






一、HBase简介
HBase是一个开源的、分布式的、版本化的NoSQL数据库(即非关系型数据库),依托Hadoop分布式文件系统HDFS提供分布式数据存储,利用MapReduce来处理海量数据,用Zookeeper作为其分布式协同服务,一般用于存储海量数据。HDFS和HBase的区别在于,HDFS是文件系统,而HBase是数据库。HBase只是一个NoSQL数据库,把数据存在HDFS上。可以把HBase当做是MySQL,把HDFS当做是硬盘。
这里表示的就是数据存储的位置和名字;以及簇的信息
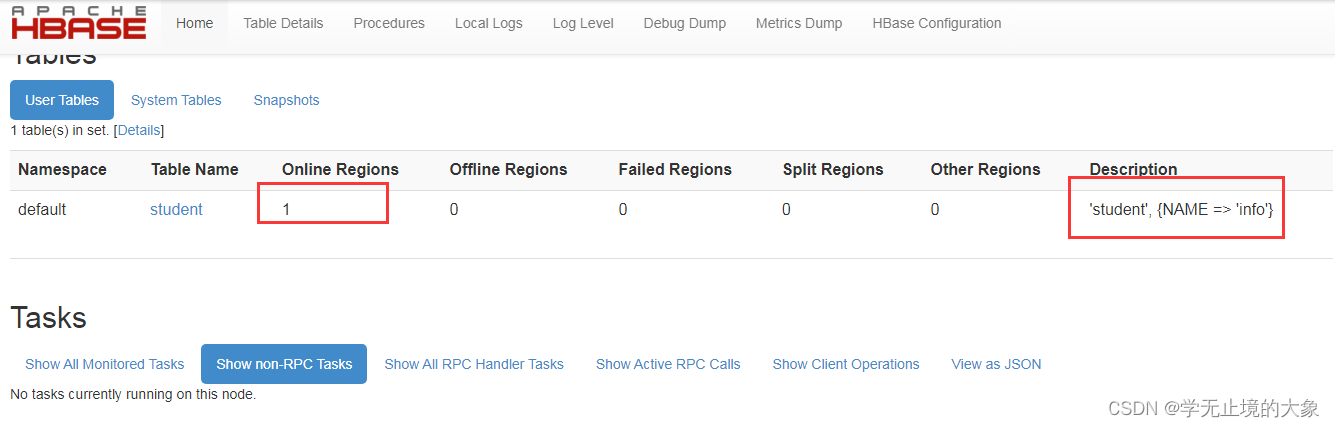
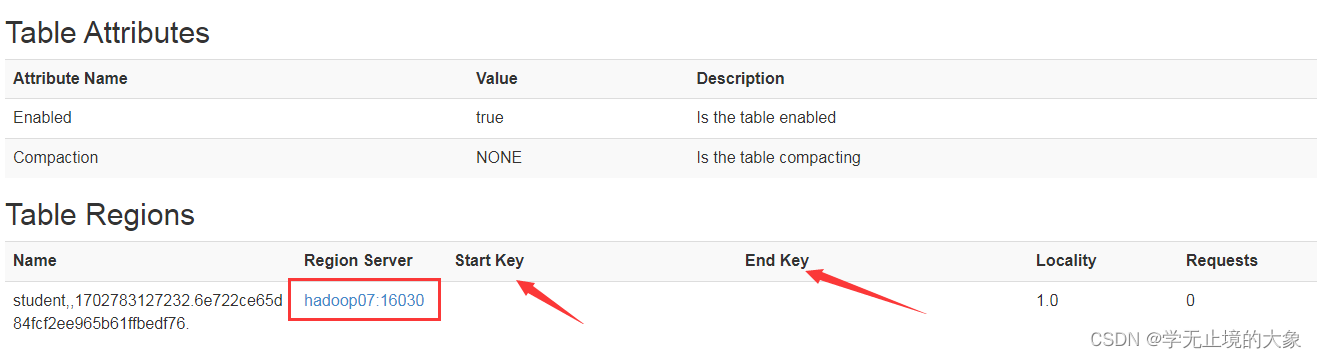
进入到具体的表中就是我们数据存的具体的节点和 区的开始位置和结束位置;
startkey 预分区的开始
endkey 预分区的结束
HBase 定义
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
1)Master
Master是所有Region Server的管理者,其实现为HRegionServer,主要作用有:
对于表的DDL操作:create,delete,alter;
对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
2)Zookeeper:
HBase通过Zookeeper来做Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
3)WAL:
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写入Write-Ahead logfile的文件中,然后再写入到Memstore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
4)MemStore:
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
5)StoreFile:
保存实际数据的物理文件,StoreFile以HFile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在StoreFile上是有序的。
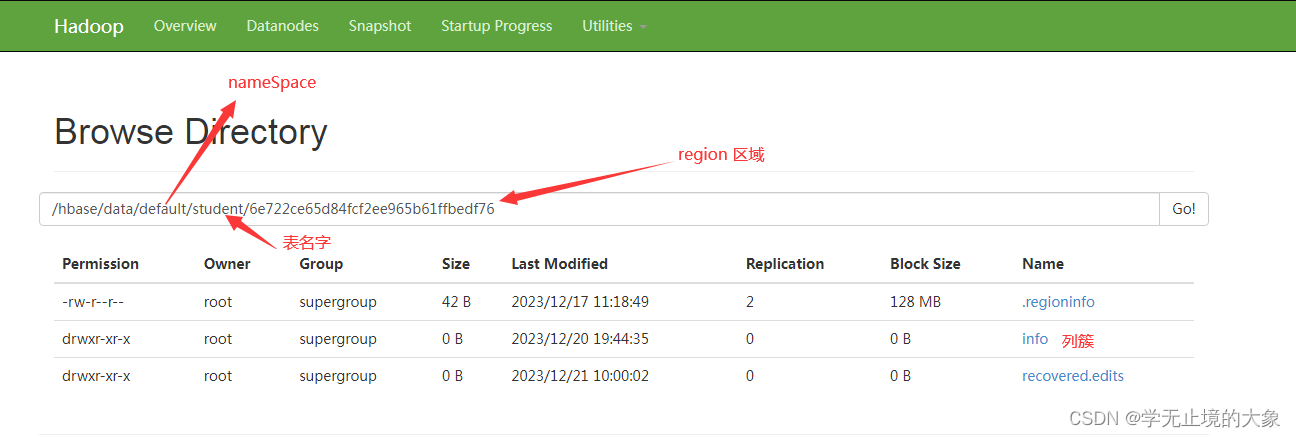
