据的总长度。包括分片的长度。 |
| unsigned int data_len; | 只包括分片的长度 |
| __u16 mac_len; | MAC头的长度 |
| __u16 hdr_len; | |
| union { __wsum csum; struct { __u16 csum_start; __u16 csum_offset; }; }; | |
| __u32 priority; | |
| __u8 local_df:1, | |
| __u8 cloned:1; | |
| __u8 ip_summed:2; | |
| __u8 nohdr:1; | |
| __u8 nfctinfo:3; | |
| __u8 pkt_type:3; | pkt_type为包的类型(链路层),如下: PACKET_HOST 包的目的地址就是本机 PACKET_BROADCAST 包的目的地址是广播地址 PACKET_MULTICAST 包的目的地址多播地址 PACKET_OTHERHOST 包的目的地址不是本机,包被转发或丢弃 PACKET_OUTGOING 包将要被发送 PACKET_LOOPBACK 包被发送到环回接口 PACKET_USER 包被发送到用户空间 PACKET_KERNEL 包被发送到内核空间 |
| __u8 fclone:2; | 当skb_buff被clone时,标识两个对象的状态: enum { SKB_FCLONE_UNAVAILABLE, SKB_FCLONE_ORIG, SKB_FCLONE_CLONE, }; |
| __u8 ipvs_property:1; | |
| __u8 peeked:1; | |
| __u8 nf_trace:1; | |
| __be16 protocol; | 网络层的协议(IP,ARP) |
| void (*destructor)(struct sk_buff *skb); | 当sk_buff被删除时执行的函数,可为空 |
| #if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE) struct nf_conntrack *nfct; #endif | |
| #ifdef CONFIG_BRIDGE_NETFILTER struct nf_bridge_info *nf_bridge; #endif | |
| int skb_iif; | 接收数据的设备编号 |
| __u32 rxhash; | |
| __be16 vlan_proto; | |
| __u16 vlan_tci; | |
| #ifdef CONFIG_NET_SCHED __u16 tc_index; /* traffic control index */ #ifdef CONFIG_NET_CLS_ACT __u16 tc_verd; /* traffic control verdict */ #endif #endif | |
| __u16 queue_mapping; | |
| #ifdef CONFIG_IPV6_NDISC_NODETYPE __u8 ndisc_nodetype:2; #endif | |
| __u8 pfmemalloc:1; | |
| __u8 ooo_okay:1; | |
| __u8 l4_rxhash:1; | |
| __u8 wifi_acked_valid:1; | |
| __u8 wifi_acked:1; | |
| __u8 no_fcs:1; | |
| __u8 head_frag:1; | 分配的buffer大小由用户指定,为true |
| __u8 encapsulation:1; | |
| #if defined CONFIG_NET_DMA || defined CONFIG_NET_RX_BUSY_POLL union { unsigned int napi_id; dma_cookie_t dma_cookie; }; #endif | |
| #ifdef CONFIG_NETWORK_SECMARK __u32 secmark; #endif | |
| union { __u32 mark; __u32 dropcount; __u32 reserved_tailroom; }; | |
| __be16 inner_protocol; | |
| __u16 inner_transport_header; | |
| __u16 inner_network_header; | |
| __u16 inner_mac_header; | |
| __u16 transport_header; | 传输层头部(TCP/UDP)偏移 |
| __u16 network_header; | IP头部偏移 |
| __u16 mac_header; | MAC头部偏移 |
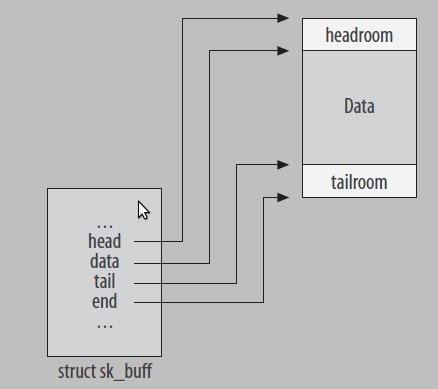
| sk_buff_data_t tail; | 指向buffer的数据的末尾 |
| sk_buff_data_t end; | 指向buffer的末尾 |
| unsigned char *head; | 指向buffer的开始位置 |
| unsigned char *data; | 指向buffer的数据的开始位置 |
| unsigned int truesize; | buffer的大小加上sk_buff的大小(包含分片) |
| atomic_t users; | 引用计数 |
为了效率,在分配buffer时,分配一个页面大小,由下面结构表示
include/linux/mm_types.h
struct page_frag {
struct page *page; // 分配的页面
#if (BITS_PER_LONG > 32) || (PAGE_SIZE >= 65536)
__u32 offset; // 数据在页面中的偏移
__u32 size; // 数据的大小
#else
__u16 offset;
__u16 size;
#endif
};
struct netdev_alloc_cache {
struct page_frag frag;
/* we maintain a pagecount bias, so that we dont dirty cache line
* containing page->_count every time we allocate a fragment.
