- 博客(22)
- 资源 (6)
- 收藏
- 关注
 RSS订阅
RSS订阅
原创 基于Vue+elementUI+django前后端分离员工管理系统
基于Vue+elementUI+django前后端分离员工管理系统不废话上源码链接:https://pan.baidu.com/s/1vTWJLFezQ7XJxaLn6onLrw 提取码:guf0功能简介1、首页与员工列表员工列表页面自动请求后端服务查询所有员工信息。前段代码为:2、查看详细信息3、修改信息4、添加员工信息添加员工信息支持照片添加,工号正则匹配,手机号正则匹配、邮箱匹配等。5、查询功能查询功能知识所有列的信息查找,不需要指定要查找的列。6、批量添加员工
2021-08-17 21:02:14
 1526
1526
 2
2
原创 26个数据分析案例——第三站:基于python的药店销售数据分析
目录26个数据分析案例——第三站:基于python的药店销售数据分析实验环境数据说明必备知识1、数据获取2、数据信息查看3、数据清洗4、数据变换5、数据过滤6、数据保存实验步骤第一步:加载数据并查看数据详情1、导入数据:需要用到Python中的xlrd包,代码如下所示。2、查看数据类型,代码如下所示。第二步:数据清洗1、选择子集:目的是选择需要分析的列,方法为切片法(loc),代码如下所示。2、列名重命名:把'购药时间'改为'销售时间’,代码如下所示。3、缺失数据处理,用dropna 法处理缺失值,处理前数
2021-08-08 15:14:47
11239
6
原创 26个数据分析案例——第一站:基于Python的HBase冠字号查询系统
26个数据分析案例——第一站:基于Python的HBase冠字号查询系统实验所需环境• Python: Python 3.x;• Hadoop 2.7.7环境;• HBase 1.3.5;实验背景针对于人民币的真假识别,最传统的方式就是一看、二摸、三听、四测四种方式,但随着不法分子仿制水平的提高,可能会通过一些技术手段欺骗我们,针对于这种情况我们可以建立一套针对于冠字号管理查询系统进行识别,以唯一的冠字号查询手段,检验真假,冠字号钞票的唯一编号,全世界仅有一个,如果有一个大表可以把所有的人民币以
2021-08-07 10:45:35
2980
2
原创 26个数据分析案例——第五站:基于Scrapy的架构的数据采集
26个数据分析案例——第五站:基于Scrapy的架构的数据采集案例环境Python: Python 3.x;数据说明title:课程标题image_url:标题图片地址。properties:课程性质。stage:课程阶段。enrollment:课程报名人数。资料包链接:https://pan.baidu.com/s/1-DUUUAOfpC4Gs5DAaHcgUg提取码:5u6s实验步骤第一步:页面分析在爬取某个网页中的数据之前,首先要学会如何去分析其页面的结构,我们想要
2021-08-10 21:57:07
1677
原创 26个数据分析案例——第四站:基于Flume与Kafka的web服务器日志数据采集
26个数据分析案例——第四站:基于Flume与Kafka的web服务器日志数据采集实验环境Python: Python 3.x;Hadoop2.7.2环境;Kafka_2.11;Flume-1.9.0.资料包链接:https://pan.baidu.com/s/1oZcqAx0EIRF7Aj1xxm3WNw提取码:kohe实验步骤第一步:安装并启动httpd服务器[root@master ~]# yum -y install httpd[root@master ~]# cd /v
2021-08-09 19:36:05
1131
原创 Python入门实践案例
Python入门实践案例1、基本语法2、 数据类型2.1、数字2.2、布尔2.3 字符串3、列表4、元组5、集合6、字典1、基本语法#我是注释print('hello world') #打印出:hello worldprint("hello world") #打印出:hello worldx=3 #变量赋值,不需要声明变量类型print(type(x)) #打印出:<type '...