1)Name Space
命名空间,类似于关系型数据库的DataBase概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase的内置表,default表示用户默认使用的命名空间。
2)Region(区域)
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要生命列簇即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询时智能根据RowKey进行检索,所以RowKey的设计十分重要。
4)Cloumn
HBase中的每个列都由Cloumn Family(列簇)和Cloumn Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列簇,而列限定符无需预先定义。
5)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入HBase的时间。
HBASE 中通过rowkey和columns确定的为一个存贮单元称为cell。每个 cell都保存 着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由HBASE(在数据写入时自动 )赋值,此时时间戳是精确到毫秒 的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版 本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,HBASE提供 了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段 时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
可以根据时间戳来进行数据的取:
scan ‘namespace名:表名’, {COLUMN => ‘列簇:列’, TIMERANGE => [开始时间戳,结束时间戳]}
scan ‘student’, {COLUMN => ‘c1’, TIMERANGE => [1658827317000,1658913717000]}
6)Cell
由
{ RowKey, ColumnFamily: ColumnQualifier, TimeStamp}
唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存贮。
Hbase是bigtable的开源山寨版本。是建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
RowKey
与nosql数据库们一样,RowKey是用来检索记录的主键。访问HBASE table中的行,只有三种方式:
1.通过单个RowKey访问
2.通过RowKey的range(正则)
3.全表扫描
RowKey行键 (RowKey)可以是任意字符串(最大长度是64KB,实际应用中长度一般为 10-100bytes),在HBASE内部,RowKey保存为字节数组。存储时,数据按照RowKey的字典序(byte order)排序存储。设计RowKey时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
Column Family
列族:HBASE表中的每个列,都归属于某个列族。列族是表的schema的一部 分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如 courses:history,courses:math都属于courses 这个列族。
Cell
由{rowkey, column Family:columu, version} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。
关键字:无类型、字节码
命名空间 命名空间的结构:
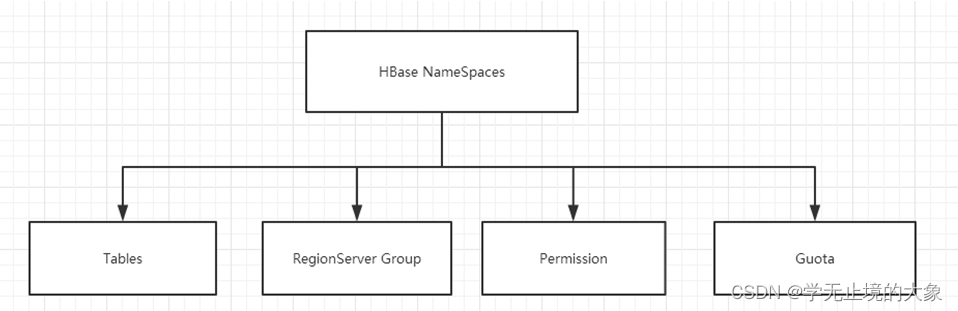
- Table:表,所有的表都是命名空间的成员,即表必属于某个命名空间,如果没有指定,则在default默认的命名空间中。
- RegionServer group:一个命名空间包含了默认的RegionServer Group。
- Permission:权限,命名空间能够让我们来定义访问控制列表ACL(Access Control List)。例如,创建表,读取表,删除,更新等等操作。
- Quota:限额,可以强制一个命名空间可包含的region的数量。
默认的空间:
有命名空间:
比如:
name_space001: student 就是这个命名空间下的表;
