






首先先上一下安卓客户端的效果,之前是静态的图片,不够形象,上一个动态图提升一下逼格。嘿嘿
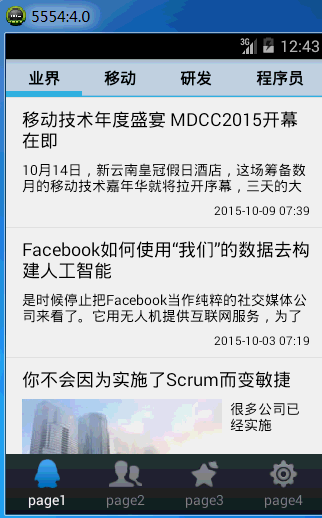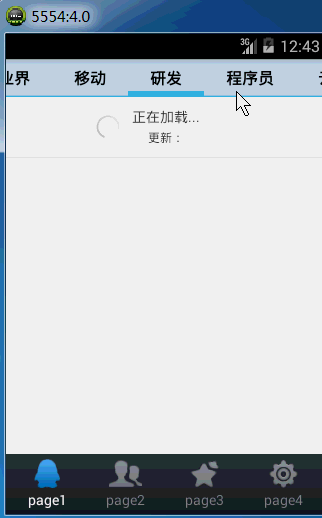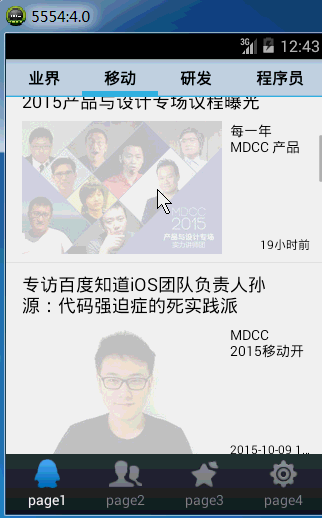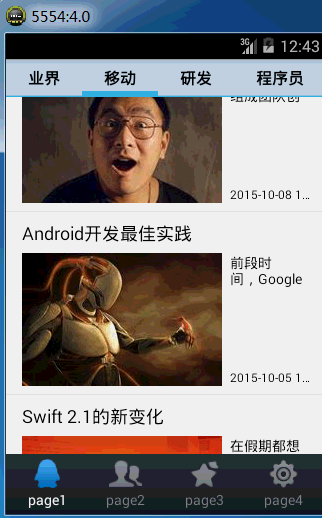
因为我们使用jsoup解析html文件,所以记得在lib里面添加一下jsoup-1.7.2.jar
下载地址:http://download.csdn.net/detail/start_baby/5132499
今天我们的任务就是从CSDN网站上获取每一个条目相应的目录列表,先贴一下代码,然后我们通过代码来理清思路
我们首先要定义一个新闻目录类,用来存储获取到的每一个新闻
NewsItem.java
public class NewsItem {
private int id;
/**
* 标题
*/
private String title;
/**
* 链接
*/
private String link;
/**
* 发布日期
*/
private String date;
/**
* 图片的链接
*/
private String imgLink;
/**
* 内容
*/
private String content;
/**
* 类型
*
*/
private int newsType;
public int getNewsType()
{
return newsType;
}
public void setNewsType(int newsType)
{
this.newsType = newsType;
}
public String getTitle()
{
return title;
}
public void setTitle(String title)
{
this.title = title;
}
public String getLink()
{
return link;
}
public void setLink(String link)
{
this.link = link;
}
public int getId()
{
return id;
}
public void setId(int id)
{
this.id = id;
}
public String getDate()
{
return date;
}
public void setDate(String date)
{
this.date = date;
}
public String getImgLink()
{
return imgLink;
}
public void setImgLink(String imgLink)
{
this.imgLink = imgLink;
}
public String getContent()
{
return content;
}
public void setContent(String content)
{
this.content = content;
}
@Override
public String toString()
{
return "NewsItem [id=" + id + ", title=" + title + ", link=" + link + ", date=" + date + ", imgLink=" + imgLink
+ ", content=" + content + ", newsType=" + newsType + "]";
}
}
定义好了数据类型,我们现在就可以放心的获取网上的数据,这样就不要担心这些数据无家可归了。下面你可以通过注释理解代码,我尽量为你解释每一行代码。
NewsItemBiz.java
package com.example.httputil;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.example.myapplication.myApplication;
import android.content.Context;
import android.os.Handler;
import android.os.Message;
import android.provider.DocumentsContract.Document;
import android.util.Log;
public class NewsItemBiz {
//定义一个NewsItem类型的数组
List<NewsItem> newsItems = new ArrayList<NewsItem>();
private int newsType;
public NewsItemBiz() {
// TODO Auto-generated constructor stub
/*
* 这里我通过handler机制来控制进程的先后顺序,这是一个很必要的工作,也是我之前碰到的问题得出来的经验,问题大概是这样的:
* 因为网络请求数据必须创建一个线程,否则会导致主UI卡死。所以我们创建了一个线程,并且将
* 返回来的数据变成字符串的形式进行处理,然后我们在主线程中需要解析这个字符串
* ,这时候问题就出现了,当子线程请求网络数据还没有结束的时候,主线程就已经开始解析了
* ,这时候这个字符串肯定为空,就会产生错误,所以一定要使用这个异步消息机制
*/
public Handler handler=new Handler()
{
public void handleMessage(android.os.Message msg) {
NewsItem newsItem = null;
org.jsoup.nodes.Document doc = Jsoup.parse(msg.obj.toString());
