






大数据—Hive的数据导入和基本操作
1.大数据创建操作
- 当我们启动hive之后,我们的hive在启动的初始化的过程中就会帮我们在mysql的数据库中创建我们制定的数据库名字;并且里边有对用的表(这些表不需要我们现在操作;到大数据架构的时候才会用的上;)
如果存在连接不上的时候;去查看navicat的的连接;
他的里边建立很多的表:
- 当我们的hive安装成功之后;hive默认里边有一个库:default库;
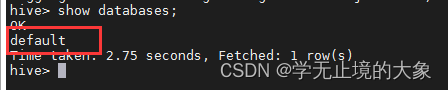
这个库是hive自动生成的;而我们以后需要的就需要我们自己去创建;使用的sql语句和mysql是一样的;
数据库的创建
3.创建一个自己的数据库:
create database db_order;
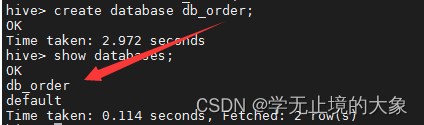
创建完毕数据库就要使用数据库;如果不指定他是用的default库;
使用数据库: use db_order;

注意:但是这个地方不显示你到底进入是那个库;我们需要显示你进入的是那个库: 比如在前面显示 db_order; 或者default;根据你进入的是那个:
需要进行设置:
1、让提示符显示当前库:
hive>set hive.cli.print.current.db=true; 但是他是一次性;退出就有回去了

切换就有回去了;
永久修改方法:进入到目录:
1./usr/local/hive/apache-hive-1.2.2-bin/bin/
2.然后编辑(隐藏文件) vi .hiverc
3.把上面的粘贴到里边;set hive.cli.print.current.db=true;
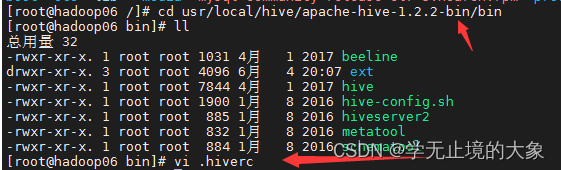
4.然后重启hive即可;

4.其他的数据库操作和mysql的一样; drop;alter 等等;
表的创建
直接使用数据库的语句进行操作即可;

查看表结构:
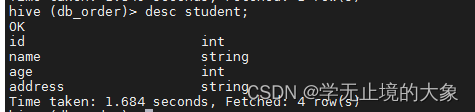
添加表数据:(手工添加)
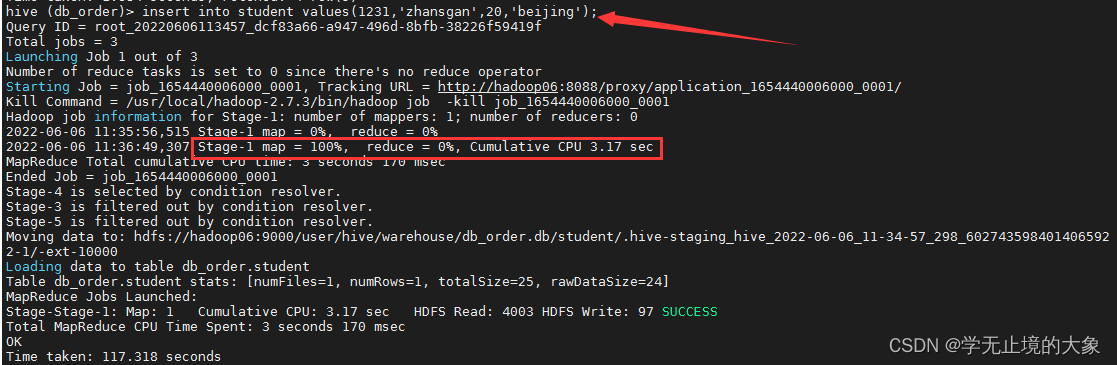
因为hive是存储数据还是hdfs;他的主要作用还是在计算reduce上; 我们发现当添加数据的时候他就会把数据存储到hdfs上的数据;
hive在HDFS中的数据显示
在hive创建的数据库,会默认的在hdfs的:/user/hive/warehouse/数据库/表,改目录可以自行配置
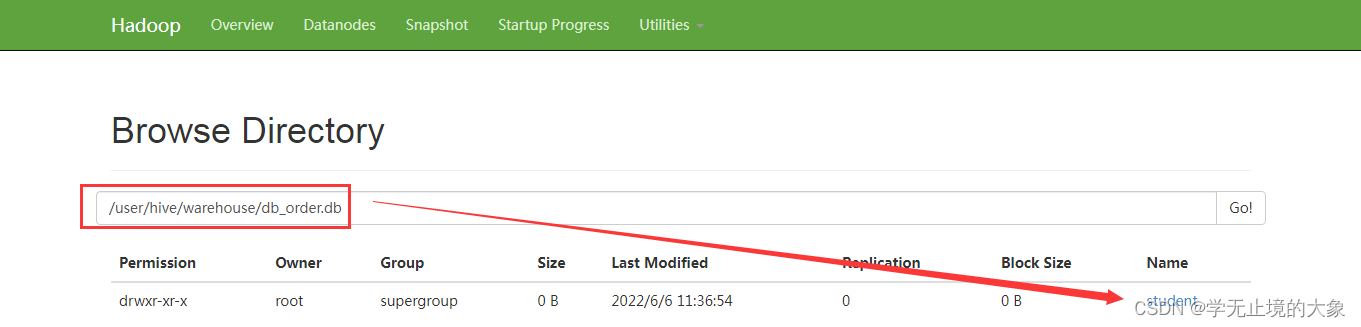
而要是往hive中导入数据的方式有很多中:
这里使用的是我们自己导入;还可以使用外部导入数据的方式;
如果是hdfs中上传的数据可以直接放入到hive中去;

