







数据一致性
读redis时,redis中没查到,去数据库中查,数据库中查到了,再去更新缓存;
写redis时,既要更新数据库中数据,也要更新redis中数据,从而保证数据一致性,是先更新数据库还是先更新redis呢,首先这里更新redis采用删除redis,当下次其他线程读时,就去数据库读最新数据,并更新到redis中;那写redis时,是先更新数据库,再删除redis,还是先删除redis,再更新数据库呢?可以比较下两种方案;
1)先更新数据库,再删除redis
若更新数据库成功,但删除redis失败,此时会出现redis和mysql数据不一致,此时可以反复重试删除,可以将需要删除的key放进消息队列,写一个消费者执行删除redis中的数据,或者采用canal中间件,当发现数据库有更新时,删除redis中数据;
当写redis时,先更新数据库值为20,再删除redis,此时来了一个读,发现缓存为空,就去数据库把数据20读出来,准备更新redis,但在读线程更新redis之前,又来一个写线程要写redis,此时该写线程就去更新数据库值为21,然后删除redis,接着读线程才将数据20更新到redis,导致此时redis为20,数据库为21,数据不一致;其实这种情况几乎不可能存在,读线程更新redis不可能停顿这么久,而去等写线程又是更新数据库,又是删除redis,因为通常缓存的写入要比数据库写入快;
2)先删除redis,再更新数据库
其实这种方案弊端比上一种大,如若线程A先删除redis,再更新数据库,若期间有线程B读取缓存,发现无数据,将数据库旧数据又写进缓存,此时线程A才完成数据库更新,那么将出现数据不一致性。这个时候可以采取延时双删策略,即线程A先删除redis,再更新数据库,等待200毫秒,再次执行redis删除,可以保证期间线程B读到空缓存的情况。采取延时双删策略,那就是设定写redis的线程,执行两次删redis的操作,间隔200ms;
综上选择先更新数据库,再删除redis,更为合适;
主从集群
这里的主从集群指的是一主一从或一主多从,一旦主节点挂了,系统便不可用。需要手动把之前的从服务器切换成主服务器,这个比较费时费力,还会造成一定时间的服务不可用。所以哨兵集群就出现了,哨兵为了在master挂掉后,选出新的master。这里先介绍主从复制。
全量复制
如果你为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个PSYNC命令给master请求复制数据。全量复制和混合持久化很相似,从节点发来同步指令,主节点收到后,立即将当前状态生成rdb快照,并且将接下来接收到的客户端命令写进缓存中,当持久化为rdb结束后,主节点会将rdb快照发给从节点,从节点将其同步之后,主节点最后将缓存的增量命令发给从节点,让其同步。
部分复制
master和它所有的
slave都维护了复制的数据下标offset和master的进程id,因此,当网络连接断开后,slave会请求master
继续进行未完成的复制,从所记录的数据下标开始。如果master进程id变化了,或者从节点数据下标
offset太旧,已经不在master的缓存队列里了,那么将会进行一次全量数据的复制。
哨兵集群
故障转移前
1)哨兵节点是特殊的redis实例
哨兵节点也有自己的集群,每个哨兵节点既监控所有的redis服务,也相互监控,后者的目的是防止哨兵挂了。
2)Sentinel 默认以每秒钟 1 次的频率向 Redis 服务节点发送 PING 命令
3)如果 master 被标记为下线,就会开始故障转移流程
故障转移中
1)基于raft协议,哨兵节点间会在哨兵中选一个哨兵节点执行故障转移
2)选出 Sentinel Leader 之后,由 Sentinel Leader 向某个节点发送 slaveof no one
命令,让它成为独立节点。
3)然后向其他节点发送 slaveof x.x.x.x xxxx(本机服务),让它们成为这个节点的
子节点,故障转移完成。
4)优先级排序,复制数量,进程 id三个因素决定哨兵选谁作为master,优先级是设置在文件中的(replica-priority 100),数值越小优先级越高,如果优先级相同,就看谁从 master 中复制的数据最多(复制偏移量最大),选最多的那个,如果复制数量也相同,就选择进程 id 最小的那个。
redis cluster分片集群
redis cluster集群是redis分布式方案中的一种,redis分布式方案一共有三种:客户端分片方案,中间件分片方案如codis,以及redis cluster分片方案;
客户端分片
客户端分片和redis cluster,用户均可以用jedis访问redis服务,但代码不同,客户端分片的方案下利用jedis实现对redis的访问代码如下:
此时用到了JedisPoolConfig类,JedisShardInfo类,ShardedJedisPool类,通过ShardedJedisPool#getResource方法获取一个ShardedJedis实例,调用ShardedJedis#set方法,ShardedJedis#get方法,设置数据读取数据;

一致性哈希
https://www.cnblogs.com/iwenwen/p/10997372.html
机器ip进行hash,分布在环上,key再进行hash,分布到环上,顺时针找到最近的一台机器;并不涉及key的hash对机器台数取模,所以当机器增多或者减少,不会使大部分key在机器上获取不到,有了环,当机器增多或减少时,只影响局部key,因为key经过hash后,还是顺时针找到下一个最近的机器存储即可,其他机器在环上的分布不变;
客户端分片用到了一致性哈希原理,在上述getResource()方法中,获取了一个ShardedJedis实例。
它最终调用了redis.clients.util.Sharded类的initialize()方法,该方法如下,主要是对每个redis节点的名字计算哈希,使其散开分布在哈希环上,并且为每个redis节点创建160个虚拟节点,将实体节点和虚拟节点均放进哈希环中,用红黑树实现了哈希环,客户端从哈希环中获取Redis节点的信息,虚拟节点也是映射到对应的Redis实例。红黑树便于查找;