HBase 中的表一般有这样的特点:
1、大:一个表可以有上十亿行,上百万列;
2、面向列:面向列(族)的存储和权限控制,列(族)独立检索;
3、稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
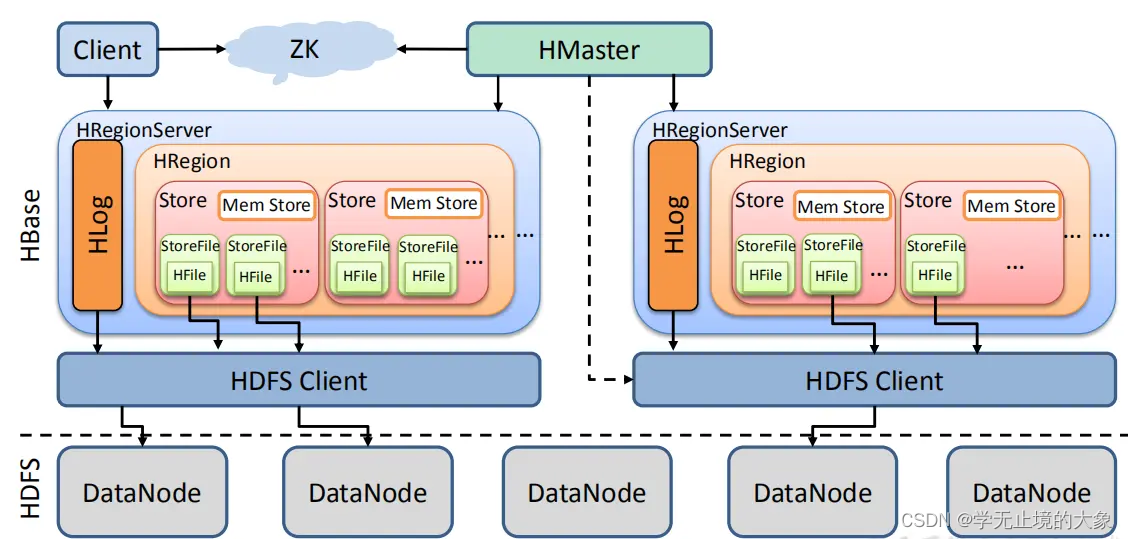
HBase储存结构详解
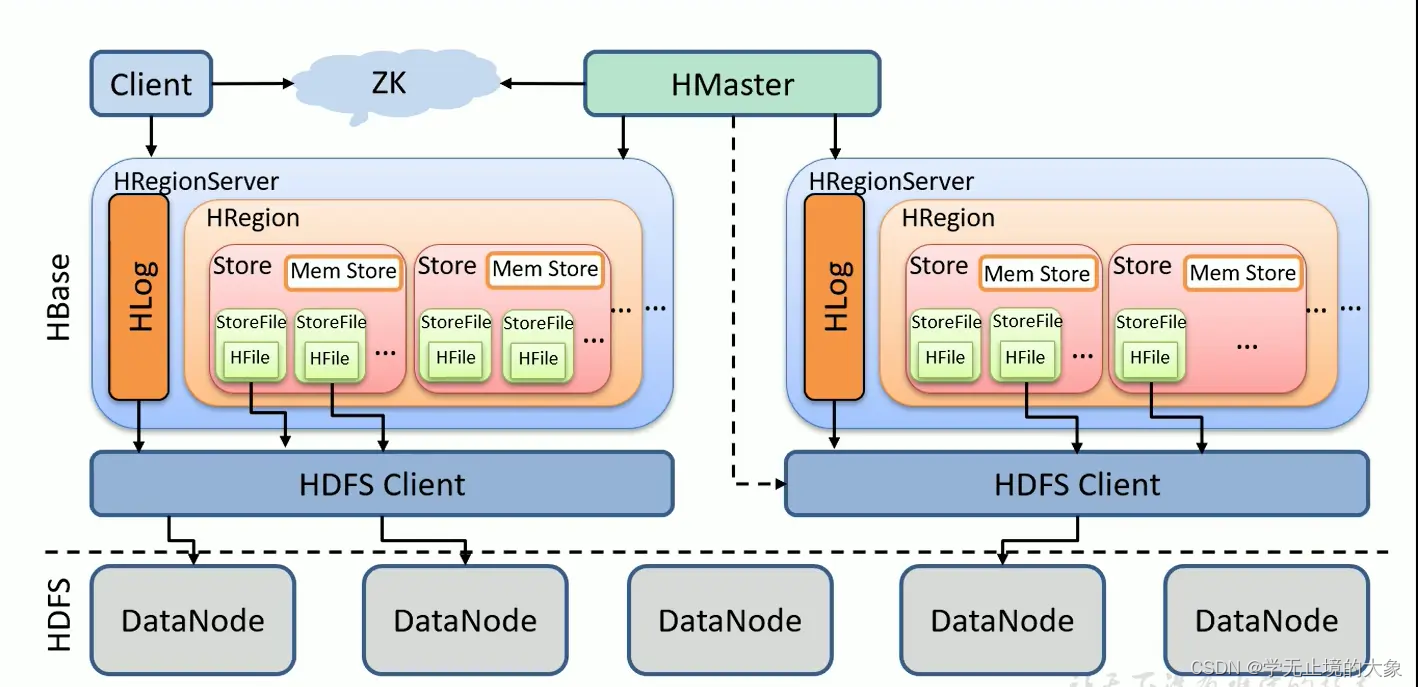
从上面的架构图可以看出HBase是建立在hadoop之上的,HBase底层依赖于HDFS。HBase有3个重要的组件:Zookeeper、HMaster、HRegionServer。
Zookeeper为整个HBase集群提供协助的服务,HMaster主要用于监控和操作集群的所有RegionServer。RegionServer主要用于服务和管理分区(Regions)
1、HDFS
HBase底层依赖于HDFS的
2、HMaster
HMaster是HBase集群架构中的主节点,通常一个HBase集群存在多个HMaster节点,其中一个为Active Master,其余为Backup Master。
Hbase每时每刻只有一个HMaster主服务器程序在运行,HMaster将region分配给HRegionServer,协调HRegionServer的负载并维护集群的状态。Hmaster不会对外提供数据服务,而是由HRegionServer负责所有regions的读写请求及操作。
由于HMaster只维护表和region的元数据,负责Region的分配及数据库的创建和删除等操作而不参与数据的输入/输出过程,HMaster失效仅仅会导致所有的元数据无法被修改,但表的数据读/写还是可以正常进行的。
HMaster的作用:
A、调控Region server的工作
为Region server分配region,
负责HRegionServer的负载均衡,
监控集群中的Region server的工作状态, 发现失效的HRegionServer并重新分配其上的Hregion(通过监听zookeeper对于ephemeral node状态的通知)。
备注:
HRegion,习惯把它称为region,表的意思
HRegionServer,习惯把它称为Region server,HRegionServer是HBase集群架构中的从节点
B、管理数据库