方式二:在hive的命令行中进行数据导入:(用hive导入数据)

hive的数据导入操作
例如:这些数据是我们从外部导入到hive中的数据;

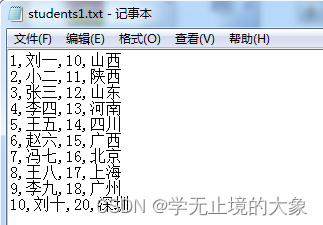
怎样把这些数据导入到表中去:
1.肯定的先有一张表;在这个边中有这几个字段; id;name,age,address;


这样的化数据添加的时候就会添加到id那栏位上; 会以每行的方式存储进去;把数据类型就不匹配;问题来了:但是这个文档中的数据都是通过逗号分隔的;那么在数据库中默认会认为是一条数据然后插入到第一个字段;
可以修改字段:
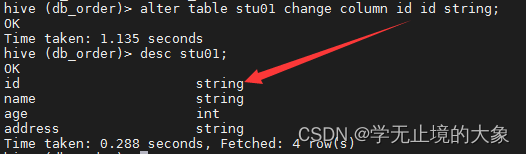
2.需要修改表的字段 把第一个字段改成string;
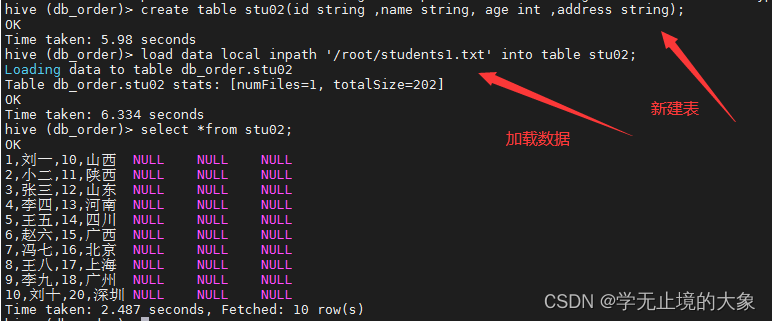
这样的haul就出现了我们的数据放在第一个字段里边;
解决这个问题:可以使用hive的原始方法来创建表实现:
1.create table stu03(id int ,name string, age int ,address string) row format delimited fields terminated by ‘,’;
创建表的时候;对每行数据进行格式分割;用","分割;这样就和文件中的对应了;
2.加载外部文件导入;
load data local inpath ‘/root/students1.txt’ into table stu03;
3.查询创建的表中的数据:select *from stu03;
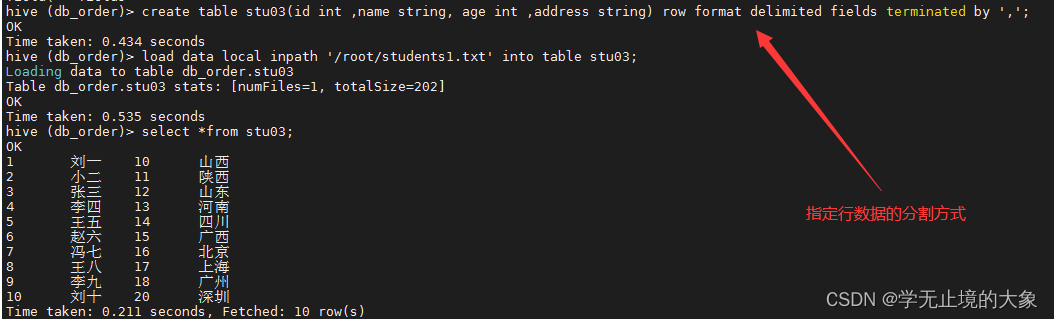
不显示字段名称:
需要修改内容:
hive>set hive.cli.print.header=true; 但是这是临时的;并显示表的名字;
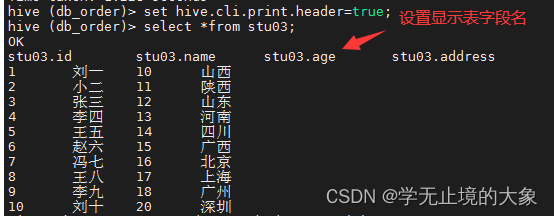
如果想让他们对齐;并且不显示表的名字;
hive >set hive.resultset.use.unique.column.names=false;
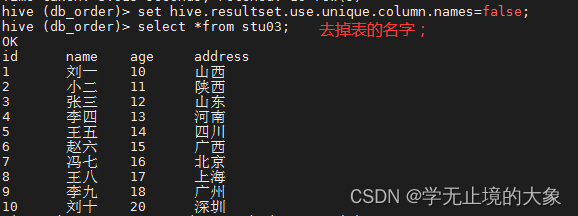
如果退出的化;他后有回去了;永久改变;
1./usr/local/hive/apache-hive-1.2.2-bin/bin/
2.然后编辑(隐藏文件) vi .hiverc
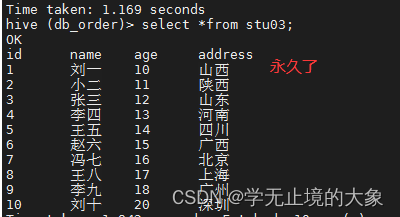
添加:
set hive.cli.print.header=true;
set hive.resultset.use.unique.column.names=false;

