








1 学习GC之前
1.1 对象
面向对象编程:具有属性和行为的事物。
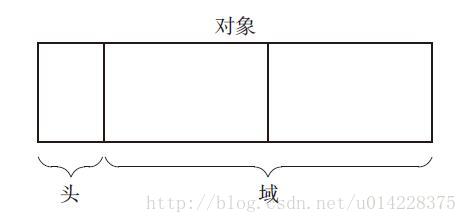
GC世界:通过应用程序利用的数据的集合。对象配置在内存中,GC根据情况将配置好的对象进行移动或销毁操作,因此对象是GC的基本单位。对象由头(head)和域(yield)组成。
1.1.1 头
对象中保存对象本身信息的部分称为头。
1. 对象的大小
2. 对象的种类
用于判别内存中存储的对象的边界。
此外,头中事先存有运行GC所需要的信息。根据GC算法的不同,信息也不同。在标记-清除算法中,就在对象的头部中设置1个flag(标识位)来记录对象是否已经被标记,从而管理各个对象。
1.1.2 域
对象使用者在对象中可以访问的部分称为域。对象使用者会引用或替换对象的域值,无法直接修改头的信息。域中的数据类型可以分为两种:
1. 指针
2. 非指针
指针是指向内存空间中某块区域的值。(指针==内存地址)
非指针指的是在编程中直接使用值本身。数值、字符以及真假值都是非指针。
ps: 突然想到链表!这里顺便复习一下数据结构中的链表,链表是一种线性的物理地址上离散的数据存储结构,通常使用指针来表示各个数据元素之间的逻辑关系,因此,每个数据元素中包含了指针域和数据域分别存储下个数据元素的内存地址和该数据元素所存储的数据。
在对象内部头之后存在一个及一个以上的域。
1.2 指针
通过GC,对象会被销毁或保留。GC会根据对象的指针指向去搜寻其他对象,GC对非指针不进行任何操作。
指针默认指向的对象的首地址。
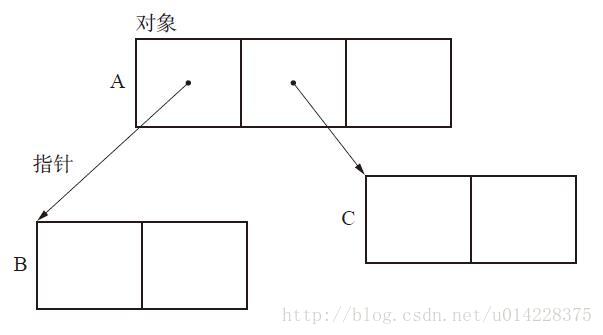
在前面介绍对象时,提到了在对象内部头之后包含一个及一个以上的域,可以是指针域或非指针域。图中A对象中则在两个指针域中分别存放了B对象和C对象的内存地址。这样BC对象称为A的子对象,对某个对象的子对象进行某项处理是GC的基本操作。
1.3 mutator(修改器)
mutator的作用就是改GC对象间的引用关系。它的实体就是应用程序,GC就是在这个mutator内部精神饱满地工作着。mutator进行的操作有以下两种:
1. 生成对象
2. 更新指针
mutator在进行这些操作时,会同时为应用程序的用户进行一些处理(数值计算,浏览网页,编辑文章等)随着这些处理的逐步推进,对象间的引用关系也会改变。伴随这些变化会产生垃圾,而负责回收这些垃圾的机制就是GC。
1.4 堆
堆指的是用于动态也就是执行程序时存放对象的内存空间,当mutator申请存放对象时,所需的内存空间就会从这个堆中被分配给mutator。
GC是管理堆中已经分配对象的机制。在开始执行mutator前,GC要分配用于堆的内存空间。一旦开始执行mutator,程序就会按照mutator的要求在堆中存放对象。等到堆被对象沾满后,GC就会启动,从而分配可用空间。如果不能分配足够的可用空间,一般情况下我们会选择扩大堆。(Java程序运行时出现内存溢出的现象就是堆内存不够用了,所以解决该问题的方法只有两种,修改jvm参数增加堆内存和review源程序优化代码,如使用单例模式)
1.5 活动对象/非活动对象
将分配到内存中的对象中那些能通过mutator引用的对象称为活动对象,反之称为非活动对象。对象死掉之后就不可能复活,就算mutator想要重新引用已经死掉的对象,没有办法通过mutator来找到它(因为没有任何对象保存了该对象的内存地址,已经就被无数的非活动对象淹没了)。因此,GC会保留活动对象,销毁非活动对象。当销毁非活动对象时,其原本占据的内存空间得以释放,供给下一个要分配的新对象使用。

