









ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing

https://arxiv.org/pdf/2412.14711
https://github.com/thu-ml/ReMoE
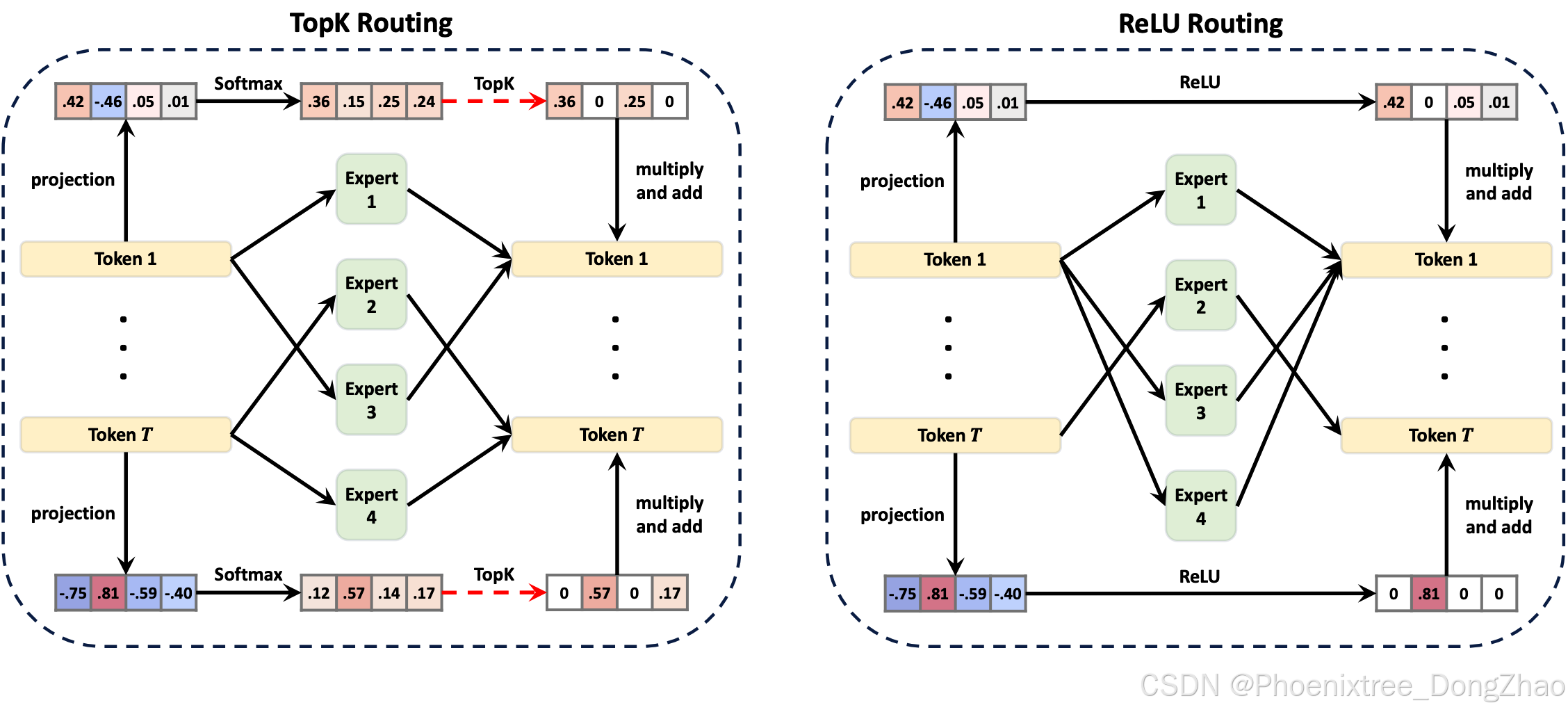
Figure 1: Compute flows of vanilla MoE with TopK routing and ReMoE with ReLU routing. Positive values are shown in orange, and negative values in blue, with deeper colors representing larger absolute values. Zeros, indicating sparsity and computation savings, are shown in white. The red dash arrows in TopK routing indicate discontinuous operations. Compared with TopK routing MoE, ReMoE uses ReLU to make the compute flow fully differentiable.
