






目录
Prequisite
- 吃饱喝足
分类
简要说一下SVM的分类:
- 线性可分SVM
- 线性不可分SVM
1.软间隔法
2.核技巧
线性可分SVM
引入
假设给定训练集:
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
,
(
x
n
,
y
n
)
}
T=\{(x_1, y_1),(x_2, y_2),\cdots,(x_n, y_n)\}
T={(x1,y1),(x2,y2),⋯,(xn,yn)}
其中,
x
i
∈
R
p
,
y
∈
Y
=
{
−
1
,
1
}
,
i
=
1
,
2
,
⋯
,
n
x_i\in R^p,y\in Y=\{-1,1\},i=1,2,\cdots,n
xi∈Rp,y∈Y={−1,1},i=1,2,⋯,n,并且假设有样本集线性可分。
设有分离超平面:
w
T
x
+
b
=
0
w^Tx+b=0
wTx+b=0
使得样本集被分成正负两部分。
以及分类决策函数:
f
(
x
)
=
s
i
g
n
(
w
T
x
+
b
)
f(x)=sign(w^Tx+b)
f(x)=sign(wTx+b)
并有
w
T
x
+
b
>
0
w^Tx+b>0
wTx+b>0时,为正类;
w
T
+
b
<
0
w^T+b<0
wT+b<0时,为负类。
很自然的,我们只需要:
y
i
(
w
T
x
i
+
b
)
>
0
y_i(w^Tx_i+b)>0
yi(wTxi+b)>0
对每个样本
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)成立即可。
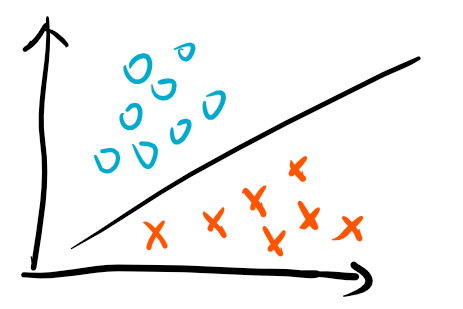
但这存在一个问题,考虑下面一个例子:
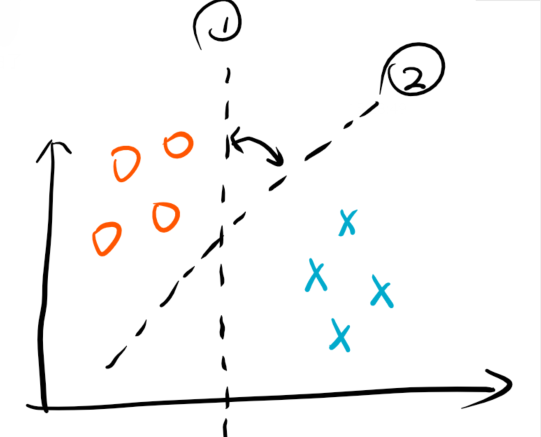
可以发现,满足上面条件的超平面有无穷多个。但是从样本点来看,是存在一个相比较而言更加好的一个超平面,那么就是处于
H
1
,
H
2
H_1,H_2
H1,H2中间的超平面,而SVM正是可以求解这个最优超平面的算法。
算法
Functional/Geometric Margin
首先介绍两个概念:
函数间隔(functional margin):
γ
^
i
=
y
i
(
w
T
x
i
+
b
)
\hat\gamma_i=y_i(w^Tx_i+b)
γ^i=yi(wTxi+b)
假如,我们已经求解得到最优超平面,即是有
w
,
b
w,b
w,b。但是,实际上
λ
w
,
λ
b
\lambda w,\lambda b
λw,λb也同样为那个最优超平面的系数。因此,首先,基于这一点,函数间隔只能描述相对大小;其二,为了解决这个多解问题,我们应该引入一些限制条件,比如
∣
∣
w
∣
∣
=
1
\vert\vert w\vert\vert=1
∣∣w∣∣=1,进行归一化。而为了不受
w
,
b
w,b
w,b的成倍变化带来的大小变化,我们引入几何间隔。
几何间隔(geometric margin):
γ
i
=
y
i
(
w
T
x
i
+
b
)
∣
∣
w
∣
∣
\gamma_i=\frac{y_i(w^Tx_i+b)}{\vert\vert w\vert\vert}
γi=∣∣w∣∣yi(wTxi+b)
注意:上述距离一般为,带符号的距离(signed distance),而当样本点被正确分类时,那么就成为样本点到超平面的距离。
硬间隔最大化
SVM的间隔最大化思想就是,找到
w
,
b
w,b
w,b使得,距离超平面最近的那个点,其到超平面的距离最大。基于这个想法,我们有:
max
w
,
b
min
i
γ
i
s
.