2021-07-06 15:43:00
589
原创 互联网社交好友推荐
互联网社交好友推荐项目背景实验目的实验步骤1、代码分析2、创建项目第一步:自定义一个 FriendOfFriend 的输出类第二步:创建分组类FriendRecommendGroup第三步:创建执行好友推荐的任务类第四步:创建数据切分类第五步:创建好友推荐Reduce类第六步:创建排序Map类第七步:创建排序Reduce类3、运行代码第一步:编译代码第二步:创建实验数据第三步:输入输出路径第四步:...
2021-07-06 15:42:32
340
原创 HDFS Shell命令基础入门实战
HDFS基础知识1. HDFS 是做什么的HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Se...
2021-07-06 15:41:40
405
原创 动态添加hadoop HA
前置准备CentOS7、jdk1.8、hadoop-2.7.7、zookeeper-3.5.7想要完成本期视频中所有操作,需要以下准备:大数据开发之Hadoop前置准备Hadoop完全分布式集群环境搭建-视频教程HA(高可用)-Hadoop集群环境搭建视频+图文教程大数据常用shell脚本之分发脚本编写-视频教程大数据常用shell脚本之ha-hadoop脚本编写-视频教程一、集群规划下面的步骤我们将实现把hadoop04动态上线,再将hadoop04动态下线二、启动现有集群[root
2021-07-06 15:40:52
159
原创 青年失业率
青年失业率需求分析实验步骤步骤一:将数据集读入内存实现步骤代码实现步骤二:按名字选取数据实现步骤代码实现步骤三:按时间选取数据实现步骤代码实现需求分析 如今越来越多的人在毕业后开始了求职和工作,但面对如此大的竞争压力和其他因素都面临的事业的可能性,本案例主要为计算请年工作者的失业率。实验步骤步骤一:将数据集读入内存 在这个数据集里一共有两个数据集,分别命名为"unemploymen...
2020-06-28 11:50:11
762
原创 HiveonSpark配置 Maven+spark编译+Hive配置
一 实验说明本实验主要完成Hvie on Spark的配置,主要内容包含maven配置、编译spark源码 spark配置 hive配置二 配置步骤一、maven配置编译spark源码需要使用maven,我们先来配置一下maven环境。第一步:下载maven安装包编译spark建议使用maven3环境,下载连接为http://maven.apache.org/download.cgi,点击图中红框中的内容即可下载。第二步、安装下载完成后将maven安装包上传到Linux系统,我这里上传到了
2020-06-25 21:50:10
2164
原创 Docker基础入门实战之Docker安装
Docker基础入门——Docker安装1、虚拟化技术2、什么是Docker3、Docker架构4、Docker安装在Linux中安装DockerWindows中安装Docker1、虚拟化技术虚拟化技术是一个通用的概念,在不同的领域存在不同的理解,在计算机领域,一般指计算机虚拟化或服务器虚拟化。虚拟化是一种资源管理技术,可以抽象计算机的各种实体资源,如服务器、网络、内存及存储等,打破结构之间的...
2019-09-15 17:57:35
628
原创 VMware与CentOS 7虚拟机安装
通过如下步骤,新建“CentOS 7 64 位”虚拟机,并实现CentOS7的系统安装。VMware安装包链接:https://pan.baidu.com/s/1eejhsrpEjgfamWfPNe5T7w提取码:n17pCentos7镜像链接:https://pan.baidu.com/s/1qVPWsGx2TfXKr9_ipA98GQ提取码:ywdx复制这段内容后打开百度网盘手机...
2019-09-11 21:41:42
498
转载 Github上的开源工具帮助你实现“十一”回家的愿望
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。原文链接:https://blog.csdn.net/BEYONDMA/article/details/100622963下周末就是中秋节了,笔者做一名北漂的天津人,也特别能理解那些远离家乡独自在外的同事,每逢佳节倍思亲,但这时候的火车票却是十分难抢,那么笔者就为大家介绍一下今天Github...
2019-09-11 21:04:46
7103
原创 Python基础入门实战案例
Python 基础需求分析实验步骤步骤一:Python基础第一步:打印输出第二步:基本语法第三步:文件读写:open, csv, pandas练习:读取第一行存为columns,第二行为sample第四步:列表练习1:提取第一个样本的Hospital Name和Score练习2:可变数据结构的浅拷贝与深拷贝第五步:控制结构练习:取出Hospital Name和Score放入一个嵌套列表中,并将Ho...
