










CBAM是IEEE 2018的一篇文章
Convolutional Block Attention Module (CBAM) 表示卷积模块的注意力机制模块。是一种结合了空间(spatial)和通道(channel)的注意力机制模块。相比于senet只关注通道(channel)的注意力机制可以取得更好的效果。
CBAM的结构如下:
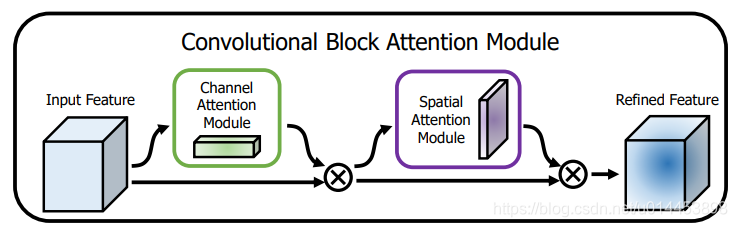
通道注意力决定了网络“look what”,因为每个通道所关注的特征是不一样的。空间注意力决定了网络“look where”。
Input Feature F的维度是CxHxW,通道注意力特征Mc的维度是Cx1x1。空间注意力特征Ms的维度是1xHxW。
通道注意力特征的形成如下:
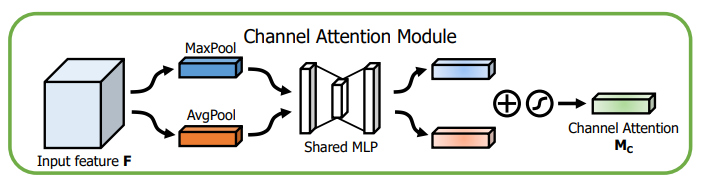
论文作者认为,前人的一些操作表明了用平均池化可以有效地聚集空间信息。而作者认为,最大池化可以更好地获得一些独特物体的特征从而调优注意力模型。通过平均池化和最大池化后的特征会各自通过MLP的两个fc层,得到MLP处理后的平均池化特征和最大池化特征,然后再加到一起,最后通过softmax层,再作为output输出。
公式如下:
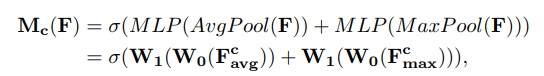
表示softmax操作。
代码如下:

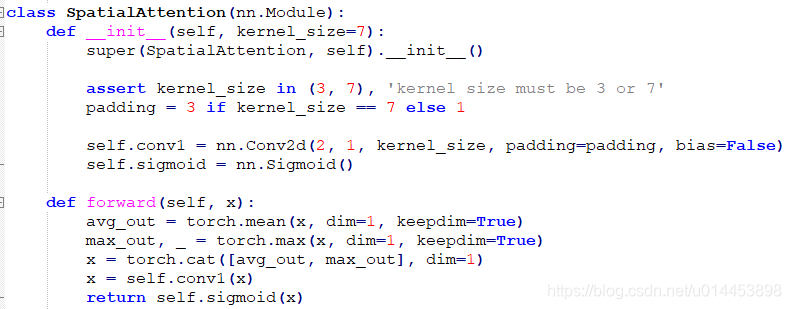
空间注意力特征的形成如下:
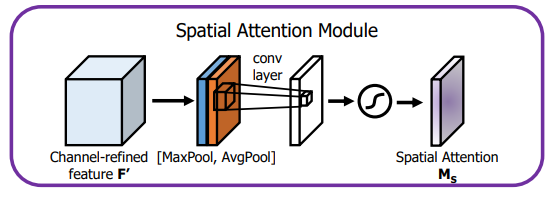
输入特征沿着通道的维度方向分别进行最大操作和平均操作,再直接连接在一起,然后再通过卷积操作,达到强调或抑制某些地方的作用。最后通过softmax层得到最终输出。
公式如下:
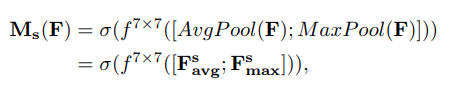
表示softmax操作。
表示卷积核为7x7的卷积操作。;表示连接。
代码如下:
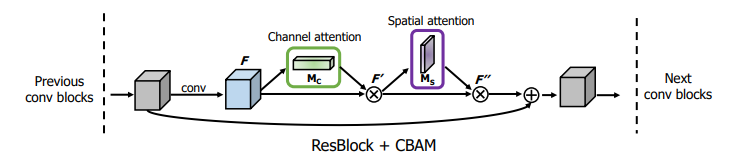
CBAM注意力模块的应用:
论文中的CBAM模块是嵌入到resnet中的,resnet中的每个block都嵌入了CBAM模块。流程图如下:
公式如下:
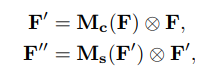
用于语义分割:
而怎么看用于语义分割的效果呢?只需要把最后的特征图进行上采样就行了
输入图片:

输出:

可以看出效果其实很不好。
当然也有可能是我代码写得有问题,欢迎讨论。
代码链接:https://github.com/Andy-zhujunwen/pytorch-CBAM-Segmentation-experiment-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