t
.
y
i
(
w
T
x
i
+
b
)
>
0
,
i
=
1
,
2
,
⋯
,
n
又
:
γ
i
=
y
i
(
w
T
x
i
+
b
)
∣
∣
w
∣
∣
有
:
max
w
,
b
min
i
y
i
(
w
T
x
i
+
b
)
∣
∣
w
∣
∣
=
max
w
,
b
1
∣
∣
w
∣
∣
min
i
y
i
(
w
T
x
i
+
b
)
\begin{aligned} &\max_{w,b}\min_{i}\gamma_i\\ &s.t.\quad y_i(w^Tx_i+b)>0,i=1,2,\cdots,n\\ 又:\\ &\gamma_i=\frac{y_i(w^Tx_i+b)}{\vert\vert w\vert\vert}\\ 有:\\ &\max_{w,b}\min_{i}\frac{y_i(w^Tx_i+b)}{\vert\vert w\vert\vert}\\ &=\max_{w,b}\frac{1}{\vert\vert w\vert\vert}\min_{i}y_i(w^Tx_i+b)\\\end{aligned}
又:有:w,bmaximinγis.t.yi(wTxi+b)>0,i=1,2,⋯,nγi=∣∣w∣∣yi(wTxi+b)w,bmaximin∣∣w∣∣yi(wTxi+b)=w,bmax∣∣w∣∣1iminyi(wTxi+b)
又由上文分析,
y
i
(
w
T
x
i
+
b
)
=
γ
^
i
y_i(w^Tx_i+b)=\hat\gamma_i
yi(wTxi+b)=γ^i可以被任意放缩,那么:
令
:
min
i
γ
^
i
=
1
问
题
转
化
为
:
max
w
,
b
1
∣
∣
w
∣
∣
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
⋯
,
n
也
即
是
:
min
w
,
b
1
2
w
T
w
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
⋯
,
n
\begin{aligned}令:\\ &\min_i\hat\gamma_i=1\\ 问题转化为:\\ &\max_{w,b}\frac{1}{\vert\vert w\vert\vert}\\ &s.t.\quad y_i(w^Tx_i+b)\ge1,i=1,2,\cdots,n\\ 也即是:\\ &\min_{w,b}\frac{1}{2}w^Tw\\ &s.t.\quad y_i(w^Tx_i+b)\ge1,i=1,2,\cdots,n\\ \end{aligned}
令:问题转化为:也即是:iminγ^i=1w,bmax∣∣w∣∣1s.t.yi(wTxi+b)≥1,i=1,2,⋯,nw,bmin21wTws.t.yi(wTxi+b)≥1,i=1,2,⋯,n
对偶算法
拉格朗日函数
通过上文的分析,我们得到目标函数和限制条件:
min
w
,
b
1
2
w
T
w
s
.
t
.
1
−
y
i
(
w
T
x
i
+
b
)
≤
0
,
i
=
1
,
2
,
⋯
,
n
\begin{aligned} &\min_{w,b}\frac{1}{2}w^Tw\\ &s.t.\quad 1-y_i(w^Tx_i+b)\le0,i=1,2,\cdots,n\\ \end{aligned}
w,bmin21wTws.t.1−yi(wTxi+b)≤0,i=1,2,⋯,n
很自然的,我们想到构造拉格朗日函数,有:
L
(
w
,
b
,
λ
i
)
=
1
2
w
T
w
+
∑
i
n
λ
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
s
.
t
λ
i
≥
0
\begin{aligned} &\mathcal L(w,b,\lambda_i)=\frac{1}{2}w^Tw+\sum_i^n\lambda_i(1-y_i(w^Tx_i+b))\\ &s.t\quad \lambda_i\ge0\\ \end{aligned}
L(w,b,λi)=21wTw+i∑nλi(1−yi(wTxi+b))s.tλi≥0
此时,问题就变成了,无约束的优化问题:
min
w
,
b
max
λ
i
L
(
w
,
b
,
λ
i
)
=
1
2
w
T
w
+
∑
i
n
λ
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
s
.