Abstract
Sparsely activated Mixture-of-Experts (MoE) models are widely adopted to scale up model capacity without increasing the computation budget. However, vanilla TopK routers are trained in a discontinuous, non-differentiable way, limiting their performance and scalability. To address this issue, we propose ReMoE, a fully differentiable MoE architecture that offers a simple yet effective drop-in replacement for the conventional TopK+Softmax routing, utilizing ReLU as the router instead. We further propose methods to regulate the router’s sparsity while balancing the load among experts. ReMoE’s continuous nature enables efficient dynamic allocation of computation across tokens and layers, while also exhibiting domain specialization. Our experiments demonstrate that ReMoE consistently outperforms vanilla TopK-routed MoE across various model sizes, expert counts, and levels of granularity. Furthermore, ReMoE exhibits superior scalability with respect to the number of experts, surpassing traditional MoE architectures.
稀疏激活的混合专家模型(MoE)被广泛用于在不增加计算预算的情况下扩展模型容量。 然而,传统的TopK路由以非连续且不可微的方式进行训练,限制了其性能和可扩展性。 为了解决这一问题,我们提出了ReMoE,一种完全可微的MoE架构,提供了一个简单但有效的替代方案,用ReLU路由取代传统的TopK+Softmax路由。 我们进一步提出了调节路由器稀疏性并平衡专家负载的方法。ReMoE的连续性使其能够高效地动态分配跨token和层的计算资源,同时表现出领域专业化能力。 我们的实验表明,ReMoE在各种模型规模、专家数量和粒度级别上始终优于传统的TopK路由MoE。 此外,ReMoE在专家数量增加时表现出更强的可扩展性,超越了传统MoE架构。
Introduction
Transformer models (Vaswani, 2017) consistently improve performance as the number of parameters increases (Kaplan et al., 2020). However, scaling these models is constrained by computation resources. Sparsely activated Mixture-of-Experts (MoE) (Shazeer et al., 2017) mitigates this challenge by employing a sparse architecture that selectively activates a subset of parameters during both training and inference. This conditional computation allows MoE models to expand model capacity without increasing computational costs, offering a more efficient alternative to dense models.
The key component in MoE is the routing network, which selects the experts to activate for each token. Various routing methods (Shazeer et al., 2017; Lewis et al., 2021; Roller et al., 2021; Zhou et al., 2022) have been proposed, with TopK routing (Shazeer et al., 2017) being the most commonly adopted. However, the vanilla TopK router introduces a discrete and non-differentiable training objective (Shazeer et al., 2017; Zoph et al., 2022), limiting the performance and scalability.
Recent works on fully-differentiable MoE aim to overcome this limitation. Soft MoE (Puigcerver et al., 2023) introduces token merging, while SMEAR (Muqeeth et al., 2023) proposes expert merging. However, both approaches break token causality, making them unsuitable for autoregressive models. Lory (Zhong et al., 2024) improves upon SMEAR and is applicable to autoregressive models. But it underperforms vanilla MoE with TopK routing.
In this work, we address the discontinuities by introducing ReMoE, an MoE architecture that incorporates ReLU routing as a simple yet effective drop-in replacement for TopK routing. Unlike TopK routing, which computes a softmax distribution over the experts and calculates a weighted sum of the largest K experts, ReLU routing directly controls the active state of each expert through a ReLU gate. The number of active experts is determined by the sparsity of the ReLU function. To maintain the desired sparsity, we propose adding a load-balancing refined L1 regularization to the router outputs, with an adaptively tuned coefficient. This approach ensures that ReMoE maintains the same computational costs as TopK-routed MoE.
Compared to TopK routing, ReLU routing is continuous and fully differentiable, as the ReLU function can smoothly transition between zero and non-zero values, indicating inactive and active. Besides, ReLU routing manages the “on/off” state of each expert independently, offering greater flexibility. Moreover, the number of activated experts can vary across tokens and layers, enabling a more efficient allocation of computational resources. Further analysis reveals that ReMoE effectively learns to allocate experts based on token frequency and exhibits stronger domain specialization.
