







 RA-CNN是CVPR2017的Oral文章,解决细粒度图像分类问题,无需bounding box标注。它包含3个scale子网络,交替进行特征提取和注意力区域聚焦。通过多任务学习,结合分类和区域检测,实现无监督的细粒度特征学习。RA-CNN在多个数据集上表现优秀,与监督式算法效果相当。
RA-CNN是CVPR2017的Oral文章,解决细粒度图像分类问题,无需bounding box标注。它包含3个scale子网络,交替进行特征提取和注意力区域聚焦。通过多任务学习,结合分类和区域检测,实现无监督的细粒度特征学习。RA-CNN在多个数据集上表现优秀,与监督式算法效果相当。
论文:Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition
论文链接:http://openaccess.thecvf.com/content_cvpr_2017/papers/Fu_Look_Closer_to_CVPR_2017_paper.pdf
Recurrent Attention Convolutional Neural Network(RA-CNN)是CVPR2017的Oral文章,针对细粒度(fine-grained)的分类。作者提出的RA-CNN算法不需要对数据做类似bounding box的标注就能取得和采用类似bounding box标注的算法效果。在网络结构设计上主要包含3个scale子网络,每个scale子网络的网络结构都是一样的,只是网络参数不一样,在每个scale子网络中包含两种类型的网络:分类网络和APN网络。因此数据流是这样的:输入图像通过分类网络提取特征并进行分类,然后attention proposal network(APN)网络基于提取到的特征进行训练得到attention区域信息,再将attention区域crop出来并放大,再作为第二个scale网络的输入,这样重复进行3次就能得到3个scale网络的输出结果,通过融合不同scale网络的结果能达到更好的效果。多scale网络的最大优点在于训练过程中可以逐渐聚焦到关键区域,能更加准确,因此多scale网络是本文的第一个亮点。另外针对分类网络和APN网络设计两个loss,通过固定一个网络的参数训练另一个网络的参数来达到交替训练的目的,文中也说明了这二者之间本身就是相互促进的,因此这两个子网络的设计及其交替训练方式是本文的第二个亮点。要说第三个亮点的话,那应该就是不需要bounding box的标注信息了,因为这种细粒度图像的bounding box标注会比普通的bounding box更难,更加需要专业知识,因此无监督式地寻找关键区域是比较理想的方向。总的来讲这篇文章的网络结构和训练策略设计得非常巧妙,不愧是CVPR2017的oral。
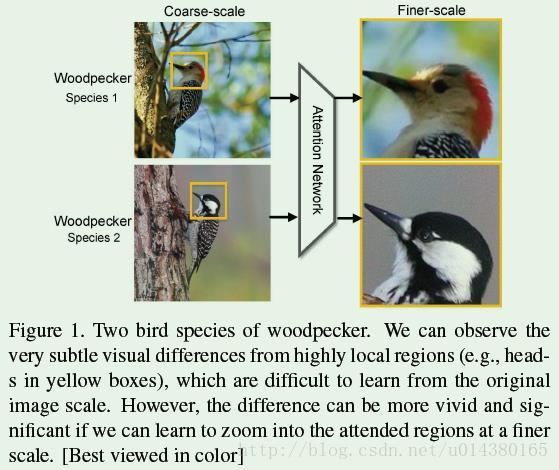
细粒度(fine-grained)图像分类是近几年比较火的领域,可以看FIugre1中的例子,虽然都是啄木鸟,但是要细分不同的品种,可以看出这两类之间的特征差异非常小。因此细粒度图像分类的难点主要包含两方面:1、discriminative region localization;2、finegrained feature learning from those regions。也就是说一方面要能准确定位到那些关键区域,另一方面要能从那些关键区域中提取有效的信息,在作者看来这两方面是相互促进的,所以在训练网络的时候采取了交替训练的策略。目前关于这样的区域定位方法主要分为两种:监督式和非监督式。监督式也就是对训练数据标注bounding box信息,类似object detection算法;非监督式的就是通过网络去学习这些区域信息,训练数据没有bounding box信息。
其他一些细粒度图像算法一般是怎么做呢?主要分两步,第一步是采用无监督或者有监督(比如常见的object detection算法)的算法检测出指定的区域。第二步是从第一步检测到的区域中提取特征用于分类。原文如下:Previous research has made impressive progresses by introducing partbased recognition frameworks, which typically consist of two steps: 1) identifying possible object regions by analyzing convolutional responses from neural networks in an unsupervised fashion or by using supervised bounding box/part annotations, and 2) extracting discriminative features from each region and encoding them into compact vectors for recognition. 但是人为标定的区域(region)不一定是最适合模型分类的区域,另外作者认为这两步之间是有相互促进关系的,原文如下:We found that region detection and fine-grained feature learning are m
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









