






基础智能体的进展与挑战综述
从类脑智能到具备可进化性、协作性和安全性的系统
【翻译团队】刘军(liujun@bupt.edu.cn) 钱雨欣玥 冯梓哲 李正博 李冠谕 朱宇晗 张霄天 孙大壮 黄若溪
- 智能体自我改进
在追求自我提升的过程中,智能智能体将优化视为一种机制,用于精炼各个组成部分——如提示设计、工作流编排、工具使用、奖励函数调整,甚至是优化算法本身——同时也将其作为一个战略框架,以确保这些个体改进能够协调一致地提升整体性能。例如,若将奖励函数与提示设计分别优化,可能会产生相互冲突的结果,但通过战略性的方法可以使这些优化过程协同进行,从而保持一致性并最大化整体效果。我们将智能体的自我进化划分为两种主要范式:在线自我改进与离线自我改进。此外,我们还探讨了一些混合优化策略,这些策略结合了两种方法的优势,以实现更高的效率与适应性。
11.1 在线智能体自我改进
在线自我改进指的是实时优化,智能体根据即时反馈动态调整自身行为。这一范式通过持续优化关键性能指标(如任务成功率、延迟、成本和稳定性)使智能体能够对不断变化的环境保持响应能力,形成一个迭代反馈闭环。在线自我改进在需要动态适应性的应用中尤为有效,例如实时决策、个性化用户交互和自动化推理系统。在线自我改进中的关键优化策略可以分为以下四类:迭代反馈与自我反思、多智能体系统中的主动探索、实时奖励塑造、动态参数调优。
-
迭代反馈与自我反思 这类方法[48, 67, 72, 70, 847, 47]使智能体能够对自身输出进行批评和迭代改进。Reflexion[48]、Self-Refine[67]和 Tree of Thoughts[72]引入了自我批评循环,模型可以实时识别错误并提出修改建议。ReAct[70]将链式思维的“推理”与“行动”结合,在获得外部反馈后迭代修正步骤。其他方法则依赖自洽性[78]选择最一致的方案,或利用过程奖励模型(PRM)Lightman 等人提出的方法[847]从多个候选中选出最佳解。这些方法无需离线微调,有助于减少误差传播并实现快速适应。
-
多智能体系统中的主动探索 这些方法[626, 848, 627, 152]鼓励在多智能体系统中进行主动探索与动态搜索,以发现新的模式与工作流改进方式。MetaGPT[626]、CAMEL[848]和 ChatDev[627]展示了多角色或多智能体协作系统,它们通过实时交互不断反馈和优化彼此的输出。类似地,HuggingGPT[152]通过中心化的LLM控制器协调Hugging Face上的各个专用模型,动态分配任务并收集反馈。这些策略说明,智能体间的在线更新能够逐步优化整体系统性能。
-
实时奖励塑造 与其依赖固定或纯离线定义的奖励函数,一些框架[731, 91, 105, 849]集成了即时反馈信号,不仅用于纠错,也用于动态调整内部奖励函数与策略。这种方式使智能体能根据用户交互过程中的变化自适应地校准奖励机制,在性能、计算成本与延迟之间进行权衡,从而实现动态优化。
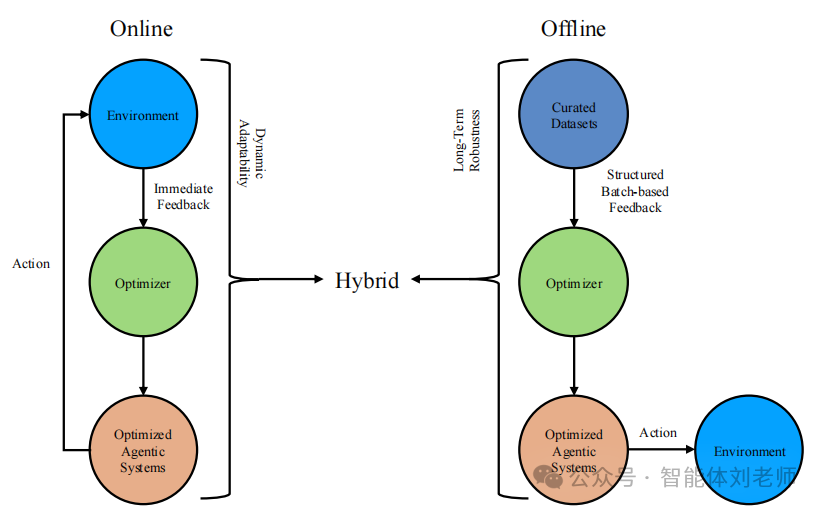
图 11.1:展示了三种不同使用场景下的自我改进方式,包括在线、离线和混合自我改进。
-
动态参数调优 在这一类别中,智能体会实时自主更新其内部参数(包括提示模板、工具调用阈值、搜索启发式等),采用无梯度或近似梯度的方法。这些更新既优化了计算效率,又提升了决策准确性,使智能体能够无缝适应不断变化的上下文。Self-Steering Optimization(SSO)[850]通过在迭代训练过程中自动生成偏好信号,消除了对人工标注的依赖,同时保持信号准确性和训练过程的on-policy特性。
在线自我改进促进了一个不断演化的智能体框架,在任务执行过程中嵌入学习过程,从而增强实时适应性、以用户为中心的优化能力以及强大的问题解决能力。
11.2 离线智能体自我改进
与在线方法相对,离线自我改进依赖结构化的、批量式优化。该范式通过预定的训练周期和高质量的精 curated 数据集来系统性地提升智能体的泛化能力[851, 667, 852, 853, 854]。与在线方法相比,离线方法适用于更高计算开销的技术,包括批量参数更新与微调、元优化以及系统化的奖励模型校准。
-
批量参数更新与微调(Batch Parameter Updates and Fine-Tuning):在这一类别中,智能体通过监督学习或强化学习(RL)方法进行大规模微调,在多个训练周期中优化在大数据集上的表现。常见的方法如检索增强生成(RAG),常被用于提升上下文理解和长期记忆检索能力[740, 741]。这些方法使智能体能够优化其检索策略,从而提升在大规模知识语料上的推理能力。
