









将表情图片生成pkl格式的文件,代码如下。
import cPickle
import os
import json
import pylab
import numpy
from PIL import Image
i = 0;
// r'data\Expression 1 文件一共含有165张,每张大小40*40.
// olivettifaces 则保存的就是这165张图片的信息。
// olivettifaces_label 中包含的是165张图片的标签信息
olivettifaces=numpy.empty((165,1600))
olivettifaces_label=numpy.empty(165)
// 下面这函数是列出文件夹中所有的文件,到filename中
for filename in os.listdir(r'data\Expression 1\Anger (AN)'):
print filename
if(filename!='Thumbs.db'):
basedir = 'data\Expression 1\Anger (AN)/'
imgage = Image.open(basedir + filename)
img_ndarray = numpy.asarray(imgage, dtype='float64')/256
olivettifaces[i]=numpy.ndarray.flatten(img_ndarray)
// 标签要从0开始,不然在cnn训练时会有错误
olivettifaces_label[i]=0
i = i + 1
for filename in os.listdir(r'data\Expression 1\Disgust (DI)'):
print filename
if(filename!='Thumbs.db'):
basedir = 'data\Expression 1\Disgust (DI)/'
imgage = Image.open(basedir + filename)
img_ndarray = numpy.asarray(imgage, dtype='float64')/256
olivettifaces[i]=numpy.ndarray.flatten(img_ndarray)
olivettifaces_label[i]=1
i = i + 1
for filename in os.listdir(r'data\Expression 1\Fear (FE)'):
print filename
if(filename!='Thumbs.db'):
basedir = 'data\Expression 1\Fear (FE)/'
imgage = Image.open(basedir + filename)
img_ndarray = numpy.asarray(imgage, dtype='float64')/256
olivettifaces[i]=numpy.ndarray.flatten(img_ndarray)
olivettifaces_label[i]=2
i = i + 1
for filename in os.listdir(r'data\Expression 1\Happiness (HA)'):
print filename
if(filename!='Thumbs.db'):
basedir = 'data\Expression 1\Happiness (HA)/'
imgage = Image.open(basedir + filename)
img_ndarray = numpy.asarray(imgage, dtype='float64')/256
olivettifaces[i]=numpy.ndarray.flatten(img_ndarray)
olivettifaces_label[i]=3
i = i + 1
for filename in os.listdir(r'data\Expression 1\Sadness (SA)'):
print filename
if(filename!='Thumbs.db'):
basedir = 'data\Expression 1\Sadness (SA)/'
imgage = Image.open(basedir + filename)
img_ndarray = numpy.asarray(imgage, dtype='float64')/256
olivettifaces[i]=numpy.ndarray.flatten(img_ndarray)
olivettifaces_label[i]=4
i = i + 1
for filename in os.listdir(r'data\Expression 1\Surprise (SU)'):
print filename
if(filename!='Thumbs.db'):
basedir = 'data\Expression 1\Surprise (SU)/'
imgage = Image.open(basedir + filename)
img_ndarray = numpy.asarray(imgage, dtype='float64')/256
olivettifaces[i]=numpy.ndarray.flatten(img_ndarray)
olivettifaces_label[i]=5
i = i + 1
olivettifaces_label=olivettifaces_label.astype(numpy.int)
// 下面是生成pkl格式的文件,保存数据。
write_file=open('olivettifaces.pkl','wb')
cPickle.dump(olivettifaces,write_file,-1)
cPickle.dump(olivettifaces_label,write_file,-1)
write_file.close()
// 从pkl文件中读取数据显示图像和标签。
read_file=open('olivettifaces.pkl','rb')
faces=cPickle.load(read_file)
label=cPickle.load(read_file)
read_file.close()
img0=faces[100].reshape(40,40)
pylab.imshow(img0)
pylab.gray()
pylab.show()
print label[0:165]运行结果如下:
KA.AN1.39.bmp
KL.AN2.168.bmp
MK.SA2.120.bmp
。。。。。。
。。。。。。
UY.SU3.145.bmp
YM.SU1.58.bmp
YM.SU2.59.bmp
YM.SU3.60.bmp

