






- Hbase他是一个非结构化数据库; 他是通过列存储来进行数据的存储;通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。
- Hbase在进行数据存储的时候使用的是HDFS来进行数据的存储; 所以他必须hadoop的支持;
- Hbase和hadoop的版本必须对应:

注意:
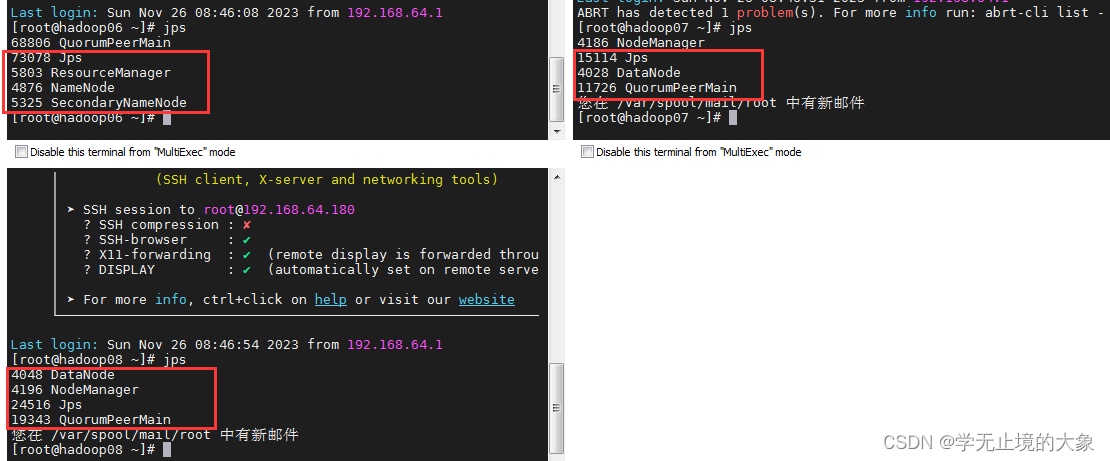
要进行hbase的操作之前需要启动:
1.hadoop
1.一键启动在hadoop06号机子上执行:start-all.sh

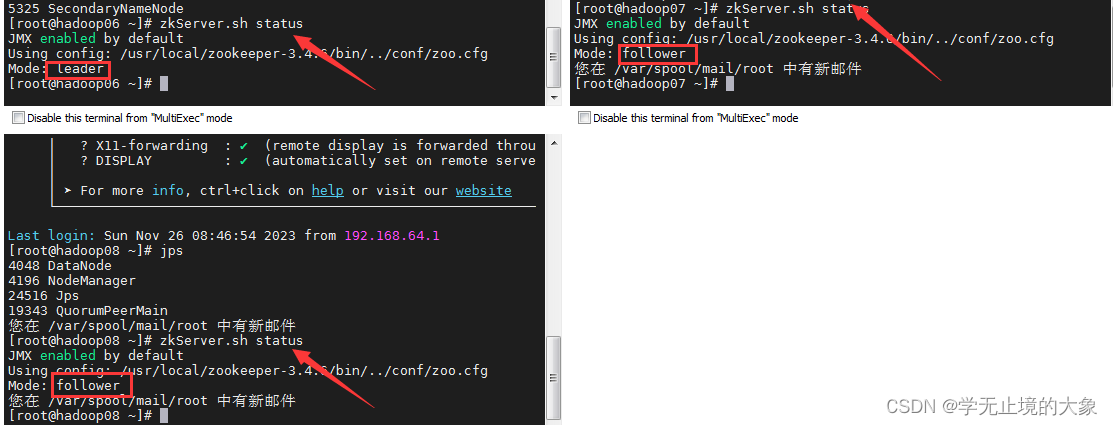
2.zookeeper
每个节点都要进行执行
启动zookeeper
zkServer.sh start
查看状态
zkServer.sh status
关闭zookeeper
zkServer.sh stop
一.Hbase概述
1.简介
当您需要对大数据进行随机、实时的读写访问时,请使用Apache HBase™。这个项目的目标是在商用硬件集群上托管非常大的表——数十亿行X百万列。Apache HBase是一个开源的、分布式的、版本化的、非关系型数据库,实时随机读写、NoSQL数据库、列存储、可存储海量数据。
Apache HBase™ 是以 hdfs 为数据存储的,一种分布式、可扩展的 NoSQL 数据库。
2.HBase 数据模型
HBase 的设计理念依据 Google 的 BigTable 论文,论文中对于数据模型的首句介绍。
Bigtable 是一个稀疏的、分布式的、持久的多维排序 map。
之后对于映射的解释如下:
该映射由行键、列键和时间戳索引;映射中的每个值都是一个未解释的字节数组。
最终 HBase 关于数据模型和 BigTable 的对应关系如下:
HBase 使用与 Bigtable 非常相似的数据模型。用户将数据行存储在带标签的表中。数
据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。
最终理解 HBase 数据模型的关键在于稀疏、分布式、多维、排序的映射。其中映射 map指代非关系型数据库的 key-Value 结构。
3.HBase 逻辑结构
{
“row_key1”:{
“personal_info”:{
“name”:“zhangsan”,
“city”:“北京”,
“phone”:“131********”
},
“office_info”:{
“tel”:“010-1111111”,
“address”:“atguigu”
}
},
“row_key11”:{
“personal_info”:{
“city”:“上海”,
“phone”:“132********”
},
“office_info”:{
“tel”:“010-1111111”
},
“row_key2”:{
…
}
存储数据稀疏,数据存储多维,不同的行具有不同的列。
数据存储整体有序,按照RowKey的字典序排列,RowKey为Byte数组
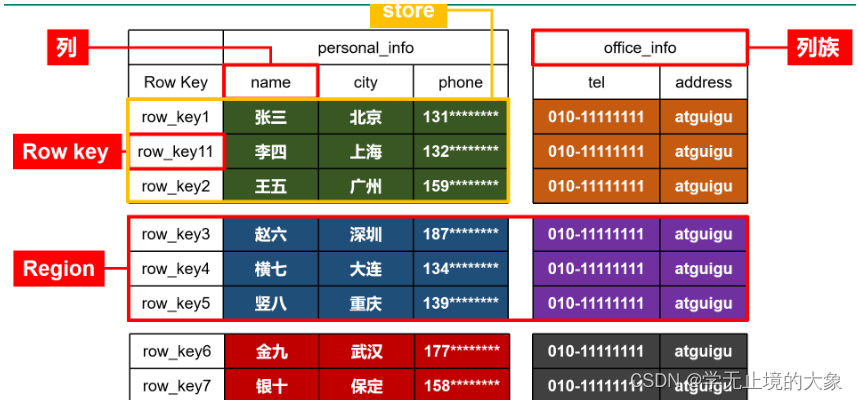
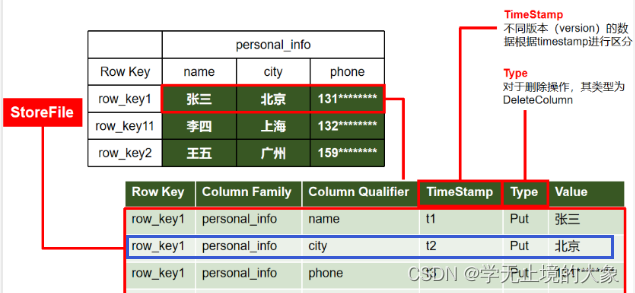
如图,这就是Hbse的一张表
从列的角度看,首先要有列族(多个列组成的集合),有一个特殊的列Row_Key(类似于MySQL的主键)
从行的角度看,我们可以把一张表水平分为多个部分,每个部分就是一个Region(区域块),每个Region中的不同列族都是一个store(存储块),我们实际存储就是以store为单位存储的
一个region的数据时存在一台机器里面的,而一个region不同的store是存在不同文件里的
那store是怎么存的呢?