Elements units = doc.getElementsByClass("unit");
for (int i = 0; i < units.size(); i++)
{
newsItem = new NewsItem();
newsItem.setNewsType(newsType);
Element unit_ele = units.get(i);
Element h1_ele = unit_ele.getElementsByTag("h1").get(0);
Element h1_a_ele = h1_ele.child(0);
String title = h1_a_ele.text();
String href = h1_a_ele.attr("href");
Log.i("hello",title);
newsItem.setLink(href);
newsItem.setTitle(title);
Element h4_ele = unit_ele.getElementsByTag("h4").get(0);
Element ago_ele = h4_ele.getElementsByClass("ago").get(0);
String date = ago_ele.text();
newsItem.setDate(date);
Element dl_ele = unit_ele.getElementsByTag("dl").get(0);// dl
Element dt_ele = dl_ele.child(0);// dt
try
{// 可能没有图片
Element img_ele = dt_ele.child(0);
String imgLink = img_ele.child(0).attr("src");
newsItem.setImgLink(imgLink);
} catch (IndexOutOfBoundsException e)
{
}
Element content_ele = dl_ele.child(1);// dd
String content = content_ele.text();
newsItem.setContent(content);
newsItems.add(newsItem);
}
};
};
//此函数才是真正被调用的函数,第一个参数是当前页面的类型,第二个参数是页数
public List<NewsItem> getNewsItems( int newsType , int currentPage) throws CommonException, IOException
{
//通过当前页面类型和页数构造出真正的网址
String urlStr = URLUtil.generateUrl(newsType, currentPage);
//将之前的数组清空
newsItems.clear();
doGet(urlStr);
/*
* 下面的while循环很有必要,因为当子线程还有没有返回字符串时,那么handler就没有办法解析html的时候,
* 有可能你的主线程已经走到了下面的一句return
* newsItems,那么毫无意外,你就只能得到一个空的newsItems,这就是心急吃不了热豆腐啊
* ,所以我们就要判断newsitems是不是为空,如果是空的话,我们就用一个线程等待
*/
while((newsItems.size()==0))
{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
return newsItems;
}
//此函数用来获取一个网页的html数据,并将其变成字符串格式
public void doGet(final String urlStr) throws CommonException{
final StringBuffer sb = new StringBuffer();
new Thread(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
try {
URL url = new URL(urlStr);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.setConnectTimeout(5000);
conn.setDoInput(true);
conn.setDoOutput(true);
if(conn.getResponseCode() == 200){
InputStream is = conn.getInputStream();
int len = 0;
byte[] buf = new byte[1024];
while((len = is.read(buf)) != -1){
sb.append(new String(buf, 0, len, "UTF-8"));
}
Message message =new Message();
message.obj=sb;
handler.sendMessage(message);
is.close();
}else{
throw new CommonException("访问网络失败00");
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
try {
throw new CommonException("访问网络失败11");
} catch (CommonException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
}
}
}).start();
}
}
下面开始测试一下上面的NewsItemBiz类,特别注意使用上面类,要使用异步任务,因为在主线程中获取List耗了很长的时间,如果不使用,会导致UI线程卡死,不信的话,你可以试一试哦,我把我之前没有用异步任务的代码也列在了下面,方便你比较这两者的差别吧!
