







The Domain Name System, or DNS, is a distributed database that is used by TCP/IP applications to map between hostnames and IP addresses, and to provide electronic mail routing information. We use the term distributed because no single site on the Internet knows all the information. Each site (university department, campus, company, or department within a company, for example) maintains its own database of information and runs a server program that other systems across the Internet (clients) can query. The DNS provides the protocol that allows clients and servers to communicate with each other.
From an application's point of view, access to the DNS is through a resolver. On Unix hosts the resolver is accessed primarily through two library functions, gethostbyname(3) and gethostbyaddr(3), which are linked with the application when the application is built. The first takes a hostname and returns an IP address, and the second takes an IP address and looks up a hostname. The resolver contacts one or more name servers to do the mapping.
The DNS name space is hierarchical, similar to the Unix filesystem.

Every node has a label of up to 63 characters. The root of the tree is a special node with a null label. Any comparison of labels considers uppercase and lowercase characters the same. The domain name of any node in the tree is the list of labels, starting at that node, working up to the root, using a period ("dot") to separate the labels. (Note that this is different from the Unix filesystem, which forms a pathname by starting at the top and going down the tree.) Every node in the tree must have a unique domain name, but the same label can be used at different points in the tree.
A domain name that ends with a period is called an absolute domain name or a fully qualified domain name (FQDN). An example is sun.tuc.noao.edu.. If the domain name does not end with a period, it is assumed that the name needs to be completed. How the name is completed depends on the DNS software being used. If the uncompleted name consists of two or more labels, it might be considered to be complete; otherwise a local addition might be added to the right of the name. For example, the name sun might be completed by adding the local suffix .tuc.noao.edu..
The top-level domains are divided into three areas:
- arpa is a special domain used for address-to-name mappings.
- The seven 3-character domains are called the generic domains( the organizational domains ).
- All the 2-character domains are based on the country codes found in ISO 3166. These are called the country domains, or the geographical domains.
A zone is a subtree of the DNS tree that is administered separately. A common zone is a second-level domain, noao.edu, for example. Many second-level domains then divide their zone into smaller zones. For example, a university might divide itself into zones based on departments, and a company might divide itself into zones based on branch offices or internal divisions.
Once the authority for a zone is delegated, it is up to the person responsible for the zone to provide multiple name servers for that zone. Whenever a new system is installed in a zone, the DNS administrator for the zone allocates a name and an IP address for the new system and enters these into the name server's database. This is where the need for delegation becomes obvious. At a small university, for example, one person could do this each time a new system was added, but in a large university the responsibility would have to be delegated (probably by departments), since one person couldn't keep up with the work.
A name server is said to have authority for one zone or multiple zones. The person responsible for a zone must provide a primary name server for that zone and one or more secondary name servers. The primary and secondaries must be independent and redundant servers so that availability of name service for the zone isn't affected by a single point of failure.
The main difference between a primary and secondary is that the primary loads all the information for the zone from disk files, while the secondaries obtain all the information from the primary. When a secondary obtains the information from its primary we call this a zone transfer.
When a new host is added to a zone, the administrator adds the appropriate information (name and IP address minimally) to a disk file on the system running the primary. The primary name server is then notified to reread its configuration files. The secondaries query the primary on a regular basis (normally every 3 hours) and if the primary contains newer data, the secondary obtains the new data using a zone transfer.
What does a name server do when it doesn't contain the information requested? It must contact another name server. (This is the distributed nature of the DNS.) Not every name server, however, knows how to contact every other name server. Instead every name server must know how to contact the root name servers. As of April 1993 there were eight root servers and all the primary servers must know the IP address of each root server. (These IP addresses are contained in the primary's configuration files. The primary servers must know the IP addresses of the root servers, not their DNS names.) The root servers then know the name and location (i.e., the IP address) of each authoritative name server for all the second-level domains. This implies an iterative process: the requesting name server must contact a root server. The root server tells the requesting server to contact another server, and so on. We'll look into this procedure with some examples later in this chapter.
A fundamental property of the DNS is caching. That is, when a name server receives information about a mapping (say, the IP address of a hostname) it caches that information so that a later query for the same mapping can use the cached result and not result in additional queries to other servers.
DNS Message Format

The message has a fixed 12-byte header followed by four variable-length fields.
The identification is set by the client and returned by the server. It lets the client match responses to requests.
The 16-bit flags field is divided into numerous pieces,

