









在学习word2vector的过程中,下面两位博主的总结及讲解给了我很大帮助。本文主要是记录在学习和理解他们的博客的过程中个人也有一些思考和理解。本人才学疏漏,有错误的地方请大家指正。
http://blog.csdn.net/itplus/article/details/37969519
http://blog.csdn.net/mytestmy/article/details/26969149?utm_source=tuicool&utm_medium=referral
1,word2vector中hierarchical softmax 为什么可行 !
在刚开始看博文的时候,不太清楚通过能量函数算出来的概率 一定和通过这种层次化得树结构算出来的概率一样吗?一直不能说服自己,后面细细想了下,下面的一个理解总算是把这点想通了。
按道理讲:
分成两类的话
全概率公式p(A│C)=p(A|G,C)p(G|C) +p(A│C)=p(A|H,C)p(H|C) 但由于二分类的缘故后面一项为0;
所以就有了下面的公式。
p(A│C)=p(A|G,C)p(G|C)
2,Hierarchical Softmax的目的
将原来不好求的问题p(A|context),可以用下面的公式算但是代价太大。至于为什么要算这个概率,通过算p(w|context)可以算出这一句话的概率,而优化的目标就是使这句话是自然语言的概率最大。
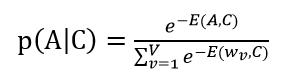
从复杂度O(V)变为O(log2V)(V为词典大小)
3,CBOX和skip-gram的区别。
CBOX是将上下文的vector累加起来作为树结构最开始的那个向量,然后在树结构中找出一条路径算P(w|context)
Skip-gram是将这个w作为树结构最开始的那个向量,然后在树结构中找出多条路径算P(context|w)(上下文中有多少个词就有多少条路径,然后连乘起来得到概率),也可以说目标函数不一样了,前面是最大化P(w|context),后面是最大化P(context|w),当然这么说不太确切。
4,negative sampling
1,采样,采样的时候根据词出现的频率分配一个权重,让出现次数越多的词越容易被采样到,具体做法是,将他们的词频作为长度拼接起来,然后生成一个random数,落到哪个区间就选谁,当然负采样是取负样本(一般取context个),所以如果采样到正样本,则跳过。
2, 优化的目标变了,但总体目的没变,就是让这个上下文生成w的概率变大,生成其他的概率变小。















 3215
3215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