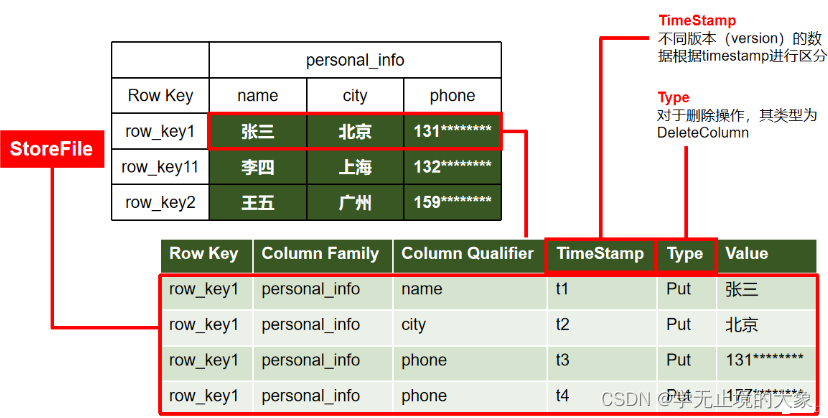
每个store是以行为单位进行列式存储,比如第一行,每一列的详细信息都会被存成一行,包括属于哪个Row_Key,哪个列族,属性名,时间戳,存储类型,具体的值
Hbase底层是依赖HDFS的,而HFDS不支持修改,那我们怎么修改呢?实际上是假修改,实际是新增了一行,比如上图的电话,我们修改实际是新增一行,但是时间戳变了,我们读的时候读最新的时间戳的数据,所以修改对我们来说是个透明操作
Type:增加、修改都是Put类型,删除是Delete类型
4. 数据模型
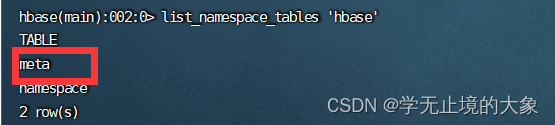
1)Name Space
命名空间,类似于关系型数据库的 database 概念,每个命名空间下有多个表。HBase 两
个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default表是用户默认使用的命名空间。
2)Table
类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需
要声明具体的列。因为数据存储时稀疏的,所有往 HBase 写入数据时,字段可以动态、按需
指定。因此,和关系型数据库相比,HBase 能够轻松应对字段变更的场景。
3)Row
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
4)Column
HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限
定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
5)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,
其值为写入 HBase 的时间。
6)Cell(小单元)
由{rowkey, column Family:column Qualifier, timestamp} 唯一确定的单元。cell 中的数
据全部是字节码形式存储。
5.Hbase简化架构
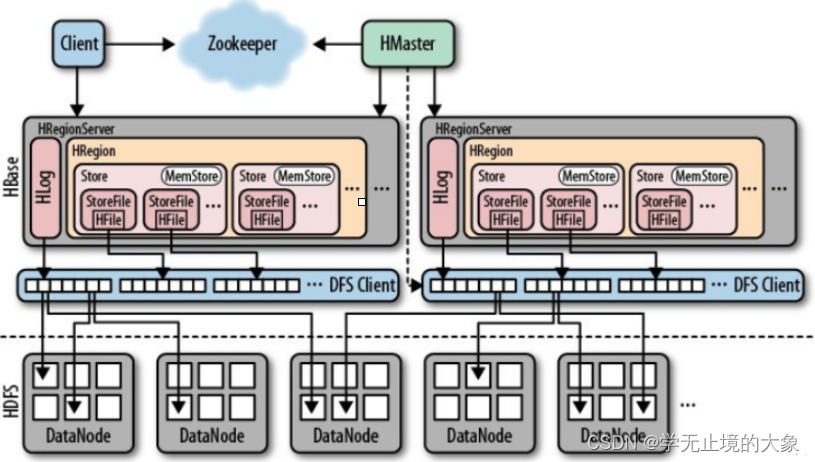
HRegionServer是Hbase中最核心的模块
1.管理多个HRegion(一个Region对应某table中的一个Region)
一个Region下有多个Store(一个Store对应一个列族)
2.一个Store里面有MemStore(写缓存,K-V在Memstore中进行排序,达到阈值之后才会flush到StoreFile,每次flush生成一个新的StoreFile,由于这是在内存,可能由于故障数据丢失,为此在每个RegionServer中还会Hlog,记录所有写操作,万一MemStore数据丢失,Hlog中也有备份)
3.StoreFile底层是Hfile,HFile为hdfs中的小文件,数量过大时,进行compact操作,合并成一个大文件
负责响应用户IO请求,对数据操作,并且向HDFS文件系统中读写、删除、修改(对数据操作通过RegionServer)SplitRegion, CompactRegion
4.有一个BlockCache(图中未标出):读缓存,每次新查询的数据会缓存在BlockCache中(LRU(最近最少使用)淘汰策略)
