







1. 什么是浅拷贝与深拷贝?
① java中的数据类型及赋值
- 在 Java 中,除了
基本数据类型之外,还存在类的实例(引用数据类型)。 - 一般使用
=号做赋值操作的时候,对于基本数据类型,实际上是拷贝它的值;对于引用数据类型而言,其实赋值的只是这个对象的引用,将原对象的引用传递过去,原对象和新的对象实际上还是指向同一个对象。 - 浅拷贝和深拷贝就是在这个基础之上做的区分:
- 如果在拷贝这个对象的时候,只对基本数据类型进行了拷贝,而对
引用数据类型只是进行了引用传递,而没有真实的创建一个新的对象,则认为是浅拷贝。 - 反之,在对引用数据类型进行拷贝的时候,创建了一个新的对象(分配了新的内存),并且复制其内的成员变量,则认为是深拷贝。
总结:
- 深拷贝和浅拷贝只是在拷贝一个对象的时候,其中的引用数据类型是进行的引用传递,还是进行内存的分配?
- 深拷贝相比于浅拷贝速度较慢并且花销较大。
② 浅拷贝
- 浅拷贝: 对
基本数据类型进行值传递,对引用数据类型进行引用传递的拷贝,此为浅拷贝。
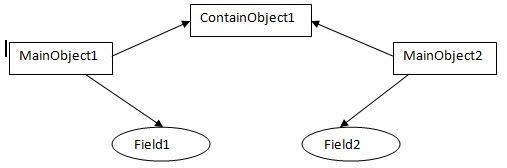
- 由上图可知,拷贝后,int类型的属性
field1将值拷贝给了新的变量field2;引用数据类型的属性ContainedObject1只是进行了引用传递。如果在新的对象MainObject2中更改ContainedObject1的某个属性的值,之前的对象MainObject1中ContainedObject1的某个属性的值也会发生变化。
③ 深拷贝
- 深拷贝: 对
基本数据类型进行值传递,对引用数据类型创建一个新的对象,并复制其内容(分配新的内存),此为深拷贝。

- 由上图可知,拷贝后,int类型的属性
field1将值拷贝给了新的变量field2;引用数据类型的属性ContainedObject1只是进行了深拷贝:新建一个ContainedObject2对象,并对ContainedObject1的内容进行了。如果在新的对象MainObject2中更改ContainedObject2的某个属性的值,之前的对象MainObject1中ContainedObject1的某个属性的值不会发生变化。
2. Java实现对象的深拷贝和浅拷贝
① 浅拷贝的实现
-
创建课程类
public class Subject { private String name; public Subject(String s) { name = s; } public String getName() { return name; } public void setName(String s) { name = s; } } -
创建学生类,属性有姓名和课程。该类实现了
cloneable接口,重写clone方法实现了浅拷贝。public class Student implements Cloneable { // 对象引用 private Subject subj; private String name; public Student(String s, String sub) { name = s; subj = new Subject(sub); } public Subject getSubj() { return subj; } public String getName() { return name; } public void setName(String s) { name = s; } /** * 重写clone()方法 * @return */ public Object clone() { //浅拷贝 try { // 直接调用父类的clone()方法,新建了Student对象 // 但对象中的成员变量还是与父对象一致,因此为浅拷贝 return super.clone(); } catch (CloneNotSupportedException e) { e.printStackTrace(); return null; } } } -
创建学生类实例,使用并探索浅拷贝。
public static void main(String[] args) { Student stu1 = new Student("lucy", "math"); Student stu2 = (Student) stu1.clone(); System.out.println("拷贝后的对象与原对象是否为同一对象:" + (stu1 == stu2)); System.out.println("原对象的hashCode:" + stu1.hashCode() + ",拷贝后的对象的hashCode:" + stu2.hashCode()); System.out.println("name属性是否一样:" + (stu1.getName() == stu2.getName())); System.out.println("subject属性是否一样:" + (stu1.getSubject() == stu2.getSubject())); // String作为引用类型很特殊,每次赋值以后都是返回的是新的引用 stu2.setName("grace"); stu2.getSubject().setName("Chinese"); System.out.println("name属性是否一样:" + (stu1.getName() == stu2.getName())); System.out.println("stu1.name=" + stu1.getName()+", stu2.name="+stu2.getName()); System.out.println("subject属性是否一样:" + (stu1.getSubject() == stu2.getSubject())); System.out.println("stu1.subject.name=" + stu1.getSubject().getName()+ ", stu2.subject.name=" +stu2.getSubject().getName()); } -
运行结果截图:

