






Prerequisite
- 深度学习基础
- 耐得住今天5月20日被秀的寂寞
比赛简介
任务
主要针对新人上手计算机视觉赛事,此次比赛任务为给定图片输出字符,即文本识别。
数据集
训练集数据包括3W张照片,验证集数据包括1W张照片,每张照片包括颜色图像和对应的编码类别和具体位置;为了保证比赛的公平性,测试集A包括4W张照片,测试集B包括4W张照片。
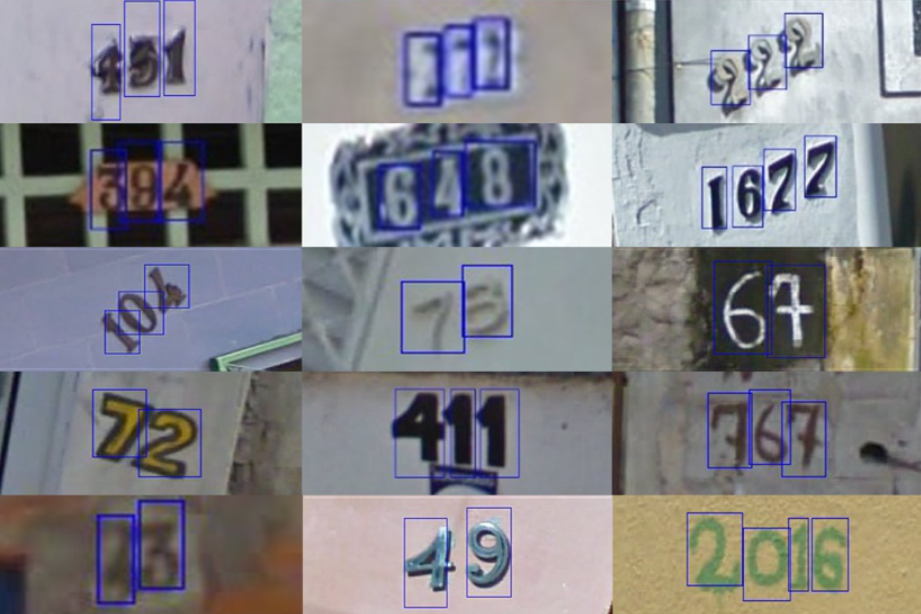
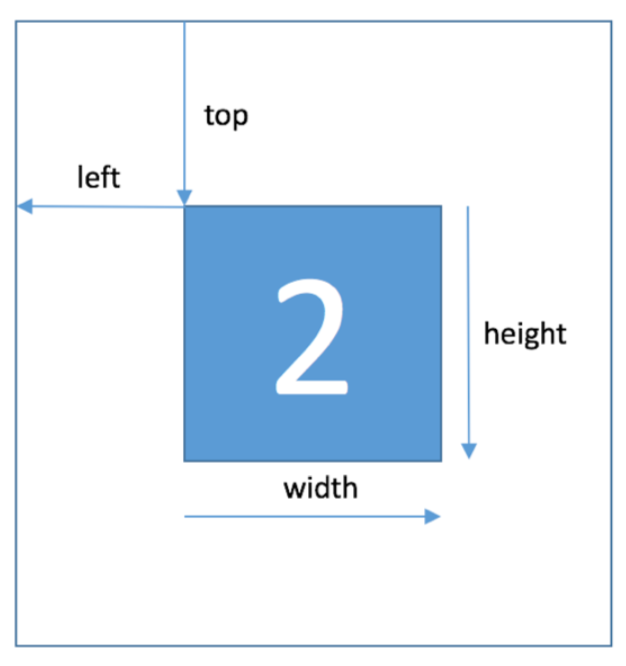
出题方已经给出训练集和验证集的字符位置信息。
即是下图:

评价指标
a c c u r a c y = 字 符 识 别 正 确 的 图 片 数 量 总 图 片 数 量 accuracy = \frac{字符识别正确的图片数量}{总图片数量} accuracy=总图片数量字符识别正确的图片数量
如何获得0分
使用SVHN原始数据集进行训练。
赛题难点
赛题不同于一般的图像数字识别,其难点在于不定长的字符识别。因而如何处理不定长是本题的关键。
解题思路
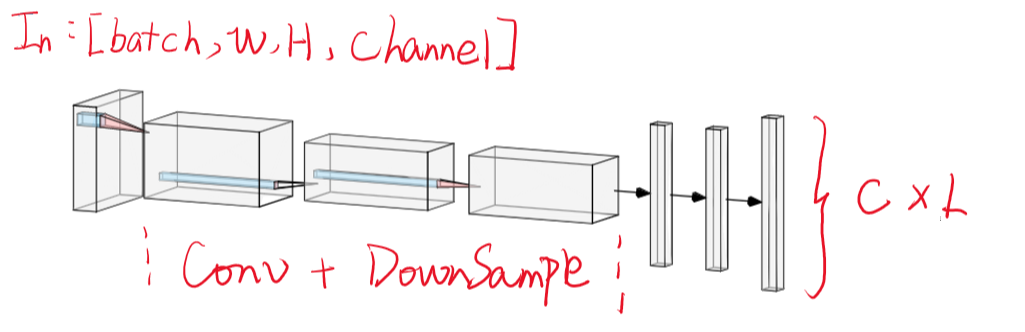
定长字符识别
设字符类别数目为 C C C,设置一个最大字符长度 L L L,用卷积网络提取图像特征后,特征整合后(FC,RNN等),最后输出一个 C × L C\times L C×L长度的神经元层。并用 S o f t m a x Softmax Softmax做分类。
架构图
举个例子
设
C
=
11
C=11
C=11和
L
=
8
L=8
L=8,假设有真实标签:
123
123
123,有一输出:
1
_
22
_
_
33
1\_22\_\_33
1_22__33
至于有
22
,
33
22,33
22,33的出现,原因在于类似于下面情况:
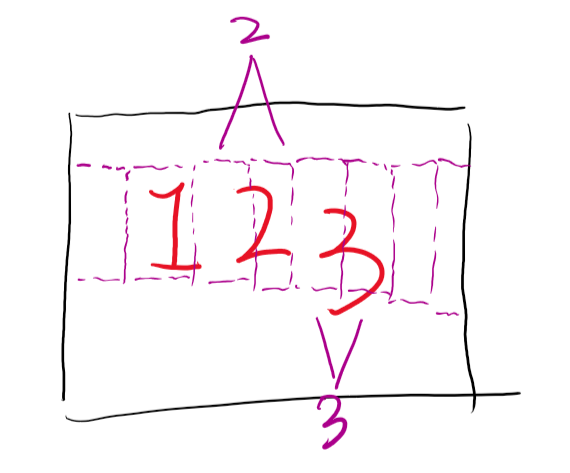
只是一个类似思考而已, 和目标检测没关系
因而对于这种情况,可以通过写规则的方法解决,即是将连续重复出现的字符和空白进行删除。
但是若真实标签为
1223
1223
1223那么这种方法会输的很惨。
不定长字符识别
此方法可以很好的解决上述问题。
please jump: 一文读懂CRNN+CTC文字识别
男女搭配法
其实这类题,很容易就会想到先用目标检测提取字符方框,再用图像分类。并且目标检测的准确率和高效性目前都有不错的效果,比如 Y O L O YOLO YOLO等等。
至于这次比赛到底是CRNN还是OD+Clf会更胜一筹,还是会有其他算法,模型架构横空出世,咱们码场见!

永远要在一起哦















 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









