









1. boolean类型占几个字节?
- 单独使用boolean类型,由于jvm中没有boolean专用的字节码指令,为了方便寻址,使用int数据类型存储boolean。此时,boolean类型占用4 byte
- 对boolean数组访问与修改,将使用byte数组的baload、bastore指令进行操作。此时,boolean类型占用1 byte
2. 一个字符占用多少字节?
- 如果单纯的说java中的char,占用多少字节?
回答: 2 byte,使用unicode编码 - 如果问你,一个字符串的长度是多少?不要回答,有多少个字符就是多少。
回答: 字符串的长度取决于它在内存中占用的UTF-16的代码单元数 - 如何求一个字符串的真实长度?
回答: 可以使用codePointCount()方法
关于内码
-
java中,字符使用unicode 编码,使用UTF-16进行编码
-
所谓的UTF-16编码,是指char或string在内存中的编码方式,被称为内码
-
UTF-16一个代码单元的大小为16 bit,即2 byte
-
通过
string.length()获取字符串长度,实际是获取字符在内存中占用的UTF-16的代码单元数 -
如果一个字符不能使用一个UTF-16代码单元存储,则会使用2个UTF-16代码单元进行存储
-
这会使得,字符串的length并非字符个数,而是实际占用的UTF-16的代码单元数
-
要想直到字符串真实长度,可以使用
codePointCount()方法public static void main(String[] args) { String str1 = "hi,王二,最近可好?"; String str2 = "\uD83D\uDE02"; System.out.println(str1 +"的长度:"+ str1.length()); System.out.println(str2 +"的长度:"+ str2.length()); System.out.println(str2 +"的字符个数(真实长度):"+str2.codePointCount(0, str2.length())); }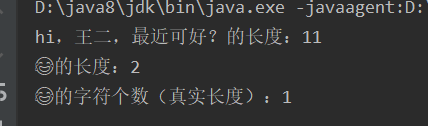
关于外码
-
除了内码,都可以认为是,包括class文件中编码,char或string序列化时使用的字符编码
-
对
string.getBytes(),实际是在做编码转换 (自己认为是将内码转为指定的外码) -
通常情况下,如果
string.getBytes()不指定字符编码,则将使用默认系统编码 -
不同的编码方式,将使得其字节数不一致!
-
linux为 UFT-8,这是一种变长编码,可用占据1~4个byte
-
Windows为gbk —— 但自己的windows系统貌似为 UTF-8 😂
public static void main(String[] args) throws UnsupportedEncodingException { String string = "啥"; System.out.println("gbk编码:" + string.getBytes("gbk").length); System.out.println("utf-8编码:" + string.getBytes(StandardCharsets.UTF_8).length); }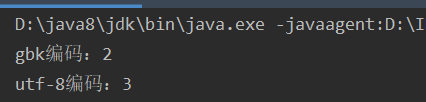
参考大佬博客:
- 面试官问你编码相关的面试题,把这篇甩给他就完事!
- Java中一个字符占两字节 但为什么new String(“字”).getBytes().length 返回3个字节
- 美团面试官问我一个字符的String.length()是多少,我说是1,面试官说你回去好好学一下吧
- 面试官让我讲讲Unicode,我讲了3秒说没了,面试官说你可真菜
3. 包装类型
-
每种基本数据类型,都有对应的包装类型
-
基本数据类型和包装类型之间的赋值,是装箱与拆箱的过程
-
以int和Integer为例
Integer x = 21; // 装箱,自动调用Integer.valueOf() int y = x; // 拆箱,自动调用x.intValue() -
Integer类型存在缓存池,在缓存池范围内的数值,多次调用
Integer.valueOf()会获得同一个Integer对象的引用public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); } -
因此,多次通过装箱、基于12创将的Integer将会是同一对象。
-
一旦重新装箱,将生成新的Integer对象
public static void main(String[] args) throws UnsupportedEncodingException { Integer int1 = 12; Integer int2=12; System.out.println(int1 == int2); int1 = 24; System.out.println(int1 == int2); }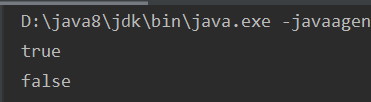
-
其他包装类型也存在缓存池:boolea、byte、char、short、int
4. string为什么不可变?不可变的好处
不可变的原因
-
String类被
final修饰,表示其不可以被继承 —— 包装类也无法被继承 -
String的2个重要的成员变量:
(1)private final修饰的char数组value,且无对应的方法可以修改value。说明其值一旦初始化,则无法改变1、原本char数组作为引用类型,被final修饰后其引用的地址不可变,数组中元素是可变的。
2、使用private修饰char数组,且未提供任何修改接口,因此一旦初始化,则无法改变。(2)String缓存了自身的hashCode,因为String不可变,其hashCode也不会变,只需要计算一次即可 —— String适合用做HashMap中的key
(3)java 9开始,使用byte数组存储string的内容,使用coder表示byte数组的编码方式/** The value is used for character storage. */ private final char value[]; /** Cache the hash code for the string */ private int hash; // Default to 0 /** use serialVersionUID from JDK 1.0.2 for interoperability */ private static final long serialVersionUID = -6849794470754667710L;
String不可变的好处
- 可以缓存hash值: hashCode只需计算一次,可以在内部缓存hash值,适合用做HashMap的key