-
浅拷贝确实
创建了一个新的对象,但是对象内部的属性为引用数据类型时,只是进行了引用传递。更改引用数据类型,原对象和新对象中该属性的值都会发生变化。 -
特殊: String类型在拷贝后确实发生的是引用传递。但是一旦对String类型的属性重新赋值,该属性的引用变量将会指向新的内存区域。这样就会导致原对象和新对象的name属性不一致,这也是为什么第二次判断那么属性时,它们不相等。
-
原因: String 类型很特殊,它是
不可变类型,即一旦初始化后,就不可以改变。String引用的值为常量,改变克隆出来的对象的值,实际上是改变了克隆出来对象的引用,不会影响父对象的。
② 深拷贝的实现
-
之前的课程类需要实现
Cloneable接口:@Override protected Object clone() { try { return super.clone(); } catch (CloneNotSupportedException e) { e.printStackTrace(); return null; } } -
在学生的拷贝中,进行深拷贝。
注意: 由于String类型的特殊性,没必要对String类型进行深拷贝处理。
- 深拷贝就是为了避免引用传递,导致一个对象的更新,连坐另一个对象。
- String的更新,会新建一个String对象,其引用发生更新,不影响原本的String对象。
@Override protected Object clone() { try { Student stu = (Student)super.clone(); // clone实质是新建一个对象,通过更新subject变量,使其指向新的clone对象 // 这是一种深拷贝处理 stu.subject = (Subject)subject.clone(); return stu; } catch (CloneNotSupportedException e) { e.printStackTrace(); return null; } } - 还有一种通过
序列化的方式实现深拷贝,不做学习! - 深拷贝探索结果如下,发现深拷贝后的subject属性,在新对象中发生改变不会影响原对象。即
拷贝前后的subject对象指向不同的内存区域。

3. equals方法
① 关于==
- 对于基本类型,
==判断两个值是否相等,基本类型没有 equals() 方法。 - 对于引用类型,
==判断两个变量是否引用同一个对象,而equals() 判断引用的对象是否等价。
② 关于equals方法
-
equals()方法 是用来判断其他的对象是否和该对象相等,更具体确切的说是
二者是否等价. -
equals()方法在object类中定义如下:equals,只是简单的判断两个对象是否为同一对象,即二者的引用是否相同。
public boolean equals(Object obj) { return (this == obj); } -
String 、Math、Integer、Double等这些封装类在使用
equals()方法时,已经覆盖了object类的equals()方法。 -
String类的
equals()方法如下:
① 相比较二者是否为同一对象,是同一对象一定相等。
② 接着两个对象类型是否相同、值是否相等;如果满足这两个条件,这两个对象就是相等的。public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }
③ equals的性质(覆写equals时有哪些准则?)
- 自反性(reflexive): 对于任意不为null的引用值x,
x.equals(x)一定是true。 - 对称性(symmetric): 对于任意不为null的引用值x和y,当且仅当
x.equals(y)是true时,y.equals(x)也是true。 - 传递性(transitive): 对于任意不为null的引用值x、y和z,如果
x.equals(y)是true,同时y.equals(z)是true,那么x.equals(z)一定是true。 - 一致性(consistent): 对于任意不为null的引用值x和y,如果
用于equals比较的对象信息没有被修改的话,多次调用时x.equals(y)要么一致地返回true要么一致地返回false。 - 非空性: 对于任意不为null的引用值x,
x.equals(null)返回false。 - 注意: 当
equals()方法被override时,hashCode()也要被override。按照一般hashCode()方法的实现来说,相等的对象,它们的hashCode一定相等。
4. hashCode
① 关于hashCode
- Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为
散列值。 - Object类中的hashCode方法定义如下:
public native int hashCode();
- hashcode的特性:
① hashCode的存在主要是用于查找的快捷性:如Hashtable,HashMap等,hashCode是用来在散列存储结构中确定对象的存储地址。
② 在一个Java应用的执行期间,如果一个对象提供给equals做比较的信息没有被修改的话,该对象多次调用hashCode()方法,该方法必须始终如一返回同一个integer。
③ 如果两个对象根据equals(Object)方法是相等的,那么调用二者各自的hashCode()方法必须产生同一个integer结果。 —— 即等价的两个对象,应该具有相同的hashCode
④ 两个对象的hashCode相同,并不一定表示两个对象就等价,即不一定适用于equals(java.lang.Object)方法。只能够说明这两个对象在散列存储结构中的存储位置相同,如在HashMap中他们存在于同一个桶中。
② 如何使用hashCode的?
- 哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上。当集合要添加新的元素时,先调用这个元素的HashCode方法,就一下子能定位到它应该放置的物理位置上。
① 如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;
② 如果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了;
③ 不相同的话,也就是发生了Hash key相同导致冲突的情况,那么就在这个Hash key的地方产生一个链表,将所有产生相同HashCode的对象放到这个单链表上去,串在一起。
③ HashMap的拉链原理
- 这是hashCode使用的经典例子,参考之前的总结。















 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