-
元优化(Meta-Optimization of Agent Components):离线训练不仅用于提升任务性能,还用于优化智能体的优化算法本身。元学习策略能够优化超参数,甚至动态重构优化流程,取得了有前景的结果[731, 91]。这些元优化方法使智能体能够为新问题领域发现最有效的学习参数。
-
系统化的奖励模型校准(Systematic Reward Model Calibration):离线环境有助于对奖励模型进行精确校准,常通过分层或列表式奖励集成框架(如 LIRE[855])实现。这些框架通过基于梯度的奖励优化,使智能体行为与长期目标保持一致。此类校准确保奖励函数能够真实反映任务的复杂性,从而减少偏差并提升泛化能力。
离线优化的结构化特性有助于构建稳健的智能体基线,其性能在实际部署前已通过稳定性、效率与计算成本等方面的微调得以优化。离线训练支持高保真度的模型精修,对于要求可预测性能保障的关键任务型应用至关重要。
11.3 在线与离线自我改进的比较
在线与离线优化各具优势,在自我改进的不同方面表现出色。在线优化在动态环境中表现突出,能够借助实时反馈持续适应。它适用于需要即时响应的场景,如交互式智能体、实时决策系统和强化学习系统。然而,频繁更新也可能引入不稳定性或性能漂移,因此需设计机制以缓解长期性能下降的问题。相比之下,离线优化强调结构化的、高保真的训练方式,基于预先收集的数据集,确保在部署前具备稳健和稳定的性能。通过批量训练、微调和元优化等高计算开销的学习方法,离线方法提供了良好的泛化能力和长期一致性。但其缺乏在线学习的灵活性,若遇到新场景则可能难以高效适应,除非进行额外的再训练。表 11.1 总结了这两种范式之间的主要区别。
表 11.1:在线与离线优化策略在自我改进智能体中的比较
| 特征 | 在线优化 | 离线优化 |
| 学习过程 | 基于实时反馈的持续更新 | 在预定训练阶段进行批量更新 |
| 适应能力 | 高,能够动态调整 | 较低,仅在再训练后适应 |
| 计算效率 | 对于增量更新更高效 | 由于批量训练,资源消耗更大 |
| 数据依赖性 | 依赖实时数据流 | 依赖精心整理的高质量数据集 |
| 过拟合风险 | 较低,因持续学习而避免 | 较高,若训练数据不具多样性 |
| 稳定性 | 潜在不稳定,因频繁更新可能引入波动 | 更稳定,因训练设置可控 |
尽管在线与离线优化各自具有固有的优势与权衡,现代智能系统正越来越多地通过混合优化策略将二者整合。这些混合框架既利用了离线训练的稳定性,又融合了实时适应能力,使智能体能够在动态环境中持续优化自身表现的同时,保持长期的稳健性。
11.4 混合方法
鉴于在线与离线方法各自存在固有限制,许多当代系统采用了混合优化策略。这些混合方法将结构化的离线优化与响应式的在线更新相结合,实现智能体能力的持续渐进式增强。混合优化明确支持自我改进,使智能体能够在不同但相互关联的阶段中自主评估、适应并增强自身行为:
-
离线预训练:在这一基础阶段,智能体通过在精心整理的数据集上进行大规模离线训练,获得稳健的初始能力。此阶段为后续的自主性能奠定必要技能,如推理与决策。例如,Schrittwieser 等人提出的框架[856]展示了离线预训练如何系统性地增强智能体的初始能力,确保后续在线改进建立在稳定基础之上。
-
在线微调以实现动态适应:智能体通过自主评估自身表现、识别不足,并根据实时反馈动态调整策略,来主动优化自身能力。该适应性微调阶段直接契合智能体自我改进的范式,实现对智能体特定工作流与行为的实时优化。以 Decision Mamba-Hybrid(DM-H)[857]为例,智能体能够高效适应复杂、多变的场景。
-
为长期改进进行周期性离线整合:在周期性离线整合阶段,智能体会系统性地整合并固化在线交互过程中获得的改进。这确保了逐步获取的技能与优化被纳入智能体的核心模型中,从而维持长期的稳定性与有效性。Uni-O4 框架[858]是这一过程的代表,展示了离线知识整合与在线自适应优化之间的无缝衔接方式。
因此,混合优化通过将结构化的离线学习与积极的实时在线适应紧密结合,明确支持智能体的自主、持续进化。这种循环式的方法为智能体赋予了即时响应能力与稳定的长期改进能力,使其非常适用于复杂的现实场景,如自主机器人、个性化智能助手和交互式系统。
【往期回顾】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









