







在执行Hive语句中,难免会好奇Hive的执行原理,通过explain可以查看Hive转换后的抽象语法树和操作符树
hive> explain extended select sum(shopid) from shopt1 limit 10;生成的语法解析树AST Tree如下所示:
ABSTRACT SYNTAX TREE:
TOK_QUERY
TOK_FROM
TOK_TABREF
TOK_TABNAME
shopt1 ---表名
TOK_INSERT
TOK_DESTINATION
TOK_DIR
TOK_TMP_FILE ---所有的查询的数据会输出到HDFS的一个暂存文件中
TOK_SELECT
TOK_SELEXPR
TOK_FUNCTION
sum ---获取使用到的函数
TOK_TABLE_OR_COL
shopid ----获取select的列
TOK_LIMIT
10
执行计划如下所示:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1 ----stage-0依赖stage-1
STAGE PLANS:
Stage: Stage-1
Tez
Edges:
Reducer 2 <- Map 1 (SIMPLE_EDGE)
DagName: work_20160918215757_92e7e39d-b52e-49dc-b0dd-d8807b87c7d2:1
Vertices:
Map 1
Map Operator Tree:
TableScan ----扫描shopt1表
alias: shopt1
Statistics: Num rows: 5 Data size: 42 Basic stats: COMPLETE Column stats: NONE
Select Operator -----筛选select到的列
expressions: shopid (type: bigint)
outputColumnNames: shopid
Statistics: Num rows: 5 Data size: 42 Basic stats: COMPLETE Column stats: NONE
Group By Operator ---分组
aggregations: sum(shopid)
mode: hash ---hash分组
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator ---Map端的Reduce过程
sort order:
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
value expressions: _col0 (type: bigint)
Reducer 2
Reduce Operator Tree:
Group By Operator ----reduce端的分组合并
aggregations: sum(VALUE._col0)
mode: mergepartial
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: bigint)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 10
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
File Output Operator ---最终文件的输出
compressed: false
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat ---输入
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat ---输出
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe --序列化
Stage: Stage-0
Fetch Operator
limit: 10 ---limit 10
Processor Tree:
ListSink
------------------------------------------------------------------------------------------------
以下是参考美团技术博客Hive的编译过程,摘取核心执行部分share
Sql:
FROM
(
SELECT
p.datekey datekey,
p.userid userid,
c.clienttype
FROM
detail.usersequence_client c
JOIN fact.orderpayment p ON p.orderid = c.orderid
JOIN default.user du ON du.userid = p.userid
WHERE p.datekey = 20131118
) base
INSERT OVERWRITE TABLE `test`.`customer_kpi`
SELECT
base.datekey,
base.clienttype,
count(distinct base.userid) buyer_count
GROUP BY base.datekey, base.clienttype1.首先对sql进行语法分析,词法分析,解析SQL生成AST Tree(抽象语法树)

2.根据AST Tree生成QueryBlock
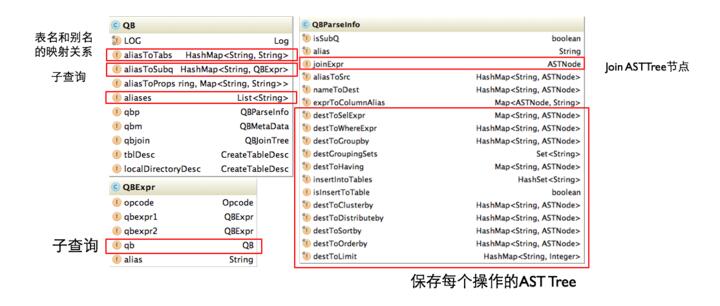
上图是QueryBlock相关对象的类图,AST Tree生成QueryBlock的过程是一个递归的过程,先序遍历AST Tree,遇到不同的Token节点,保存到相应的属性中,主要包含以下几个过程
- TOK_QUERY => 创建QB对象,循环递归子节点
- TOK_FROM => 将表名语法部分保存到QB对象的
aliasToTabs等属性中 - TOK_INSERT => 循环递归子节点
- TOK_DESTINATION => 将输出目标的语法部分保存在QBParseInfo对象的nameToDest属性中
- TOK_SELECT => 分别将查询表达式的语法部分保存在
destToSelExpr、destToAggregationExprs、destToDistinctFuncExprs三个属性中 - TOK_WHERE => 将Where部分的语法保存在QBParseInfo对象的destToWhereExpr属性中
3.Operator逻辑操作符
Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。逻辑操作符,就是在Map阶段或者Reduce阶段完成单一特定的操作。
基本的操作符包括TableScanOperator,SelectOperator,FilterOperator,JoinOperator,GroupByOperator,ReduceSinkOperator
从名字就能猜出各个操作符完成的功能,TableScanOperator从MapReduce框架的Map接口原始输入表的数据,控制扫描表的数据行数,标记是从原表中取数据。JoinOperator完成Join操作。FilterOperator完成过滤操作
ReduceSinkOperator将Map端的字段组合序列化为Reduce Key/value, Partition Key,只可能出现在Map阶段,同时也标志着Hive生成的MapReduce程序中Map阶段的结束。
Operator在Map Reduce阶段之间的数据传递都是一个流式的过程。每一个Operator对一行数据完成操作后之后将数据传递给childOperator计算。
QueryBlock生成Operator Tree
QueryBlock生成Operator Tree就是遍历上一个过程中生成的QB和QBParseInfo对象的保存语法的属性,包含如下几个步骤:
- QB#aliasToSubq => 有子查询,递归调用
- QB#aliasToTabs => TableScanOperator
- QBParseInfo#joinExpr => QBJoinTree => ReduceSinkOperator + JoinOperator
- QBParseInfo#destToWhereExpr => FilterOperator
- QBParseInfo#destToGroupby => ReduceSinkOperator + GroupByOperator
- QBParseInfo#destToOrderby => ReduceSinkOperator + ExtractOperator
4. OperatorTree生成MapReduce Job的过程
OperatorTree转化为MapReduce Job的过程分为下面几个阶段
- 对输出表生成MoveTask
- 从OperatorTree的其中一个根节点向下深度优先遍历
- ReduceSinkOperator标示Map/Reduce的界限,多个Job间的界限
- 遍历其他根节点,遇过碰到JoinOperator合并MapReduceTask
- 生成StatTask更新元数据
- 剪断Map与Reduce间的Operator的关系,拆分MR任务。
具体可参考Hive SQL的编译过程















 4085
4085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