Hmaster(主人)
允许有多个master节点,使用zookeeper控制,保证只有一个master节点处于激活状态,当存活master机器宕机,其他的master节点向zookeeper竞争,成为存活的节点
1.管理用户对table的增,删,改,查操作(如果对表操作是通过Hmaster)
2.管理RegionServer的负载均衡,调整region分布
3.在Region分裂后,负责新region的分配
4.在RegionServer死亡后,负责对regionServer上的region的迁移
zookeeper
负责Hbase中多Hmaster的选举
实时监控RS的存活
存储Hbase的元数据信息(表的位置)
6. 架构详细分析
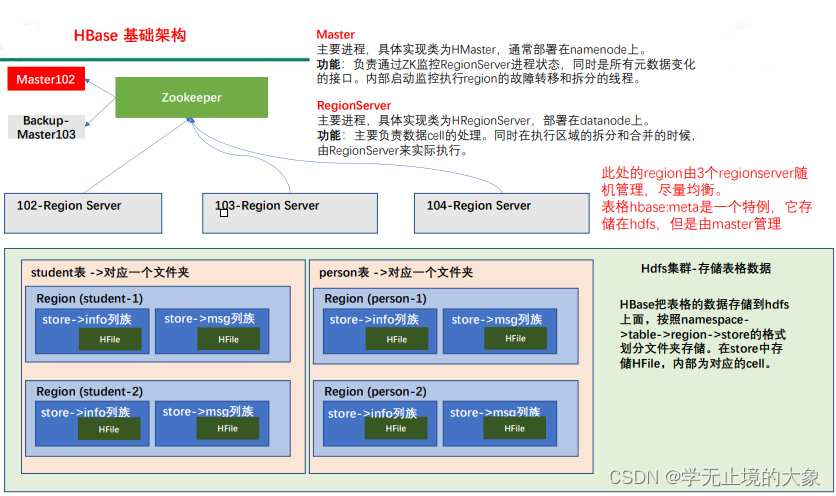
架构角色:
1)Master
实现类为 HMaster,负责监控集群中所有的 RegionServer 实例。主要作用如下:
(1)管理元数据表格 hbase:meta,接收用户对表格创建修改删除的命令并执行
(2)监控 region 是否需要进行负载均衡,故障转移和 region 的拆分。
通过启动多个后台线程监控实现上述功能:
①LoadBalancer 负载均衡器
周期性监控 region 分布在 regionServer 上面是否均衡,由参数 hbase.balancer.period 控
制周期时间,默认 5 分钟。
②CatalogJanitor 元数据管理器
定期检查和清理 hbase:meta 中的数据。meta 表内容在进阶中介绍。
③MasterProcWAL master 预写日志处理器
把 master 需要执行的任务记录到预写日志 WAL 中,如果 master 宕机,让 backupMaster读取日志继续干。
2)Region Server
Region Server 实现类为 HRegionServer,主要作用如下:
(1)负责数据 cell 的处理,例如写入数据 put,查询数据 get 等
(2)拆分合并 region 的实际执行者,有 master 监控,有 regionServer 执行。
3)Zookeeper
HBase 通过 Zookeeper 来做 master 的高可用、记录 RegionServer 的部署信息、并且存储
有 meta 表的位置信息。
HBase 对于数据的读写操作时直接访问 Zookeeper 的,在 2.3 版本推出 Master Registry模式,客户端可以直接访问 master。使用此功能,会加大对 master 的压力,减轻对 Zookeeper的压力。
4)HDFS
HDFS 为 Hbase 提供最终的底层数据存储服务,同时为 HBase 提供高容错的支持。
7.Hbase写数据
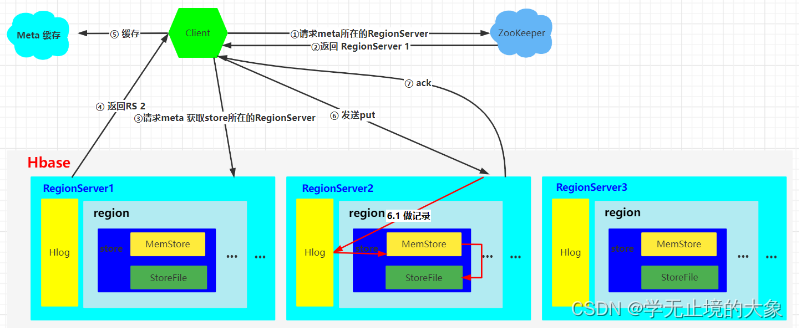
首先我们要清楚,我们写数据是写到一个HRegionServer里某一个region里的某个store里面,我们的目的就是找这个store;那我们首先要知道哪个RegionServer存了这个store,去问谁呢?去问元数据,也就是hbase下的meta这张表;那meta这张表的内容在哪里?它也是一张表啊,信息由ZooKeeper存储:
5.MemStore Flush