t
λ
i
≥
0
\begin{aligned} \min_{w,b}\max_{\lambda_i}&\mathcal L(w,b,\lambda_i)=\frac{1}{2}w^Tw+\sum_i^n\lambda_i(1-y_i(w^Tx_i+b))\\ &s.t\quad \lambda_i\ge0\\ \end{aligned}
w,bminλimaxL(w,b,λi)=21wTw+i∑nλi(1−yi(wTxi+b))s.tλi≥0
对偶转换
由拉格朗日的对偶性,我们可以知,上述问题可以转换为:
max
λ
i
min
w
,
b
L
(
w
,
b
,
λ
i
)
=
1
2
w
T
w
+
∑
i
n
λ
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
s
.
t
λ
i
≥
0
\begin{aligned} \max_{\lambda_i}\min_{w,b}&\mathcal L(w,b,\lambda_i)=\frac{1}{2}w^Tw+\sum_i^n\lambda_i(1-y_i(w^Tx_i+b))\\ &s.t\quad \lambda_i\ge0\\ \end{aligned}
λimaxw,bminL(w,b,λi)=21wTw+i∑nλi(1−yi(wTxi+b))s.tλi≥0
关于为什么要进行对偶转换,原因有两点:1.更容易求解。2.自然引入核函数,进来推广到非线性空间。
对偶问题证明
please jump:SVM对偶问题
对偶问题的求解
由上文可知对偶问题为:
max
λ
i
min
w
,
b
L
(
w
,
b
,
λ
i
)
=
1
2
w
T
w
+
∑
i
n
λ
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
s
.
t
λ
i
≥
0
\begin{aligned} \max_{\lambda_i}\min_{w,b}&\mathcal L(w,b,\lambda_i)=\frac{1}{2}w^Tw+\sum_i^n\lambda_i(1-y_i(w^Tx_i+b))\\ &s.t\quad \lambda_i\ge0\\ \end{aligned}
λimaxw,bminL(w,b,λi)=21wTw+i∑nλi(1−yi(wTxi+b))s.tλi≥0
现在就来求解
w
,
b
w, b
w,b:
先看min部分:
min
w
,
b
L
(
w
,
b
)
=
1
2
w
T
w
+
∑
i
n
λ
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
=
1
2
w
T
w
+
∑
i
n
λ
i
−
∑
i
n
λ
i
y
i
(
w
T
x
i
+
b
)
)
∂
L
(
w
,
b
)
∂
b
=
−
∑
i
n
λ
i
y
i
=
0
∂
L
(
w
,
b
)
∂
w
=
w
−
∑
i
n
λ
i
y
i
x
i
=
0
综
上
有
:
∑
i
n
λ
i
y
i
=
0
w
=
∑
i
n
λ
i
y
i
x
i
代
入
对
偶
问
题
有
:
max
λ
i
L
(
λ
i
)
=
1
2
(
∑
i
n
λ
i
y
i
x
i
)
T
(
∑
i
n
λ
i
y
i
x
i
)
+
∑
i
n
λ
i
−
∑
i
n
λ
i
y
i
(
w
T
x
i
+
b
)
=
1
2
(
∑
i
n
λ
i
y
i
x
i
)
T
(
∑
j
n
λ
j
y
j
x
j
)
+
∑
i
n
λ
i
−
∑
i
n
λ
i
y
i
(
(
∑
j
n
λ
j
y
j
x
j
)
T
x
i
)
−
∑
i
n
λ
i
y
i
b
=
1
2
∑
i
n
∑
j
n
(
λ
i
y
i
x
i
)
T
λ
j
y
j
x
j
−
∑
i
n
∑
j
n
λ
i
y
i
(
λ
j
y
j
x
j
)
T
x
i
+
∑
i
n
λ
i
=
1
2
∑
i
n
∑
j
n
(
λ
i
λ
j
y
i
y
j
)
x
i
T
x
j
−
∑
i
n
∑
j
n
(
λ
i
λ
j
y
i
y
j
)
x
j
T
x
i
+
∑
i
n
λ
i
又
x
j
T
x
i
=
x
i
T
