







 本文介绍了如何将大数据集划分成若干子集,并对每个子集进行聚类分析。为了确保聚类结果的准确性,需要保证每个子集的数据分布相似。文章提出了一种称为“K-均值距离法”的聚类算法,能够有效地解决数据分布不均匀的问题。本篇文章主要介绍了如何将大数据集划分成若干子集,并对每个子集进行聚类分析。在进行子集划分时,需要保证每个子集的数据分布相似,以保证聚类结果的准确性。文章介绍了一种称为“K-均值距离法”的聚类算法,可以有效地解决数据分布不均匀的问题。
本文介绍了如何将大数据集划分成若干子集,并对每个子集进行聚类分析。为了确保聚类结果的准确性,需要保证每个子集的数据分布相似。文章提出了一种称为“K-均值距离法”的聚类算法,能够有效地解决数据分布不均匀的问题。本篇文章主要介绍了如何将大数据集划分成若干子集,并对每个子集进行聚类分析。在进行子集划分时,需要保证每个子集的数据分布相似,以保证聚类结果的准确性。文章介绍了一种称为“K-均值距离法”的聚类算法,可以有效地解决数据分布不均匀的问题。
本文从聚类数据量大入手,先将将全量数据集随机分成若干个子数据集,然后对每一个子数据集进行聚类算法。
其中,每个子数据集可以同等规模(数据量相等),也可以规模不相等。但是每个子数据集的K值和聚类算法要保持一致,因为不同的K值会导致质心个数不一致最终没办法合并,而聚类算法如果不相同会导致每个子数据集的类簇之间没有可比性。
1. 系统框架

图1 加权质心聚类在线学习方法框架图
本文将传统聚类的全量数据聚类分解成若干个子数据集进行子聚类,每个子聚类的数据样本不重叠,数据总量等于全量数据,每个子数据集数据量可以相等也可以不相等。对于每个子聚类采用相同的聚类算法进行计算,为保证子聚类最终质心可以合并,因此要保证每个子聚类的K值相同。
为了保证子聚类拥有相同K值,因此需要保证各个子集的数据分布是相似的,所以在整体数据采样生成子集数据集时采用随机采样的方式,具体做法可以使用Hive的rand()方法或python的StratifiedShuffleSplit()方法实现随机采样。因为数据集要分割成若干个数据子集,因此随机采样需要满足随机无放回采样,即每个样本只能出现在一个子集中。
通过以上采样方式可以得到若干个分布相似的子数据集,对每个子集进行聚类足以保证每个子集的K值相等。
当前已经保证了各个子集的分布是相似的,因此各子集的最优K值也是相同的,因此只要随机取其中一个子集获取最优K值即可应用于其它各个子集。
为了实现算法自动计算并选取最优K值,相对于肘部法而言,我们采用更佳清晰
的Gap Statistic方法。Gap Statistic的定义为:
![]()
式1 子聚类最优K值选取
这里的Dk即是手肘法计算距离的公式:
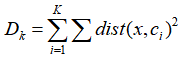
式2 手肘法距离计算
这里
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