1.当某个memstore的大小达到了hbase.hregion.memstore.flush.size(默认值128M),其所在region的所有memstore都会刷写
当memstore的大小达到了
hbase.hregion.memstore.flush.size(默认值128M)×
hbase.hregion.memstore.block.multiplier(默认值4)
时,会阻止继续往该memstore写数据(写大量数据时)
2.当region server中memstore的总大小达到
java_heapsize
× hbase.regionserver.global.memstore.size(默认值0.4)
× hbase.regionserver.global.memstore.size.lower.limit(默认值0.95),
region会按照其所有memstore的大小顺序(由大到小)依次进行刷写。直到region server中所有memstore的总大小减小到上述值以下
当region server中memstore的总大小达到
java_heapsize
× hbase.regionserver.global.memstore.size(默认值0.4)
时,会阻止继续往所有的memstore写数据
3.到达自动刷写的时间,也会触发memstore flush。自动刷新的时间间隔由该属性进行配置hbase.regionserver.optionalcacheflushinterval(默认1小时)
8.Hbase读取数据
1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server
2)访问对应的Region Server,获取hbase:meta表,根据读请求的
namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问
3)与目标Region Server进行通讯
4)分别在MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)
5)将查询到的新的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache
6)将合并后的最终结果返回给客户端
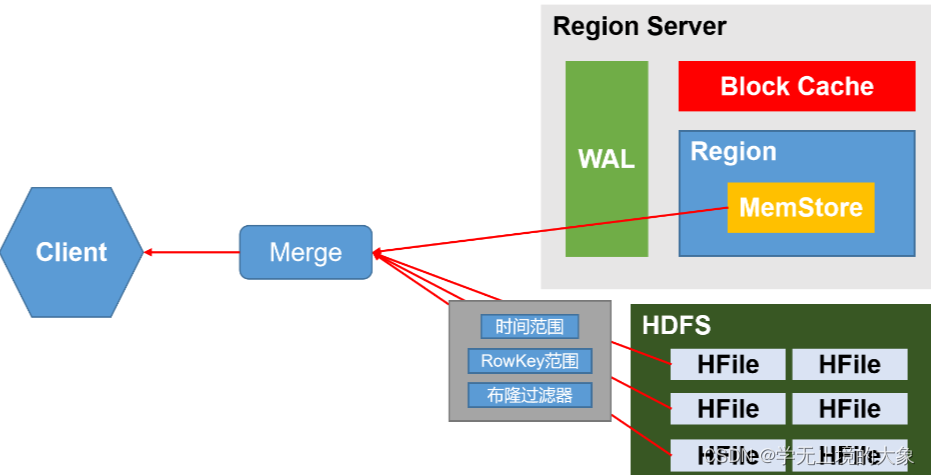
布隆过滤器会告诉你这个文件一定不存在某个数据,但不保证某数据存在,节省了时间
7.StoreFile Compaction(块)
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction
Compaction分为两种,分别是Minor Compaction和Major Compaction。Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,并清理掉部分过期和删除的数据。Major Compaction会将一个Store下的 所有的HFile合并成一个大HFile,并且会清理掉所有过期和删除的数据
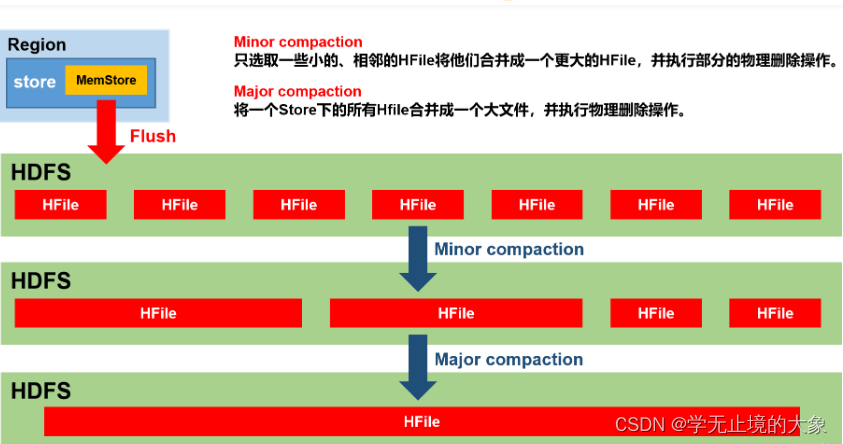
默认每次flush都会进行小合并,大合并则是周期性的(默认7天)















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