提供创建,删除或者更新表格的接口。
.3、HRegionServer
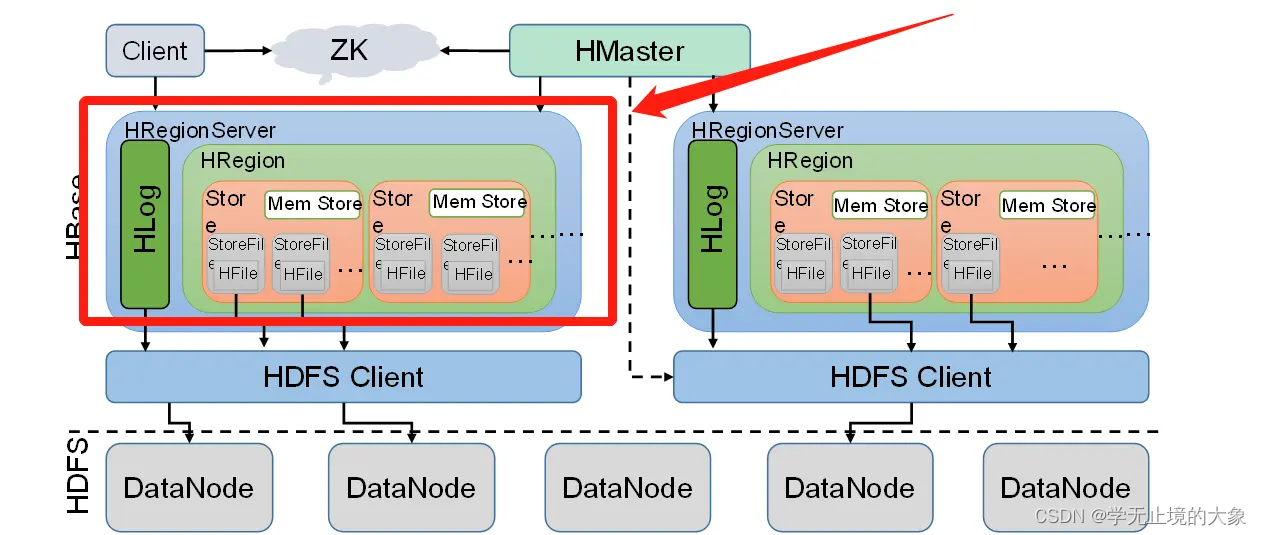
HRegionServer是HBase集群架构中的从节点,HBase中的表是根据row key的值水平分割成所谓的region的。一个region包含表中所有row key位于region的起始键值和结束键值之间的行。
集群中负责管理Region的结点叫做Region server。Region server负责数据的读写。每一个Region server大约可以管理1000个region。
备注:HRegionServer,习惯把它称为Region server,HRegionServer是HBase集群架构中的从节点。(一些文章写的是Region server、一些写的是HRegionServer,两个意思都是一样的)
1、HRegionServer由如下几个部分组成
一个HRegionServer会有多个HRegion和一个HLog。
HLog:预写入日志,防止内存中数据丢失
HRegion:表,一个HRegionServer可以维护多个HRegion(习惯称为一个Region Server可以维护多个Region)
2、HRegionServer的职责
维护HMaster分配给它的HRegion,处理对这些HRegion的IO请求,也就是说客户端直接和HRegionServer打交道。
4、HRegion
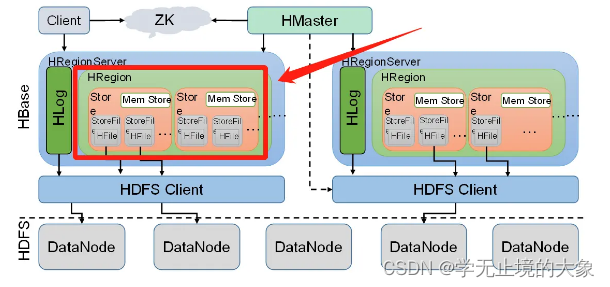
概述
Region是HBase数据管理的基本单位,每个HRegion由多个Store构成,每个Store保存一个列族(Columns Family),表有几个列族,则有几个Store,每个Store由一个MemStore和多个StoreFile组成,MemStore是Store在内存中的内容,写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
Region相当于数据库中的表
Region/Store/StoreFile/Hfile之间的关系
1、 Region
table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。
Region按大小分隔,表中每一行只能属于一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