- 线程安全: String的不可变性,使其天生具有线程安全性。多线程只能读String,无法写String
- 安全性: String作为参数传递,外部方法无法改变String,避免了安全问题。例如,网络url作为参数的情况
- String Pool的实现基础: jvm的堆中,有一块空间用于存储字符串字面量,叫String poo,用于缓存字符串l。只有String不可变,才能使用String pool
String pool
- 两次通过
Str = "aaa",创建的字符串,实际指向同一引用 str.intern()方法,会检查String pool中是否存在相等的字符串。存在,则返回字符串的引用;否则,先将字符串存入String pool,再返回一个新的引用new String("123"),实际创建了2个字符串对象:第一个是指向String Pool中字符串字面量,第二个是通过new在堆中新建的字符串对象
String、StringBuffer、StringBuilder
- String 不可变,其他可变
- StringBuffer线程安全,其方法使用
synchronized进行修饰 - StringBuilder非线程安全
5. static与final
- 之前的总结博文:Java的三大特性、抽象与接口、static和final关键字
static
- static表示全局的,是类公有的变量或方法
- 静态变量:类第一次加载时,分配内存;初始化与更新的时机;访问方式;目的:可以在类的实例中共享数据
- 静态语句块:类第一次加载时执行;静态变量、静态语句块的执行顺序与声明的先后顺序有关
- 静态方法:类第一次加载时就存在,不依赖于任何实例 —— 不能使用
this或super关键字;只能访问静态变量或静态方法 - 静态类:必须作为内部类
- 实例变量:类实例化时创建,与对象同生共死;
- 实例方法:可以访问静态变量/方法、实例变量/方法
- 初始化顺序:父类静态变量/语句块、子类的静态变量/语句块、父类的实例变量/普通语句块、父类的构造函数、子类的实例变量/普通语句块、子类的构造函数
final
- final表示最终的,即一旦初始化,就无法改变
- final变量:初始化的时机;基本数据类型/引用类型,不可变的含义
- final方法:不能被子类重写,但能继承;private修饰的方法,默认为final
- final类:不能被子类继承,其中的变量具有与普通类变量一样的属性,方法都默认为final方法(即无法重写)
static final
- 修饰的变量,必须在定义时初始化,或在静态语句块中初始化
- 原因:static final表示全局不可变,必须在类加载时完成初始化,才能保证全局不可变
6. ==、equals()与hashCode()
- 之前总结的博文:java的浅拷贝与深拷贝、hashCode、equals、==
==
- 对于基本数据类型,判断值是否相等
- 对于引用类型,判断是否指向同一对象
equals()
-
只有引用类型才有equals()方法,用来用来判断两个对象是否等价
-
两个对象等价:
- ① 为同一对象;② 非同一对象,但两者数据类型相同且值相等
- String类的
equals()方法,就是这样判断两个字符串是否相等的
-
Object类规定equals()方法具有如下特性:
- 自反性、对称性、传递性、一致性(多次调用,判断结果一致)、非空性(与null的比较)
-
Object类的
equals()方法,只是简单地判断是否为同一对象public boolean equals(Object obj) { return (this == obj); } -
注意:
- 一般情况下,两个对象相等是指equals()方法为true
- 两个对象等价,要求对象的hash code也要相同。因此,一般重写类的
equals()方法时,也应该重写其hashCode()方法。
hashCode()
- hashCode()用于计算对象的hash code,Object类中的对hashCode()方法的约定如下:
- 幂等性:同一个程序中,多次调用对象的hashCode() 方法应该返回相等的hash code
- 两个对象相等,即equals()方法返回true,则这两个对象的hashCode()方法返回的hash code相等
- hashCode()方法的返回值相等,两个对象不一定相等,即equals()方法不一定返回true(存在hash碰撞)
- hash code的散列程度决定性了哈希表的性能,建议开发者尽量让相等的对象拥有不同的hash code
- JDK HashMap源码,使用如下方法判断两个key是否相等
if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) - 具体分析可以参考博客:HashSet学习(基于JDK 1.8)
疑问: 为何重写了equals()方法 ,一定要重写hashCode()方法?
- 不仅违反了JDK中hashCode()方法的约定(相等的对象拥有相等的hash code),还将影响哈希表中的元素的定址
- 具体解释可以参考博客:HashSet学习(基于JDK 1.8)
7. 浅拷贝与深拷贝
- 浅拷贝: 基本数据类型,值传递;引用类型,引用传递的拷贝。例如:常见的通过
=的赋值操作

- 深拷贝: 基本数据类型,值传递;引用类型,创建新对象并复制其内容
Object中的clone()方法
- clone()方法属于Object的
protected native方法,其他类必须要重写该方法,才能使用clone()方法 - 重写clone()方法,要求必须实现
Cloneable接口,否则会抛出CloneNotSupportedException异常 - clone()满足的特性
① 对任何的对象x,都有x.clone() != x—— 拷贝对象与原对象不是同一个对象
② 对任何的对象x,都有x.clone().getClass() == x.getClass()—— 拷贝对象与原对象的类型一样
③ 如果对象x的equals()方法定义恰当,那么x.clone().equals(x)应该成立。
浅拷贝的实现
- 重写clone()方法,在clone()方法中,访问super.clone()即可
深拷贝的实现
- 基于clone()方法:拷贝对象、原始对象的引用类型,使他们引用不同的对象。
注意: String的特殊性,无需对String单独进行clone操作。一旦重新赋值,会新建String对象,引用自动断开 - 使用Apache Commons Lang中的
SerializationUtils.clone()方法,基于序列化实现深拷贝 - 如需深入,可以学习以下内容
Java如何对一个对象进行深拷贝?
Java深拷贝和浅拷贝















 1596
1596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









