







 本文详细解析了最左匹配原则,展示了不遵循该原则及范围查询时联合索引的失效情况,包括like查询。实战案例揭示了索引选择和使用策略,助你理解SQL优化。
本文详细解析了最左匹配原则,展示了不遵循该原则及范围查询时联合索引的失效情况,包括like查询。实战案例揭示了索引选择和使用策略,助你理解SQL优化。
目录
一、最左匹配
讲联合索引,一定要扯最左匹配!
最左匹配:
所谓最左原则指的就是如果你的 SQL 语句中用到了联合索引中的最左边的索引,那么这条 SQL 语句就可以利用这个联合索引去进行匹配,值得注意的是,当遇到范围查询(>、<、between、like)就会停止匹配。
假设,我们对(a,b)字段建立一个索引,也就是说,你where后条件为
a=1
a=1 and b=2
是可以匹配索引的。但是要注意的是~你执行
b=2 and a=1
也是能匹配到索引的,因为Mysql有优化器会自动调整a,b的顺序与索引顺序一致。 相反的,你执行
b = 2
就匹配不到索引了。 而你对(a,b,c,d)建立索引,where后条件为
a = 1 and b = 2 and c > 3 and d = 4
那么,a,b,c三个字段能用到索引,而d就匹配不到。因为遇到了范围查询!
为什么呢?
我们仔细看最左匹配的原理,假设,我们对(a,b)字段建立索引,那么入下图所示
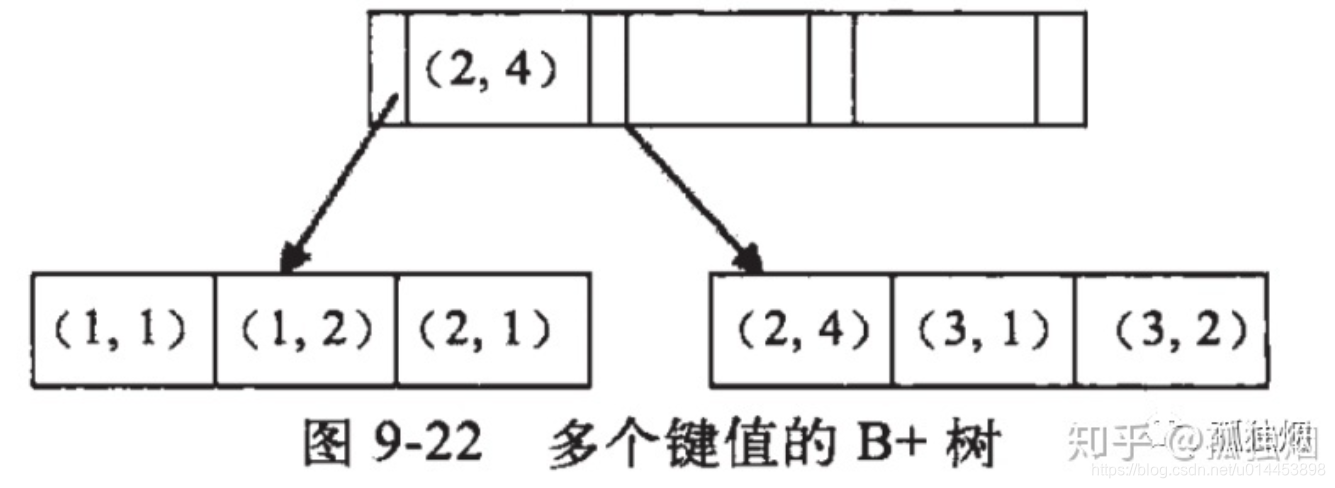
如图所示他们是按照a来进行排序,在a相等的情况下,才按b来排序。
因此,我们可以看到a是有序的1,1,2,2,3,3。而b是一种全局无序,局部相对有序状态! 什么意思呢?