*/
unsigned int pagecnt_bias;
};
static DEFINE_PER_CPU(struct netdev_alloc_cache, netdev_alloc_cache);在分配的缓冲的最后,会放一个skb_shared_info结构,用来存储分片等信息:
/* This data is invariant across clones and lives at
* the end of the header data, ie. at skb->end.
* GSO : Generic Segmentation Offload
*/
struct skb_shared_info {
unsigned char nr_frags;
__u8 tx_flags;
unsigned short gso_size; // 生成GSO段的MSS
/* Warning: this field is not always filled in (UFO)! */
unsigned short gso_segs; // GSO段的数量(用gso_size来分割大段时产生的段数)
unsigned short gso_type; // GSO类型
struct sk_buff *frag_list;
struct skb_shared_hwtstamps hwtstamps;
__be32 ip6_frag_id;
/*
* Warning : all fields before dataref are cleared in __alloc_skb()
*/
atomic_t dataref; // 引用计数
/* Intermediate layers must ensure that destructor_arg
* remains valid until skb destructor */
void * destructor_arg;
/* must be last field, see pskb_expand_head() */
skb_frag_t frags[MAX_SKB_FRAGS];
};
下面看如何分配skb_buff:
// 分配了一个页面
static void *__netdev_alloc_frag(unsigned int fragsz, gfp_t gfp_mask)
{
struct netdev_alloc_cache *nc;
void *data = NULL;
int order;
unsigned long flags;
/* EFLAGS寄存器的内容保存在flags中
* 禁止本地中断
*/
local_irq_save(flags);
nc = &__get_cpu_var(netdev_alloc_cache); // 得到页面CACHE,这是一个PRE_PRE变量
if (unlikely(!nc->frag.page)) { // 如果cache还没有分配页面
refill:
for (order = NETDEV_FRAG_PAGE_MAX_ORDER; ;) {
gfp_t gfp = gfp_mask;
if (order)
gfp |= __GFP_COMP | __GFP_NOWARN;
nc->frag.page = alloc_pages(gfp, order); // 分配页面
if (likely(nc->frag.page))
break;
if (--order < 0)
goto end;
}
nc->frag.size = PAGE_SIZE << order; // 页面大小
recycle:
/* nc->frag.page->_count和nc->pagecnt_bias值相同是为了提高效率(不用访问page里就可得到值)
*/
atomic_set(&nc->frag.page->_count, NETDEV_PAGECNT_MAX_BIAS);
nc->pagecnt_bias = NETDEV_PAGECNT_MAX_BIAS;
nc->frag.offset = 0; // 数据起始位置为0
}
// 空间不够,重新分配
if (nc->frag.offset + fragsz > nc->frag.size) {
/* avoid unnecessary locked operations if possible */
if ((atomic_read(&nc->frag.page->_count) == nc->pagecnt_bias) ||
atomic_sub_and_test(nc->pagecnt_bias, &nc->frag.page->_count))
goto recycle;
goto refill;
}
data = page_address(nc->frag.page) + nc->frag.offset; // 内存地址为页面地址+偏移量
nc->frag.offset += fragsz; // 页面的偏移地址加上fragsz
nc->pagecnt_bias--;
end:
local_irq_restore(flags); // 将flags入堆栈,然后出栈给EFLAGS寄存器
return data;
}
再看如何从一块内存中构建一个sk_buff:
/**
* build_skb - build a network buffer
* @data: data buffer provided by caller
* @frag_size: size of fragment, or 0 if head was kmalloced
*
* Allocate a new &sk_buff. Caller provides space holding head and
* skb_shared_info. @data must have been allocated by kmalloc() only if
* @frag_size is 0, otherwise data should come from the page allocator.
