







统计学习的三要素为:模型、策略、算法。
一、模型
(1)在监督学习当中,我们的目的是学习一个由输入到输出的映射,这个映射就是模型。一般来说,模型有两种形式,一种是概率模型(条件概率分布P(Y|X)),另一种形式是非概率模型(决策函数Y = f(X))。
(2)假设空间是一集合:由输入空间到输出空间所有映射的集合。即:条件概率的集合、或者决策函数的集合。
二、策略:就是从假设空间中找到最优的映射(模型)
1,先介绍损失函数和风险函数
损失函数是用来度量模型一次映射结果的好坏;风险函数(期望损失)是用度量平均意义下模型预测的好坏。损失函数的期望是:
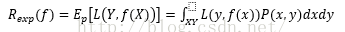
风险函数的计算需要用到P(Y|X),我们对它又不可知,所以监督学习就成了一个病态问题。既然这样,我们就想,在统计学中有一个大数定律,如果我在输入输出空间中取一个足够大的样本,用这个样本来近似的计算风险函数R_{exp}(f)。基于这样的想法,我们对于含有N组数据的训练集,定义经验损失函数:

根据大数定律,当N趋近于无穷大的时候,经验风险函数就趋近于风险函数。
2,学习过程在假设空间中选择经验风险最小的,统计学习中的策略一般有两种——经验风险最小化,结构风险最小化
经验风险最小化(ERM):极大似然估计就是经验风险最小化的例子,当模型是概率模型是,经验风险最小化就是极大似然估计。
结构风险最小化(SRM):为了防止过拟合现象,结构风险最小化这个策略被提了出来。
其中,表示的是模型的复杂度。模型越复杂,
的值就越大。
是一个大于等于0的系数,用来做一个trade-off的作用,平衡经验损失和模型复杂度的一个系数。可以从这个式子看出来,
起到是一个惩罚项的作用,当模型越复杂,惩罚项越大。
三、算法
算法,就是求解上面优化问题的算法。这就需要用到数值优化的知识。
参考书:《统计学习方法》——李航
注释:大数定律:当数很大的时候,平均值就是期望值。















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