public class secondFragment extends android.support.v4.app.Fragment{
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
// TODO Auto-generated method stub
View v=inflater.inflate(R.layout.secondfragment, container,false);
Button button=(Button)v.findViewById(R.id.send);
button.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
new LoadDatasTask().execute();
//下面就是我之前在主线程中使用的代码,你只需将下面带//的去除,将上面一行加上//
// NewsItemBiz newitembiz=new NewsItemBiz();
// List<NewsItem> item=new ArrayList<NewsItem>();
// try {
// try {
// item=newitembiz.getNewsItems(3, 2);
// for (NewsItem newsItem : item) {
// Log.i("msg", newsItem.getContent());
// }
// } catch (CommonException e) {
// // TODO Auto-generated catch block
// e.printStackTrace();
// }
// } catch (IOException e) {
// // TODO Auto-generated catch block
// e.printStackTrace();
// }
}
});
return v;
}
class LoadDatasTask extends AsyncTask<Void, Void, Void> {
public NewsItemBiz newitembiz=new NewsItemBiz();
public List<NewsItem> item=new ArrayList<NewsItem>();
protected void onPostExecute(Void result) {
for (NewsItem newsItem : item) {
Log.i("msg", newsItem.getContent());
}
}
@Override
protected Void doInBackground(Void... params) {
// TODO Auto-generated method stub
try {
try {
item=newitembiz.getNewsItems(3, 2);
} catch (CommonException e) {
e.printStackTrace();
}
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
}
效果图还是要上一下的,不然说我骗人就不好了
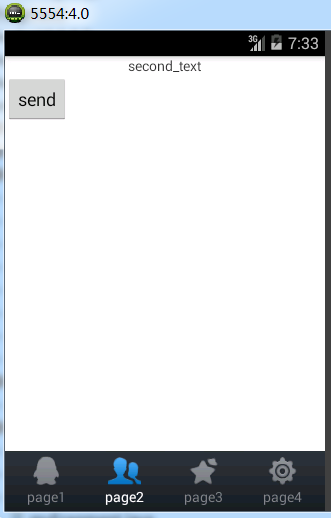
点击上面的send,然后观察logcat中的结果
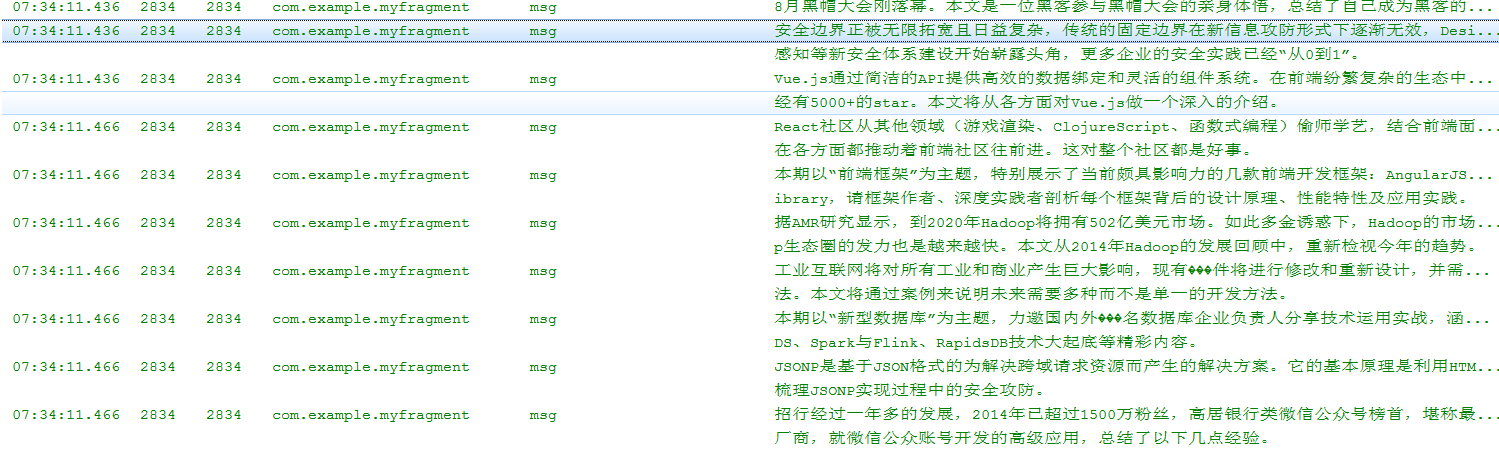
这一节关于从网络上获取并解析html文件我们就先讲到这里,看别人做一万遍,也不如自己做一遍,自己试着做一遍吧!相信自己,你可以的,加油!















 3411
3411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