We'll start at the leftmost bit and describe each field.
- QR is a 1-bit field: 0 means the message is a query, 1 means it's a response.
- opcode is a 4-bit field. The normal value is 0 (a standard query). Other values are 1 (an inverse query) and 2 (server status request).
- AA is a 1-bit flag that means "authoritative answer." The name server is authoritative for the domain in the question section.
- TC is a 1-bit field that means "truncated." With UDP this means the total size of the reply exceeded 512 bytes, and only the first 512 bytes of the reply was returned.
- RD is a 1-bit field that means "recursion desired." This bit can be set in a query and is then returned in the response. This flag tells the name server to handle the query itself, called a recursive query. If the bit is not set, and the requested name server doesn't have an authoritative answer, the requested name server returns a list of other name servers to contact for the answer. This is called an iterative query. We'll see examples of both types of queries in later examples.
- RA is a 1-bit field that means "recursion available." This bit is set to 1 in the response if the server supports recursion. We'll see in our examples that most name servers provide recursion, except for some root servers.
- There is a 3-bit field that must be 0.
- rcode is a 4-bit field with the return code. The common values are 0 (no error) and 3 (name error). A name error is returned only from an authoritative name server and means the domain name specified in the query does not exist.
The next four 16-bit fields specify the number of entries in the four variable-length fields that complete the record. For a query, the number of questions is normally 1 and the other three counts are 0. Similarly, for a reply the number of answers is at least 1, and the remaining two counts can be 0 or nonzero.
Question Portion of DNS Query Message

The query name is the name being looked up. It is a sequence of one or more labels. Each label begins with a 1-byte count that specifies the number of bytes that follow. The name is terminated with a byte of 0, which is a label with a length of 0, which is the label of the root. Each count byte must be in the range of 0 to 63, since labels are limited. to 63 bytes. (We'll see later in this section that a count byte with the two high-order bits turned on, values 192 to 255, is used with a compression scheme.) Unlike many other message formats that we've encountered, this field is allowed to end on a boundary other than a 32-bit boundary. No padding is used. Figure 14.6 shows how the domain name gemini.tuc.noao.edu is stored.

Each question has a query type and each response (called a resource record, which we talk about below) has a type. There are about 20 different values, some of which are now obsolete, for example:
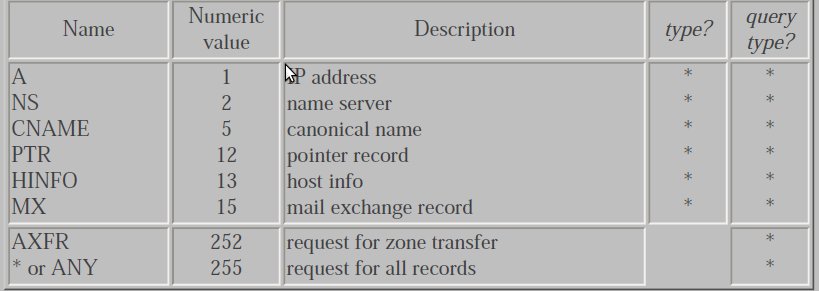
The most common query type is an A type, which means an IP address is desired for the query name. A PTR query requests the names corresponding to an IP address.
The final three fields in the DNS message, the answers, authority, and additional information fields, share a common format called a resource record or RR.