1.6 分配
分配指的是在内存空间中分配对象。当mutator需要新对象时,就会让分配器allocator申请一个大小合适的空间,分配器则在堆的可用空间中寻找满足要求的空间返回给mutator。
然而,当堆被所有活动对象沾满时,就算运行GC也无法分配可用空间。这时候有两种选择:
1. 销毁至今为止的所有结果,输出错误信息(Java抛出内存溢出异常)
2. 扩大堆,分配可用空间(Java修改jvm参数,增大堆内存空间)
1.7 分块
chunk在GC的世界里指的是为利用对象而事先准备出来的空间。
初始状态下,堆被一个大的分块占据。
然后,程序会根据mutator的要求把这个分块分割成合适的大小,作为活动对象的使用。活动对象不久后会转化为垃圾被回收。此时,这部分被回收的内存空间再次成为分块,为下次被利用准备。
内存里的各个区块都重复着分块–>活动对象–>垃圾(非活动对象)–>分块……这样的过程。
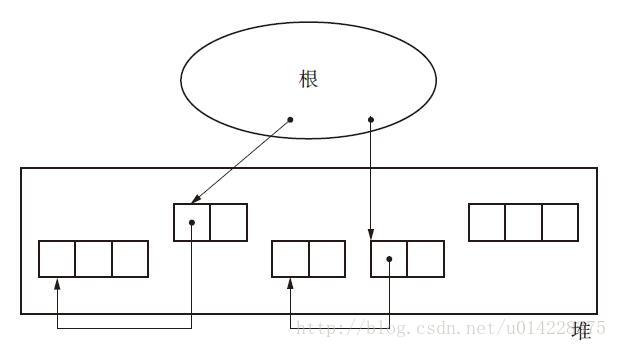
1.8 根
根指的是指向对象的指针的起点部分。这些都是能通过mutator直接引用的空间。我们可以通过mutator直接引用调用栈(call stack)、寄存器和全局变量,也就是说调用栈、寄存器和全局变量空间都是根。
1.9 评价标准
评价GC算法的性能时,我们采用以下四个标准:
1. 吞吐量
2. 最大暂停时间
3. 堆使用效率
4. 访问的局部性
1.9.1 吞吐量
throughput指的是在单位时间内的处理能力。
1.9.2 最大暂停时间
指的是因执行GC而暂停执行mutator的最长时间。
1.9.3 堆使用率
根据GC算法的差异,堆使用效率也大相径庭。左右堆使用率的因素有两个。
1. 头的大小
2. 堆的用法
头的大小。在堆中存放的信息越多,GC的效率也就越高,吞吐量也就随之得到改善。但毋庸置疑,头越小越好。因此为了执行GC,需要把在头中存放的信息控制在最小限度。
堆的用法。根据堆的用法,堆使用率也会出现巨大的差异。GC复制算法中将堆二等分,每次只使用一半,交替进行,只能利用堆的一半。GC标记法和引用计数法则可以利用到整个堆。
可用的堆越大,GC运行越快;相反,越想有效地利用有限的堆,GC花费的时间就越长。堆的使用率和吞吐量以及最大暂停时间不可兼得。
1.9.4 访问的局部性
这个涉及到一些硬件的知识(⊙﹏⊙),先来看个图压压惊。
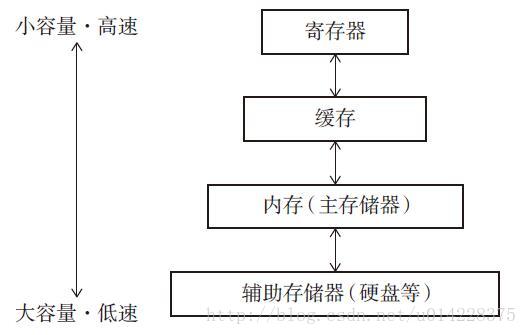
我们都知道,越是可实现高速存取的存储器容量就越小。都希望尽可能地利用较高速的存储器,但是由于高速的存储器容量小,因此通常不可能把所有要利用的数据都放在寄存器和缓存里。一般我们会把所有的数据都放在内存里,当CPU访问数据时,仅把要使用的数据从内存读取到缓存。与此同时,接下来的这句话很重要,还将它附近的所有数据都读取到缓存中,从而压缩读取数据所需要的时间。这句话为什么这么重要呢?往下看。
具有引用关系的对象之间通常很有可能存在连续访问的情况,称为访问的局部性。考虑访问的局部性,把具有引用关系的对象安排在堆中较近的位置,就能提高在缓存总读取到想利用的数据的概率。(⊙o⊙)哦,搜嘎。
参考文献:《垃圾回收的算法与实现》,中村成洋、相川光















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