Our experiments on mainstream LLaMA (Touvron et al., 2023) architecture demonstrate that ReLU routing outperforms existing routing methods including TopK routing and fully-differentiable Lory. Through an extensive investigation across model structures, we find that ReMoE consistently outperforms TopK-routed MoE across a broad range of active model sizes (182M to 978M), expert counts (4 to 128), and levels of granularity (1 to 64) (Krajewski et al., 2024). Notably, in terms of scaling behavior, we observe that ReMoE exhibits a steeper performance improvement as the number of experts scales up, surpassing traditional MoE models.
Transformer模型(Vaswani, 2017)随着参数数量的增加而持续提升性能(Kaplan等, 2020)。然而,扩展这些模型受到计算资源的限制。 稀疏激活的混合专家模型(Shazeer等, 2017)通过稀疏架构缓解了这一挑战,在训练和推理过程中选择性地激活部分参数。这种条件计算使MoE模型能够在不增加计算成本的情况下扩展模型容量,提供了一种比密集模型更高效的替代方案。
MoE的关键组件是路由网络,它负责为每个token选择要激活的专家。已经提出了多种路由方法(Shazeer等, 2017;Lewis等, 2021;Roller等, 2021;Zhou等, 2022),其中TopK路由(Shazeer等, 2017)是最常用的。然而,传统的TopK路由引入了离散且不可微的训练目标(Shazeer等, 2017;Zoph等, 2022),限制了其性能和可扩展性。
最近关于全可微MoE的工作旨在克服这一限制。Soft MoE(Puigcerver等, 2023)引入了token合并,而SMEAR(Muqeeth等, 2023)提出了专家合并。然而,这两种方法破坏了token因果关系,使其不适合自回归模型。 Lory(Zhong等, 2024)改进了SMEAR,并适用于自回归模型。但它在性能上不如使用TopK路由的传统MoE。