* The return is the new skb buffer.
* On a failure the return is %NULL, and @data is not freed.
* Notes :
* Before IO, driver allocates only data buffer where NIC put incoming frame
* Driver should add room at head (NET_SKB_PAD) and
* MUST add room at tail (SKB_DATA_ALIGN(skb_shared_info))
* After IO, driver calls build_skb(), to allocate sk_buff and populate it
* before giving packet to stack.
* RX rings only contains data buffers, not full skbs.
*/
struct sk_buff *build_skb(void *data, unsigned int frag_size)
{
struct skb_shared_info *shinfo;
struct sk_buff *skb;
unsigned int size = frag_size ? : ksize(data); // 如果传进来的参数为0,分配大小为整个内存空间的大小
skb = kmem_cache_alloc(skbuff_head_cache, GFP_ATOMIC);// 从缓冲中得到一个sk_buff
if (!skb)
return NULL;
/* 减去skb_shared_info的大小,并和CPU缓冲线对齐
* 这样就把skb_shared_info放在了缓冲的末尾
*/
size -= SKB_DATA_ALIGN(sizeof(struct skb_shared_info));
memset(skb, 0, offsetof(struct sk_buff, tail)); // sk_buff中tail之前的数据清0
skb->truesize = SKB_TRUESIZE(size); // truesize为缓冲大小加上sk_buff的大小
skb->head_frag = frag_size != 0; // 是否指定缓冲大小
atomic_set(&skb->users, 1); // 引用计数为1
skb->head = data; // 指向缓冲开始
skb->data = data; // 指向缓冲开始
skb_reset_tail_pointer(skb); // 数据大小为0(tail指向缓冲开始)
skb->end = skb->tail + size; // 可容纳的数据大小为缓冲大小减去skb_shared_info大小(end指向skb_shared_info开始位置)
skb->mac_header = (typeof(skb->mac_header))~0U; // MAC头部为~0U
skb->transport_header = (typeof(skb->transport_header))~0U; // 传输层头部为~0U
/* make sure we initialize shinfo sequentially */
shinfo = skb_shinfo(skb); // 指向skb_shared_info
memset(shinfo, 0, offsetof(struct skb_shared_info, dataref)); // skb_shared_info中dataref之前数据清0
atomic_set(&shinfo->dataref, 1); // 引用计数为1
kmemcheck_annotate_variable(shinfo->destructor_arg);
return skb;
}
EXPORT_SYMBOL(build_skb);
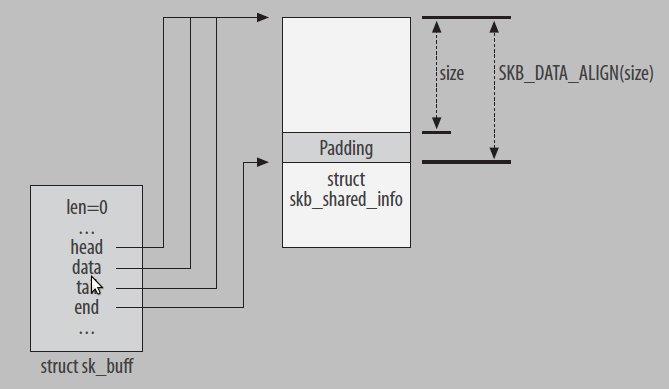
下面看__alloc_skb:
/**
* __alloc_skb - allocate a network buffer
* @size: size to allocate
* @gfp_mask: allocation mask
* @flags: If SKB_ALLOC_FCLONE is set, allocate from fclone cache
* instead of head cache and allocate a cloned (child) skb.