从全局来看,b的值为1,2,1,4,1,2,是无序的,因此直接执行
b = 2这种查询条件没有办法利用索引。从局部来看,当a的值确定的时候,b是有序的。例如a = 1时,b值为1,2是有序的状态。当a=2时候,b的值为1,4也是有序状态。 因此,你执行
a = 1 and b = 2是a,b字段能用到索引的。而你执行a > 1 and b = 2时,a字段能用到索引,b字段用不到索引。因为a的值此时是一个范围,不是固定的,在这个范围内b值不是有序的,因此b字段用不上索引。综上所示,最左匹配原则,在遇到范围查询的时候,就会停止匹配。
只有在B+树的数据是有序的情况下,才能通过二分法查找到对应的为止,如果是无序的话,是无法通过二分法找到对应的数据的,这时候索引就用不上了。
注意 联合查询的一个特点:要是走联合索引(a,b),那么在B+树中,a和b字段的数据必然都是有序的。
所以,当遇到 :
c > 3 and d = 4
d 在 c =4、5、6.....时都有序(局部有序,例如c=4时,d有序,c=5时,d有序......),但当 c>3时,那么d就是无序的了。因此d就用不上索引了,所以这时候用不了联合索引。
二、联合索引失效的情况
2.1 不遵循最左匹配原则
关于这种情况,在上面已经说得挺清楚了。
在这里再举一个例子:
例如有表 t(a,b) 有sql语句:
select * from table where b = 2;
这时候是用不了联合索引(a,b)的。因为(a,b)规定b有序的前提是a有序,如果a不能确定,那b在b+树里肯定是无序的,那么就不能用索引(a,b)。
2.2 范围查询右边失效原理
例如有sql:
select * from testTable where a>1 and b=2
分析如下:
首先a字段在B+树上是有序的,所以可以用二分查找法定位到1,然后将所有大于1的数据取出来,a可以用到索引。
b有序的前提是a是确定的值,那么现在a的值是取大于1的,可能有10个大于1的a,也可能有一百个a。
大于1的a那部分的B+树里,b字段是无序的(开局一张图),所以b不能在无序的B+树里用二分查找来查询,b用不到索引。
2.3 like索引失效原理
where name like "a%"
where name like "%a%"
where name like "%a"
我们先来了解一下%的用途
- %放在右边(即“a%”),代表查询以"a"开头的数据,如:abc (有时能用到索引)
- 两个%%(即“%a%”),代表查询数据中包含"a"的数据,如:cab、cba、abc (不能用到索引)
- %放在左边(即“%a”),代表查询以"a"为结尾的数据,如cba (不能用到索引)
原理是:
例如 一棵B+树存储的字符串如下:
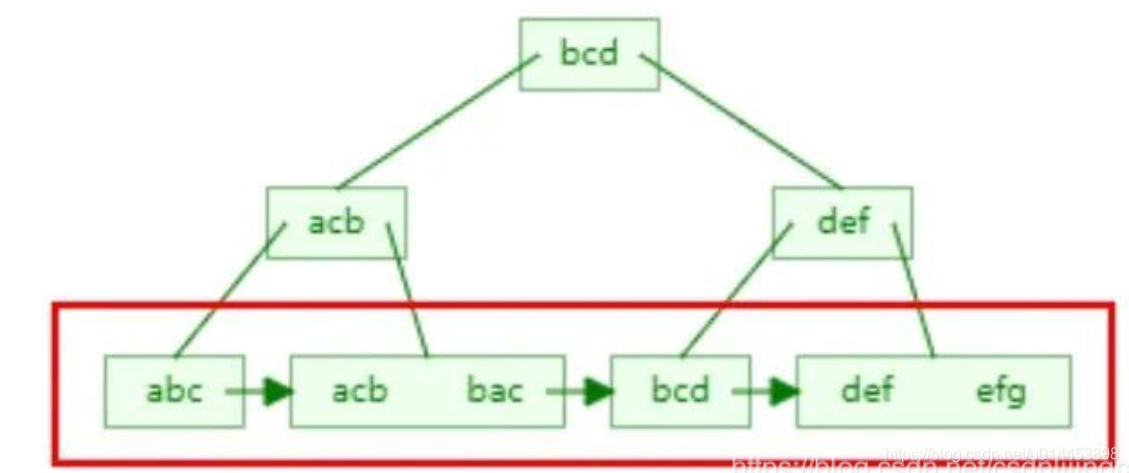
字符串的排序方式(红框处): 先按照第一个字母排序,如果第一个字母相同,就按照第二个字母排序。。。以此类推
开始分析
一、%号放右边
由于B+树的索引顺序,是按照首字母的大小进行排序,前缀匹配又是匹配首字母。所以可以在B+树上进行有序的查找,查找首字母符合要求的数据。所以有些时候可以用到索引。
二、%号放左边
是匹配字符串尾部的数据,我们上面说了排序规则,尾部的字母是没有顺序的,所以不能按照索引顺序查询,就用不到索引。
三、两个%%号
这个是查询任意位置的字母满足条件即可,只有首字母是进行索引排序的,其他位置的字母都是相对无序的,所以查找任意位置的字母是用不上索引的。
三、实战
OK,懂上面的基础,我们就可以开始扯了~举了经典的五大题型,看完基本就懂!
题型一
如果sql为
select * from table where a = 1 and b = 2 and c = 3;
如何建立索引?
如果此题回答为对(a,b,c)建立索引,那都可以回去等通知了。 此题正确答法是,(a,b,c)或者(c,b,a)或者(b,a,c)都可以,重点要的是将区分度高的字段放在前面,区分度低的字段放后面。像性别、状态这种字段区分度就很低,我们一般放后面。
例如假设区分度由大到小为b,a,c。那么我们就对(b,a,c)建立索引。在执行sql的时候,优化器会 帮我们调整where后a,b,c的顺序,让我们用上索引。
题型二
如果sql为
select * from table where a>1 and b=2;
如何建立索引?
如果此题回答为对(a,b)建立索引,那都可以回去等通知了。 此题正确答法是,对(b,a)建立索引。如果你建立的是(a,b)索引,那么只有a字段能用得上索引,毕竟最左匹配原则遇到范围查询就停止匹配。 如果对(b,a)建立索引那么两个字段都能用上,优化器会帮我们调整where后a,b的顺序,让我们用上索引。
题型三
如果sql为
select * from table where a>1 and b=2 and c>3;
如何建立索引? 此题回答也是不一定,(b,a)或者(b,c)都可以。
题型四
select * from table where a=1 order by b;
如何建立索引? 这还需要想?一看就是对(a,b)建索引,当a = 1的时候,b相对有序,可以避免再次排序!
题型五
select * from table where a in (1,2,3) and b>1;
如何建立索引?
还是对(a,b)建立索引,因为IN在这里可以视为等值引用,不会中止索引匹配,所以还是(a,b)!
引用参考:
https://blog.csdn.net/csdnlijingran/article/details/109179034

















 4131
4131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