2、 Store
每一个region有一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store(即有几个ColumnFamily,也就有几个Store)。一个Store由一个memStore和0或多个StoreFile组成。
HBase以store的大小来判断是否需要切分region。
store的数据存储在两个地方MemStore和StoreFile
3、 MemStore
写缓存,memStore 是放在内存里的。由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile(当memStore的大小达到一个阀值【默认64MB】时,memStore会被flush到文件),每次刷写都会形成一个新的 HFile。
4、StoreFile
memStore内存中的数据写到文件后就是StoreFile(即memstore的每次flush操作都会生成一个新的StoreFile),StoreFile底层是以HFile的格式保存。
5、HFile
HFile是HBase中KeyValue数据的存储格式,是hadoop的二进制格式文件。一个StoreFile对应着一个HFile。而HFile是存储在HDFS之上的。
hbase的原数据存储在 zookeeper里边:
zkCli.sh
就可以进行到zk的集群中;


HBase读流程
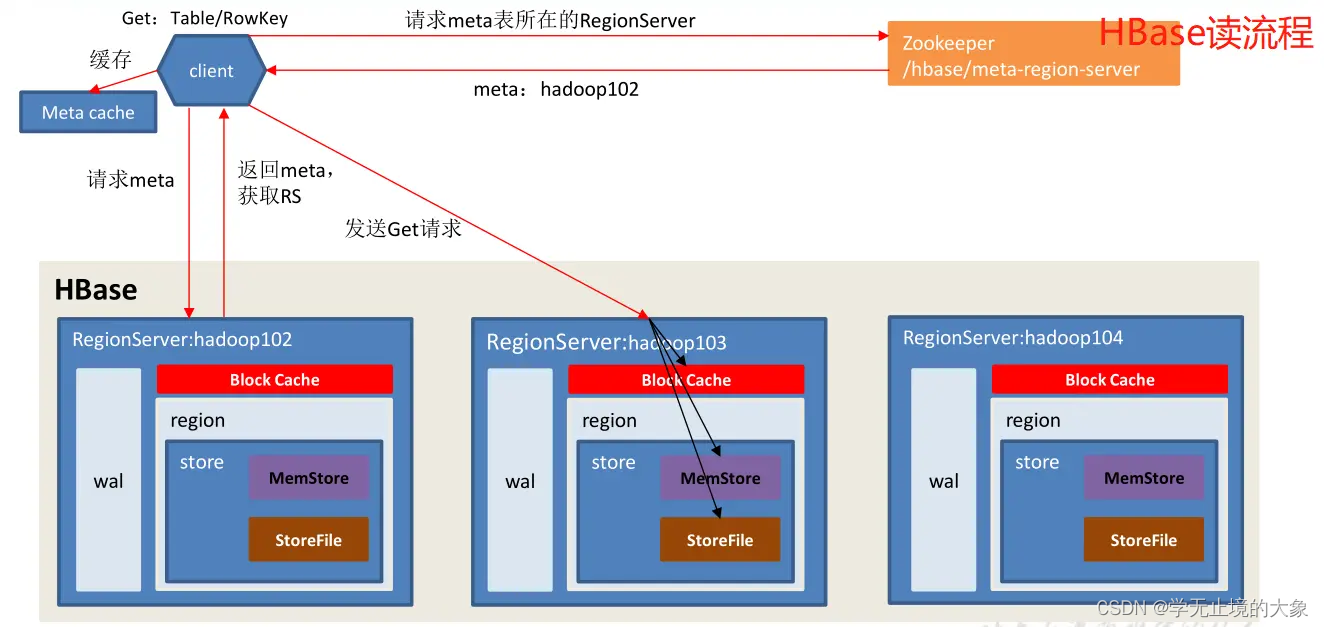
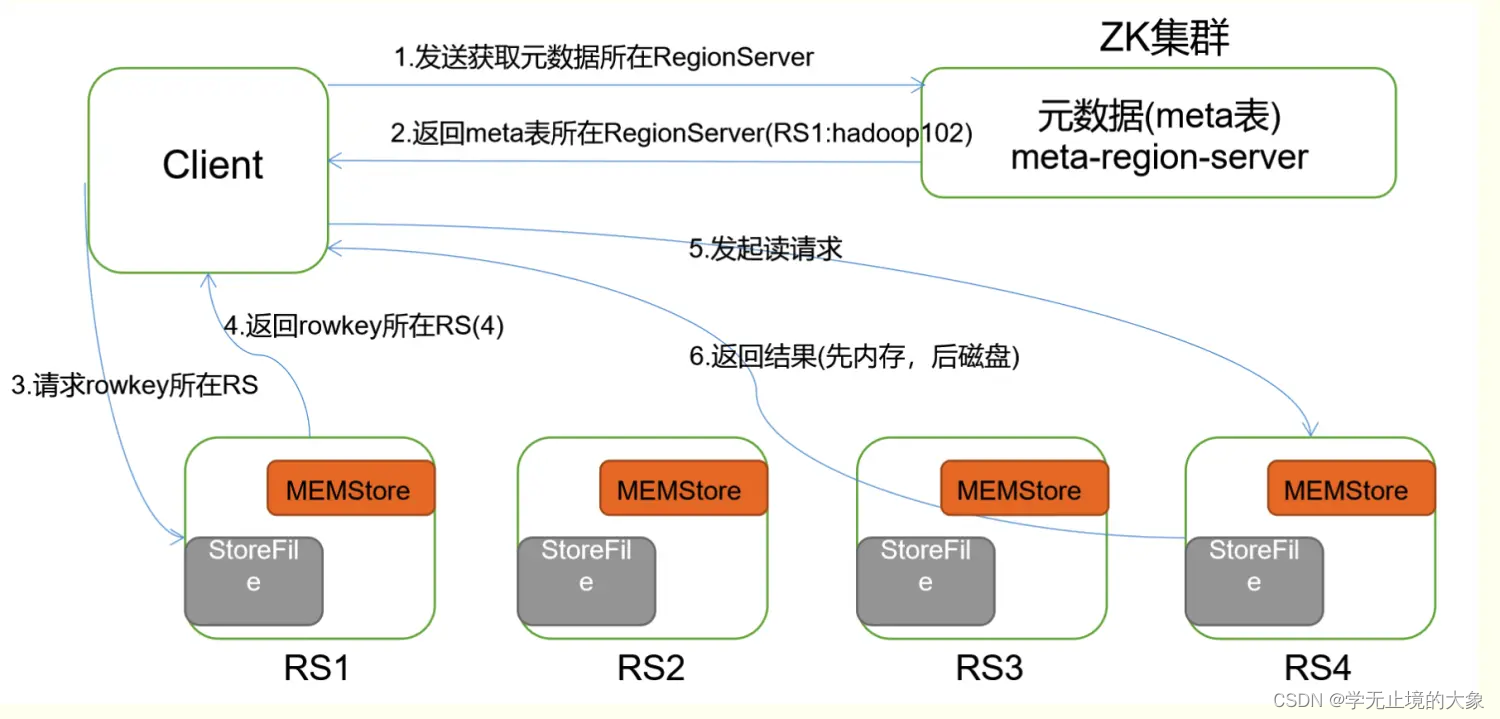
HBase读数据流程:
1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4)分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
5)将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到Block Cache。
6)将合并后的最终结果返回给客户端。
HBase写流程
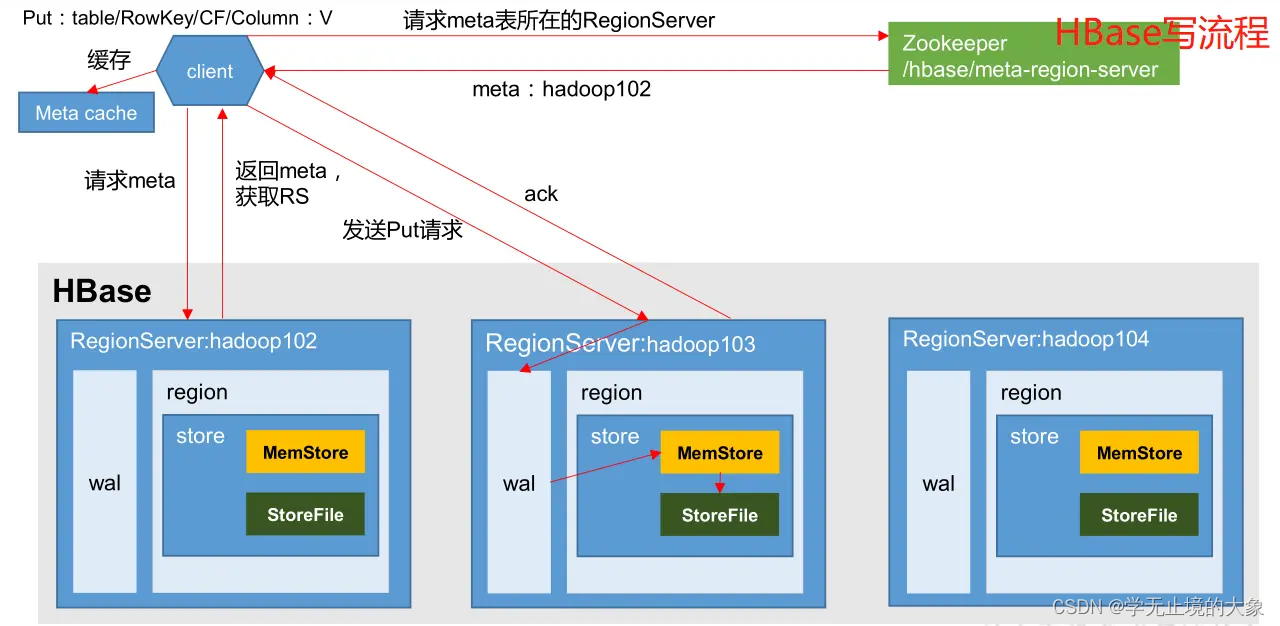
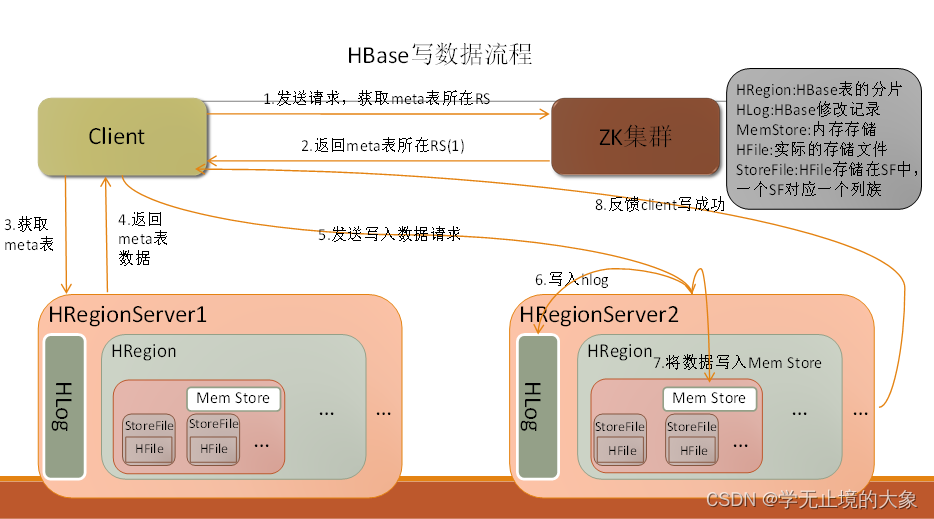