在这项工作中,我们通过引入ReMoE解决了上述不连续性问题,这是一种采用ReLU路由的MoE架构,作为TopK路由的简单但有效的替代方案。 与TopK路由不同,后者通过对专家计算softmax分布并取前K个专家的加权和,ReLU路由通过ReLU门直接控制每个专家的激活状态。 激活的专家数量由ReLU函数的稀疏性决定。为了维持所需的稀疏性,我们提出对路由器输出添加经过优化的L1正则化,并使用自适应调整的系数。 这一方法确保ReMoE保持与TopK路由MoE相同的计算成本。
与TopK路由相比,ReLU路由是连续且完全可微的,因为ReLU函数可以平滑地在零和非零值之间过渡,指示激活或未激活状态。 此外,ReLU路由独立管理每个专家的“开/关”状态,提供了更大的灵活性。 而且,激活的专家数量可以在不同的token和层之间变化,从而实现更高效的计算资源分配。 进一步分析表明,ReMoE能够根据token频率有效地分配专家,并表现出更强的领域专业化能力。
我们在主流LLaMA架构(Touvron等, 2023)上的实验表明,ReLU路由优于现有的路由方法,包括TopK路由和全可微的Lory。 通过对模型结构的广泛研究,我们发现ReMoE在广泛的活跃模型规模(182M到978M)、专家数量(4到128)和粒度级别(1到64)上始终优于TopK路由MoE(Krajewski等, 2024)。 值得注意的是,在扩展行为方面,我们观察到随着专家数量的增加,ReMoE表现出更陡峭的性能提升,超越了传统MoE模型。
总结
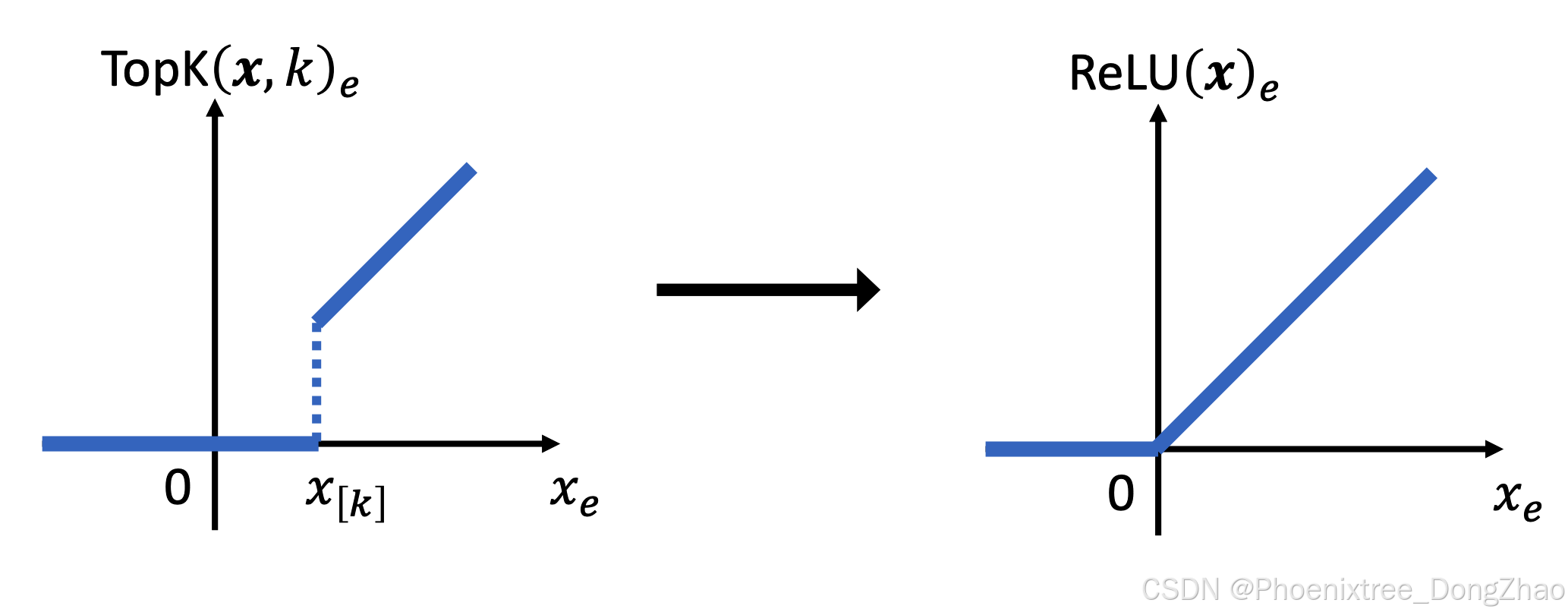
Figure 2: Comparison between TopK and ReLU.
动机
本文的核心动机是解决传统TopK路由在混合专家模型中的两个关键问题:非连续性和不可微性 。这些问题导致模型性能受限,尤其是在大规模模型和多任务场景下的可扩展性不足。
核心思想
作者提出了一种全新的MoE架构——ReMoE ,其核心创新在于将传统的TopK路由替换为基于ReLU的全可微路由机制。ReLU路由不仅解决了非连续性和不可微性问题,还通过稀疏性和灵活的专家激活策略实现了更高效的计算资源分配。
具体方法
- ReLU路由机制 :通过ReLU函数直接控制每个专家的激活状态,避免了TopK路由中复杂的softmax计算。
- 稀疏性与负载均衡 :引入L1正则化来调节路由器输出的稀疏性,并通过自适应系数平衡各专家之间的负载。
- 动态资源分配 :ReLU路由允许激活的专家数量在不同的token和层之间动态变化,从而提高计算效率。
- 领域专业化 :通过分析,ReMoE能够根据token频率自动分配专家,并在特定领域任务中表现出色。
结论
实验结果表明,ReMoE在各种模型规模、专家数量和粒度级别上均优于传统TopK路由MoE。此外,随着专家数量的增加,ReMoE表现出更强的可扩展性,验证了其在大规模应用场景中的优势。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