* If SKB_ALLOC_RX is set, __GFP_MEMALLOC will be used for
* allocations in case the data is required for writeback
* @node: numa node to allocate memory on
*
* Allocate a new &sk_buff. The returned buffer has no headroom and a
* tail room of at least size bytes. The object has a reference count
* of one. The return is the buffer. On a failure the return is %NULL.
*
* Buffers may only be allocated from interrupts using a @gfp_mask of
* %GFP_ATOMIC.
*/
struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask,
int flags, int node)
{
struct kmem_cache *cache;
struct skb_shared_info *shinfo;
struct sk_buff *skb;
u8 *data;
bool pfmemalloc;
/* 选择缓冲
* skbuff_head_cache缓冲区里的对象是一个sk_buff对象
* skbuff_fclone_cache缓冲区里的对象是2个sk_buff对象加一个atomic_t类型的引用计数
*/
cache = (flags & SKB_ALLOC_FCLONE)
? skbuff_fclone_cache : skbuff_head_cache;
if (sk_memalloc_socks() && (flags & SKB_ALLOC_RX))
gfp_mask |= __GFP_MEMALLOC;
/* Get the HEAD */
skb = kmem_cache_alloc_node(cache, gfp_mask & ~__GFP_DMA, node); // 从缓冲中得到sk_buff
if (!skb)
goto out;
prefetchw(skb); // 对skb地址进行一下预读,提高效率
/* We do our best to align skb_shared_info on a separate cache
* line. It usually works because kmalloc(X > SMP_CACHE_BYTES) gives
* aligned memory blocks, unless SLUB/SLAB debug is enabled.
* Both skb->head and skb_shared_info are cache line aligned.
*/
size = SKB_DATA_ALIGN(size); // 与CPU缓冲线对齐
size += SKB_DATA_ALIGN(sizeof(struct skb_shared_info)); // 分配大小加上skb_shared_info的大小(与CPU缓冲线对齐)
data = kmalloc_reserve(size, gfp_mask, node, &pfmemalloc); // 分配内存
if (!data)
goto nodata;
/* kmalloc(size) might give us more room than requested.
* Put skb_shared_info exactly at the end of allocated zone,
* to allow max possible filling before reallocation.
*/
size = SKB_WITH_OVERHEAD(ksize(data)); // size为实际分配的大小减去skb_shared_info的大小
prefetchw(data + size); // 对skb_shared_info开始位置的地址进行预读
/*
* Only clear those fields we need to clear, not those that we will
* actually initialise below. Hence, don't put any more fields after
* the tail pointer in struct sk_buff!
*/
memset(skb, 0, offsetof(struct sk_buff, tail));
/* Account for allocated memory : skb + skb->head */
skb->truesize = SKB_TRUESIZE(size); // truesize为缓冲大小加上sk_buff的大小
skb->pfmemalloc = pfmemalloc;
atomic_set(&skb->users, 1); // 引用计数为1
skb->head = data; // 指向缓冲开始
skb->data = data; // 指向缓冲开始
skb_reset_tail_pointer(skb); // 数据大小为0(tail指向缓冲开始)
skb->end = skb->tail + size; // 可容纳的数据大小为缓冲大小减去skb_shared_info大小(end指向skb_shared_info开始位置)
skb->mac_header = (typeof(skb->mac_header))~0U; // MAC头部为~0U
skb->transport_header = (typeof(skb->transport_header))~0U; // 传输层头部为~0U
/* make sure we initialize shinfo sequentially */
shinfo = skb_shinfo(skb); // 指向skb_shared_info
memset(shinfo, 0, offsetof(struct skb_shared_info, dataref)); // skb_shared_info中dataref之前数据清0
atomic_set(&shinfo->dataref, 1); // 引用计数为1
kmemcheck_annotate_variable(shinfo->destructor_arg);
if (flags & SKB_ALLOC_FCLONE) { // 初始化第2个sk_buff
struct sk_buff *child = skb + 1; // 得到第2个sk_buff
atomic_t *fclone_ref = (atomic_t *) (child + 1); // 得到引用计数
kmemcheck_annotate_bitfield(child, flags1);
kmemcheck_annotate_bitfield(child, flags2);
skb->fclone = SKB_FCLONE_ORIG; // 第1个设置SKB_FCLONE_ORIG标记
atomic_set(fclone_ref, 1); // 设置引用计数为1
child->fclone = SKB_FCLONE_UNAVAILABLE; // 第2个设置SKB_FCLONE_UNAVAILABLE标记
child->pfmemalloc = pfmemalloc;
}
out:
return skb;
nodata:
kmem_cache_free(cache, skb);
skb = NULL;
goto out;
}
EXPORT_SYMBOL(__alloc_skb);
/**
* __netdev_alloc_skb - allocate an skbuff for rx on a specific device
* @dev: network device to receive on
* @length: length to allocate
* @gfp_mask: get_free_pages mask, passed to alloc_skb
*
* Allocate a new &sk_buff and assign it a usage count of one. The
* buffer has unspecified headroom built in. Users should allocate
* the headroom they think they need without accounting for the
* built in space. The built in space is used for optimisations.