1、客户端先访问zookeeper,获取Meta表位于那个region server
2、访问Meta表对应的region server服务器,根据请求的信息(namespace:table/rowkey),在meta表中查询出目标数据位于哪个region server的哪个region中。
并将该表的region信息以及meta表的位置信息缓存到客户端的meta cache,方便下次访问。
3、与目标数据的region server进行通讯
4、将数据写入到WAL中
5、将数据写入到对应的memstore中,
6、向客户端发送写入成功的信息
7、等达到memstore的刷写时机后,将数据刷写到HFILE中
MemStore Flush刷写

1.当某个MemStore的大小达到了hbase.hregion.memstore.flush.size(默认值 128M),其所在 region 的所有 memstore (对应的列簇)都会刷写。将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据;
当达到128M的时候会触发flush memstore,当达到128M * n还没法触发flush时候会抛异常来拒绝写入。两个相关参数的默认值如下:
hbase.hregion.memstore.flush.size=128M(默认)
hbase.hregion.memstore.block.multiplier=4(默认)
2.当 region server 中 memstore 的总大小达到java_heapsize(应用的堆内存)
hbase.regionserver.global.memstore.size(默认值 0.4)
hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95),
region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写。直到 region server中所有 memstore 的总大小减小到上述值以下。当 region server 中 memstore 的总大小达到
java_heapsize*hbase.regionserver.global.memstore.size(默认值 0.4)时,会阻止继续往所有的 memstore 写数据。