[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 4 4
4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 5
5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5]
用过mnist.pkl手写体库的可能知道,用cPickle.load(read_file)的读取时,返回三个参数(训练集、验证集、测试集)。同时三个参数中包含两个值:样本和标签。
如:read_file=open(dataset,'rb')
train_set,valid_set,test_set=cPickle.load(read_file)
read_file.close()
train, label1 = train_set
valid, label2 = valid_set
test, label3 = test_set想要生成这样格式的数据也不难,只要把上面代码改动一下即可。
write_file=open('olivettifaces.pkl','wb')
cPickle.dump([[olivettifaces[0:100],olivettifaces_label[0:100]],
[olivettifaces[101:130],olivettifaces_label[101:130]],
[olivettifaces[131:164],olivettifaces_label[131:164]]],
write_file,-1)
write_file.close()
read_file=open('olivettifaces.pkl','rb')
train_set,valid_set,test_set=cPickle.load(read_file)
read_file.close()
train,label = train_set
img0=train[4].reshape(28,28)
pylab.imshow(img0)
pylab.gray()
pylab.show()
print label[0:100] 并且这样改动完生成的.pkl文件,可以在CNN手写体识别的python代码上跑起来(注意LogisticRegression的参数n_out应该改成6,训练样本中只包含6中表情),当然前提是你的数据库要大,我这里只是写了方法,数据量是肯定不够的,当数据量足够时,你会发现惊人的效果。
这是python代码,训练8次的结果:
... loading data
... building the model
... training
...epoch is 1 writefile
writefile is data/theanocnn.json
training @ iter = 0
epoch 1, minibatch 20/20, validation error 45.640000 %
epoch 1, minibatch 20/20, test error of best model 46.366667 %
...epoch is 2 writefile
writefile is data/theanocnn.json
epoch 2, minibatch 20/20, validation error 14.280000 %
epoch 2, minibatch 20/20, test error of best model 14.433333 %
...epoch is 3 writefile
writefile is data/theanocnn.json
epoch 3, minibatch 20/20, validation error 7.640000 %
epoch 3, minibatch 20/20, test error of best model 7.733333 %
...epoch is 4 writefile
writefile is data/theanocnn.json
epoch 4, minibatch 20/20, validation error 13.120000 %
...epoch is 5 writefile
writefile is data/theanocnn.json
epoch 5, minibatch 20/20, validation error 2.760000 %
epoch 5, minibatch 20/20, test error of best model 2.733333 %
...epoch is 6 writefile
writefile is data/theanocnn.json
training @ iter = 100
epoch 6, minibatch 20/20, validation error 1.640000 %
epoch 6, minibatch 20/20, test error of best model 1.666667 %
...epoch is 7 writefile
writefile is data/theanocnn.json
epoch 7, minibatch 20/20, validation error 1.160000 %
epoch 7, minibatch 20/20, test error of best model 1.066667 %
...epoch is 8 writefile
writefile is data/theanocnn.json
epoch 8, minibatch 20/20, validation error 1.160000 %
Optimization complete.
Best validation score of 1.160000 % obtained at iteration 140,with test performance 1.066667 %
readfile is data/theanocnn.json
validation error 1.160000 %
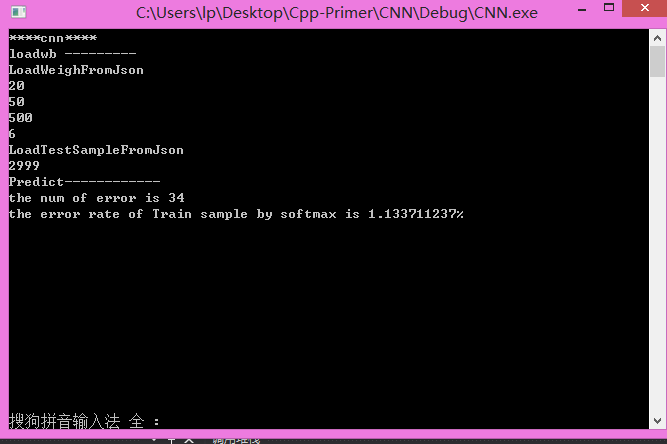
The code for file cnn.py ran for 4.01m这是C++,在测试集上跑的结果:
如果帮到你了,请赞赏支持:

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