The domain name is the name to which the following resource data corresponds. It is in the same format as we described earlier for the query name field
The type specifies one of the RR type codes. These are the same as the query type values that we described earlier. The class is normally 1 for Internet data.
The time-to-live field is the number of seconds that the RR can be cached by the client. RRs often have a TTL of 2 days.
The resource data length specifies the amount of resource data. The format of this data depends on the type. For a type of 1 (an A record) the resource data is a 4-byte IP address.
Pointer Queries
A perpetual stumbling block in understanding the DNS is how pointer queries are handled - given an IP address, return the name (or names) corresponding to that address.
Examine the arpa top-level domain, and the in-addr domain beneath it. When an organization joins the Internet and obtains authority for a portion of the DNS name space, such as noao.edu, they also obtain authority for a portion of the in-addr.arpa name space corresponding to their IP address on the Internet. In the case of noao.edu it is the class B network ID 140.252. The level of the DNS tree beneath inaddr. arpa must be the first byte of the IP address (140 in this example), the next level is the next byte of the IP address (252), and so on. But remember that names are written starting at the bottom of the DNS tree, working upward. This means the DNS name for the host sun, with an IP address of 140.252.13.33, is 33.13.252.140. in-addr.arpa.
We have to write the 4 bytes of the IP address backward because authority is delegated based on network IDs: the first byte of a class A address, the first and second bytes of a class B address, and the first, second, and third bytes of a class C address. The first byte of the IP address must be immediately below the in-addr label, but FQDNs are written from the bottom of the tree up. If FQDNs were written from the top down, then the DNS name for the IP address would be arpa.in-addr.140.252.13.33, but the FQDN for the host would be edu.noao.tuc.sun.
If there was not a separate branch of the DNS tree for handling this address-to-name translation, there would be no way to do the reverse translation other than starting at the root of the tree and trying every top-level domain. This could literally take days or weeks, given the current size of the Internet. The in-addr.arpa solution is a clever one, although the reversed bytes of the IP address and the special domain are confusing.
Having to worry about the in-addr.arpa domain and reversing the bytes of the IP address affects us only if we're dealing directly with the DNS, using a program such as host, or watching the packets with tcpdump. From an application's point of view, the normal resolver function (gethostbyaddr) takes an IP address and returns information about the host. The reversal of the bytes and appending the domain in-addr.arpa are done automatically by this resolver function.
Hostname Spoofing Check
When an IP datagram arrives at a host for a server, be it a UDP datagram or a TCP connection request segment, all that's available to the server process is the client's IP address and port number (UDP or TCP). Some servers require the client's IP address to have a pointer record in the DNS.
Other servers, such as the Rlogin server, not only require that the client's IP address have a pointer record, but then ask the DNS for the IP addresses corresponding to the name returned in the PTR response, and require that one of the returned addresses match the source IP address in the received datagram. This check is because entries in the .rhosts file contain the hostname, not an IP address, so the server wants to verify that the hostname really corresponds to the incoming IP address.
Some vendors automatically put this check into their resolver routines, specifically the function gethostbyaddr. This makes the check available to any program using the resolver, instead of manually placing the check in each application.
Resource Records
We've seen a few different types of resource records (RRs) so far: an IP address has a type of A, and PTR means a pointer query. We've also seen that RRs are what a name server returns: answer RRs, authority RRs, and additional information RRs. There are about 20 different types of resource records, some of which we'll now describe. Also, more RR types are being added over time.
| A | An A record defines an IP address. It is stored as a 32-bit binary value. |
| PTR | This is the pointer record used for pointer queries. The IP address is represented as a domain name (a sequence of labels) in the in-addr.arpa domain. |
| CNAME | This stands for "canonical name." It is represented as a domain name (a sequence of labels). The domain name that has a canonical name is often called an alias. These are used by some FTP sites to provide an easy to remember alias for some other system. For example, the gated server is available through anonymous FTP from the server gated.cornell.edu. But there is no system named gated, this is an alias for some other system. That other system is the canonical name for gated.cornell.edu: sun % host -t cname gated.cornell.edu gated.cornell.edu CNAME COMET.CIT.CORNELL.EDO Here we use the -t option to specify one particular query type. |
| HINFO | Host information: two arbitrary character strings specifying the CPU and operating system. Not all sites provide HINFO records for all their systems, and the information provided may not be up to date. sun % host -t hinfo sun sun.tuc.noao.edu HINFO Sun-4/25 Sun4.1.3 |
| MX | Mail exchange records, which are used in the following scenarios: (1) A site that is not connected to the Internet can get an Internet-connected site to be its mail exchanger. The two sites then work out an alternati ve way to exchange any mail that arrives, often using the UUCP protocol. (2) MX records provide a way to deliver mail to an alternative host when the destination host is not available. (3) MX records allow organizations to provide virtual hosts that one can send mail to, such as cs.university.edu, even if a host with that name doesn't exist. (4) Organizations with firewall gateways can use MX records to limit connectivity to internal systems. Many sites that are not connected to the Internet have a UUCP link with an Internet connected site such as UUNET. MX records are then provided so that electronic mail can be sent to the site using the standard user@host notation. For example, a fictitious domain foo.com might have the following MX records: sun % host -t mx foo.com foo.com MX relayl.UU.NET foo.com MX relay2.UH.NET MX records are used by mailers on hosts connected to the Internet. In this example the other mailers are told "if you have mail to send to user@foo.com, send the mail to relay1.uu.net or relay2.uu.net." MX records have 16-bit integers assigned to them, called preference values. If multiple MX records exist for a destination, they're used in order, starting with the smallest preference value. |
| NS | Name server record. These specify the authoritative name server for a domain. They are represented as domain names (a sequence of labels). |
Caching
To reduce the DNS traffic on the Internet, all name servers employ a cache. With the standard Unix implementation, the cache is maintained in the server, not the resolver. Since the resolver is part of each application, and applications come and go, putting the cache into the program that lives the entire time the system is up (the name server) makes sense. This makes the cache available to any applications that use the server. Any other hosts at the site that use this name server also share the server's cache.















 38万+
38万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