3.到达自动刷写的时间,也会触发 memstore flush。自动刷新的时间间隔由该属性进行配置 hbase.regionserver.optionalcacheflushinterval(默认 1 小时)。
4.当 WAL 文件的数量超过 hbase.regionserver.maxlogs,region 会按照时间顺序依次进行刷写,直到 WAL 文件数量减小到 hbase.regionserver.maxlogs 以下(该属性名已经废弃,现无需手动设置,最大值为 32)。
数据合并:StoreFile Compaction
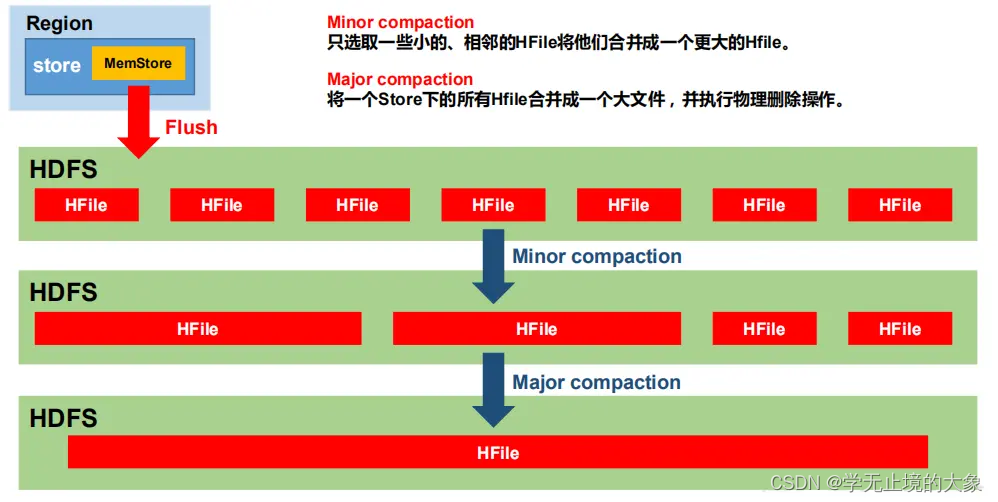
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清除掉过期和删除的数据,会进行StoreFile Compaction。
Compaction分为两种,分别时Minor Compaction和Major Compaction。Minor Compaction会将临时的若干较小的HFile合并成一个较大的HFile,但不会清理过期和删除的数据。Major Compaction会将一个Store下的所有HFile合并为一个大HFile,并且会清理掉过期和删除的数据。
数据拆分:Region Split

默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑,HMaster 有可能会将某个 Region 转移给其他的 Region Server。
Region Split 时机:
1.当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize,该 Region 就会进行拆分(0.94 版本之前)。
- 当 1 个 region 中 的 某 个 Store 下所有 StoreFile 的 总 大 小 超 过 Min(R^2 *“hbase.hregion.memstore.flush.size”,hbase.hregion.max.filesize"),该 Region 就会进行拆分,其中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之后)。















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