客户端分片的缺点是客户端利用了jedis的几个类,这是用java写的,不能复用,但若换成其他语言,需要自己重新编码,耗时费力;所以中间件分片就是将上述分片算法抽取出来,单独做成一个应用,任何客户端只要访问这层应用,就可以实现分片读写;
中间件分片方案
中间件分片方案是redis cluster分片方案出来之前的过渡方案,中间件分片方案包括codis,原理如下:

redis cluster分片方案
利用jedis实现对redis的访问的代码如下,此时用到了JedisPoolConfig类,JedisCluster类,通过JedisCluster#set,JedisCluster#get方法,设置数据读取数据;

增加或删除redis节点
redis cluster方案是redis后来推出来的,和一致性哈希非常相似,个人觉得是一样的,只是redis cluster分片算法是key的hash值对16384取模,得到的结果在哪个范围就在哪台redis机器;另外用jedis访问redis时,编写的代码和客户端分片不同,而且在系统启动后,客户端会缓存一份各个redis节点对应的16384个槽位中的哪些范围,客户端计算完key的hash后,可以往指定节点发送;
当增加或者删除redis节点时,可以用linux命令的方式给新增的redis节点,分配槽位;也可以利用命令,即使发送的key的hash取模16384后得到的结果分布在不同节点上,但也可以让它们分布到一个节点上,即如下:
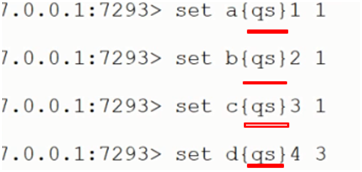
此时只会对{}中的数据进行hash计算,再取模16384,自然就路由到同一个redis节点上了,之前是分别对a,b,c,d进行hash;
JedisCluster的数据分片原理
GetCRC16(key) & (16384-1),由于16384是2的幂,所以该值等于GetCRC16(key) %16384
源码如下

redis cluster集群注意事项
1)至少要有三个master,因为如果是2个master,当其中一个挂了后,slave节点发起挂了的请求,只能拿到剩下的一个master的回复OK,并没有超过半数,因为总数是2,所以永远无法为挂掉的master选出新的master,这个master集群也不可用了;读写都在master上,slave只做备份,和故障转移
2)数据分片存储在不同master上
3)支持水平扩容
4)客户端启动时,会获取到服务端集群的槽位分布信息,即哪些槽位分布在哪些机器上,最后对key进行hash计算,取模16384,得到一个槽位,即可判断在哪台机器上,底层以resp协议的方式发往服务端的socket;
5)当服务端redis节点发生变化,但客户端不知道,此时客户端依旧往原来的redis服务节点发数据,此时

6)集群节点之间是去中心化的,是基于gossip通信的,集群节点不宜太多,节点之间的通信耗时,一般是几个微服务共有几个redis集群,每个redis集群中有5,6个master节点,每个master节点有几个从节点;gossip协议是最终一致性的,底层基于c语言实现;分布式一致性协议还包括zab,raft等;
7)在分布式的cap理论中,c代表实时一致性,a代表可用性,p代表分区一致性;redis更多时候是保证a与p,而zookeeper更多时候是保证c和p;c和a是成反比的,主从一致性提高了,但主节点的可用性就会降低;redis可以牺牲一致性,因为redis可以丢点数据,因为可以去数据库找到,redis主要目的就是避免大量请求直接到数据库;
8)部署3个master和部署4个master节点,在系统的可用性方面没有什么区别,因为当部署3个master时,最多只能挂其中1个,而当部署4个master时,最多也只能挂其中1个;但如果为了分担客户端的请求压力,部署5个master要比部署4个master强,因为部署5个master,此时最多可以挂两个master,此时依旧可以为挂了的master选出新的master节点,增强了可用性;
9)当redis集群中,某一个master挂了,则可通过redis.conf中的参数cluster-require-full-coverage配置为no,保证整个集群依然可以正常使用;
选举原理
当master节点挂了,其slave节点(当前挂了的master节点可能对应多个slave节点)会向其他几组主从节点发送挂了的消息,其他master收到后,会对最快发消息给他的那个slave节点响应ack,当slave收到半数以上ack的时候,就会被选举为master节点,最后它会向其他所有节点发送ping信息,同步元数据信息,并告知选举结束。在主节点挂了后,其对应的从节点并不是立马向其他节点发送挂了的消息,而是有一个延时时间,延时时间有个计算公式

槽位
Key的hash对16383取模,得到一个值,根据这个值去找相应的master
横向扩容
add-node代表新加节点,reshard代表为新节点申请槽位
redis cluster 特点
redis cluster兼具了哨兵中的故障转移特点,又可以进行主从复制;

数据分片常见问题

















 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