保存即可;
还有一个参数:修改后让我们进行数据查询的时候不走MapReduce的操作:
1.查询当前的stu03表;
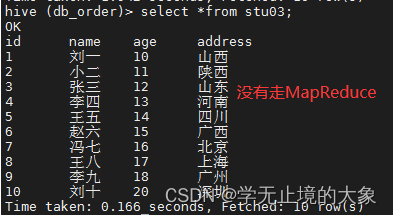
2.我们统计下;使用函数操作:
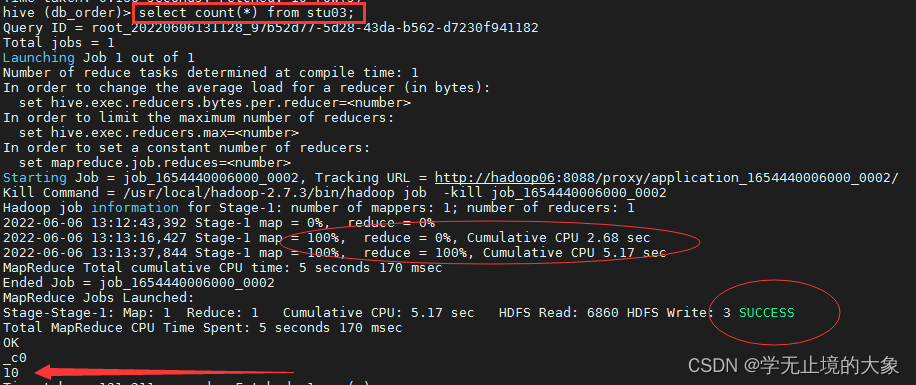
发现他走的是MapReduce的操作;这样就非常的慢;
设置这个参数就可以了;set hive.exec.mode.local.auto=true; 开起本地模式:数据量比较小的时候用本地; 当数据量大的时候;用集群;操作把这个地方改成false;
当一个job满足如下条件才能真正使用本地模式:
1.job的输入数据大小必须小于参数:hive.exec.mode.local.auto.inputbytes.max(默认128MB)
2.job的map数必须小于参数:hive.exec.mode.local.auto.tasks.max(默认4)
3.job的reduce数必须为0或者1

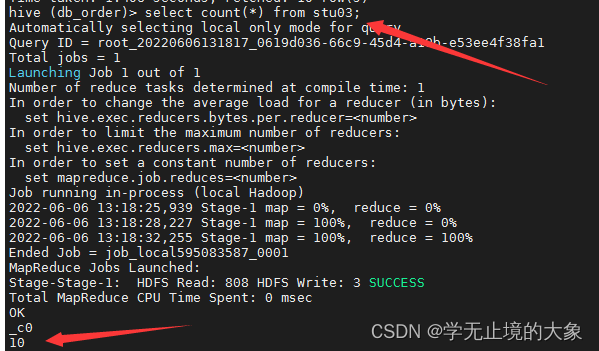
这样的我们安装操作基本就完成。















 7391
7391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