2019-09-10 21:24:50
5231
3
原创 互联网日志用户行为分析
互联网日志用户行为分析项目背景项目需求实现步骤第一步:获取原生数据第二步:数据清洗1、数据清洗目的2、数据清洗方案3、 数据清洗过程AccessLogCleanMapperAccessLogCleanJob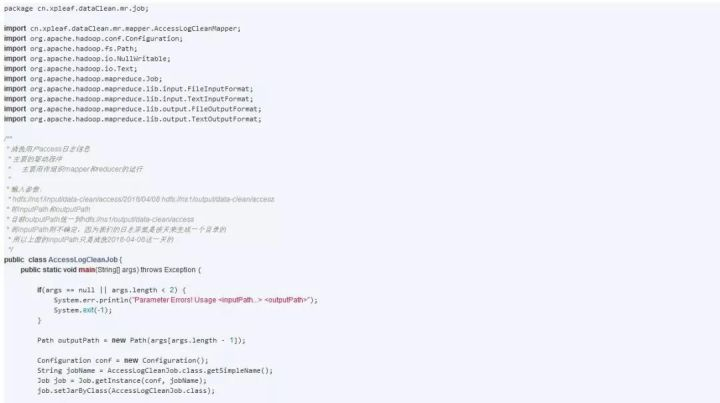执行MapReduce程序4、数据清洗结果第三步:数据处理1、数据处理...
2019-09-10 21:24:16
2624
原创 互联网社交好友推荐
互联网社交好友推荐项目背景实验目的启动基础环境第一步:登录本机第二步:启动Hadoop集群实验步骤1、代码分析2、创建项目第一步:自定义一个 FriendOfFriend 的输出类第二步:创建分组类FriendRecommendGroup第三步:创建执行好友推荐的任务类第四步:创建数据切分类第五步:创建好友推荐Reduce类第六步:创建排序Map类第七步:创建排序Reduce类3、运行代码第一步:...
2019-09-10 21:23:18
610
原创 自动爬取bilibi小视频
自动爬取bilibi小视频实验目的实验环境实验步骤第一步:查找request URL请求地址第二步:代码实现1、访问目标网址代码2、下载情况展示3、编写主函执行程序实验目的通过Python访问哔哩哔哩网站抓取每次小视频排行前100的视频,并保存到本地文件加下。通过该案例能够了解爬虫中请求头的设置方法,掌握使用requests访问目标网址的方法,通过标签找到视频的连接并下载到本地。实验环境...
2019-09-10 21:21:56
625
原创 电信手机流量数据分析
电信手机流量数据分析实验目的实验环境一 源数据分析1、数据说明二、实现步骤第一步: 资源准备1、准备数据2、上传数据第二步:数据清洗1、准备工具包2、编写Map代码3、编写Reduce代码代码执行第三步:数据分析1、清洗结果数据到HIve2、统计个业务类型访问量3、统计各业务组浏览量4、分别统计总上行和总下行流量实验目的通过Python访问哔哩哔哩网站抓取每次小视频排行前100的视频,并保存到...
2019-09-10 21:20:24
2313
7
原创 Flume+Kafka+Spark Streaming+MySQL实时数据处理
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章UML 图表FLowchart流程图导出与导入导出导入...
2019-06-06 08:40:30
5149
12
原创 Hadoop环境配置-Ubuntu
一:免密操作1.生成rsa公钥过程中输入回车即可,执行命令:master@node:~$ ssh-keygen -t rsa• rsa:公钥加密算法• ssh-keygen:生成、管理和转换认证密钥• -t:指定密钥类型结果如下:2.为主机(localhost)设置公钥使用ssh-copy-id命令为本机设置公钥,执行命令:master@node:~$ ssh-copy-i...
2019-02-22 13:32:00
489
cuda-repo-rhel7-11-0-local-11.0.2_450.51.05-1.x86_64.txt
2021-08-07
tensorflow_gpu-2.4.0-cp37-cp37m-manylinux2010_x86_64.txt
2021-08-07
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人