*
* %NULL is returned if there is no free memory.
*/
struct sk_buff *__netdev_alloc_skb(struct net_device *dev,
unsigned int length, gfp_t gfp_mask)
{
struct sk_buff *skb = NULL;
/* 分配的大小
* 加上一个偏移值NET_SKB_PAD,当头部尺寸增加时,不用重新分配缓冲
* 加上skb_shared_info的大小
* 各大小都和CPU缓冲线对齐
*/
unsigned int fragsz = SKB_DATA_ALIGN(length + NET_SKB_PAD) +
SKB_DATA_ALIGN(sizeof(struct skb_shared_info));
if (fragsz <= PAGE_SIZE && !(gfp_mask & (__GFP_WAIT | GFP_DMA))) { // 大小小于一个页面
void *data;
if (sk_memalloc_socks())
gfp_mask |= __GFP_MEMALLOC;
data = __netdev_alloc_frag(fragsz, gfp_mask);
if (likely(data)) {
skb = build_skb(data, fragsz);
if (unlikely(!skb))
put_page(virt_to_head_page(data));
}
} else {
skb = __alloc_skb(length + NET_SKB_PAD, gfp_mask, // 加上偏移NET_SKB_PAD
SKB_ALLOC_RX, NUMA_NO_NODE);
}
if (likely(skb)) {
skb_reserve(skb, NET_SKB_PAD);
skb->dev = dev;
}
return skb;
}
EXPORT_SYMBOL(__netdev_alloc_skb);
static inline struct sk_buff *__netdev_alloc_skb_ip_align(struct net_device *dev,
unsigned int length, gfp_t gfp)
{
/* 这里要加一个偏移的原因是因为以太网头部有14个字节
* 加上2字节后可以使在以太网后面的IP头部正好16位对齐,提高读取的速度。
*/
struct sk_buff *skb = __netdev_alloc_skb(dev, length + NET_IP_ALIGN, gfp); // 加一个偏移量2
if (NET_IP_ALIGN && skb)
skb_reserve(skb, NET_IP_ALIGN); // 数据开始位置偏移2(skb_data,skb_tail)
return skb;
}
static inline void native_restore_fl(unsigned long flags)
{
// 将flags入堆栈,然后出栈给EFLAGS寄存器
asm volatile("push %0 ; popf"
: /* no output */
:"g" (flags)
:"memory", "cc");
}
static inline unsigned long native_save_fl(void)
{
unsigned long flags;
/*
* "=rm" is safe here, because "pop" adjusts the stack before
* it evaluates its effective address -- this is part of the
* documented behavior of the "pop" instruction.
* 先将EFLAGS寄存器的值压入栈,然后出栈,并把值赋给flags
*/
asm volatile("# __raw_save_flags\n\t"
"pushf ; pop %0"
: "=rm" (flags)
: /* no input */
: "memory");
return flags;
}
static inline void native_irq_disable(void)
{
asm volatile("cli": : :"memory"); // 禁止本地中断
}














 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