x
j
=
−
1
2
∑
i
n
∑
j
n
(
λ
i
λ
j
y
i
y
j
)
x
i
T
x
j
+
∑
i
n
λ
i
\begin{aligned} &\min_{w,b}\mathcal L(w,b)=\frac{1}{2}w^Tw+\sum_i^n\lambda_i(1-y_i(w^Tx_i+b))\\ &\qquad \qquad\quad =\frac{1}{2}w^Tw+\sum_i^n\lambda_i-\sum_i^n\lambda_i y_i(w^Tx_i+b))\\ &\frac{\partial L(w,b)}{\partial b}=-\sum_i^n\lambda_iy_i =0\\ &\frac{\partial L(w,b)}{\partial w}=w-\sum_i^n\lambda_iy_ix_i=0\\ 综上有:\\ &\sum_i^n\lambda_iy_i =0\\ &w=\sum_i^n\lambda_iy_ix_i\\ 代入对偶问题有:\\ &\max_{\lambda_i}\mathcal L(\lambda_i)=\frac{1}{2}(\sum_i^n\lambda_iy_ix_i)^T(\sum_i^n\lambda_iy_ix_i)+\sum_i^n\lambda_i-\sum_i^n\lambda_iy_i(w^Tx_i+b)\\ &\qquad\qquad\ \ \, =\frac{1}{2}(\sum_i^n\lambda_iy_ix_i)^T(\sum_j^n\lambda_jy_jx_j)+\sum_i^n\lambda_i-\sum_i^n\lambda_iy_i((\sum_j^n\lambda_jy_jx_j)^Tx_i)\\ &\qquad\qquad\ \ \,-\sum_i^n\lambda_iy_ib\\ &\qquad\qquad\ \ \,=\frac{1}{2}\sum_i^n\sum_j^n(\lambda_iy_ix_i)^T\lambda_jy_jx_j-\sum_i^n\sum_j^n\lambda_iy_i(\lambda_jy_jx_j)^Tx_i+\sum_i^n\lambda_i\\ &\qquad\qquad\ \ \,=\frac{1}{2}\sum_i^n\sum_j^n(\lambda_i\lambda_jy_iy_j)x_i^Tx_j-\sum_i^n\sum_j^n(\lambda_i\lambda_jy_iy_j)x_j^Tx_i+\sum_i^n\lambda_i\\ &又\quad x_j^Tx_i=x_i^Tx_j\\ &\qquad\qquad\ \ \,=-\frac{1}{2}\sum_i^n\sum_j^n(\lambda_i\lambda_jy_iy_j)x_i^Tx_j+\sum_i^n\lambda_i\\ \end{aligned}
综上有:代入对偶问题有:w,bminL(w,b)=21wTw+i∑nλi(1−yi(wTxi+b))=21wTw+i∑nλi−i∑nλiyi(wTxi+b))∂b∂L(w,b)=−i∑nλiyi=0∂w∂L(w,b)=w−i∑nλiyixi=0i∑nλiyi=0w=i∑nλiyixiλimaxL(λi)=21(i∑nλiyixi)T(i∑nλiyixi)+i∑nλi−i∑nλiyi(wTxi+b) =21(i∑nλiyixi)T(j∑nλjyjxj)+i∑nλi−i∑nλiyi((j∑nλjyjxj)Txi) −i∑nλiyib =21i∑nj∑n(λiyixi)Tλjyjxj−i∑nj∑nλiyi(λjyjxj)Txi+i∑nλi =21i∑nj∑n(λiλjyiyj)xiTxj−i∑nj∑n(λiλjyiyj)xjTxi+i∑nλi又xjTxi=xiTxj =−21i∑nj∑n(λiλjyiyj)xiTxj+i∑nλi
综上,max部分为:
max
λ
i
L
(
λ
i
)
=
−
1
2
∑
i
n
∑
j
n
(
λ
i
λ
j
y
i
y
j
)
x
i
T
x
j
+
∑
i
n
λ
i
\max_{\lambda_i} \mathcal L(\lambda_i)=-\frac{1}{2}\sum_i^n\sum_j^n(\lambda_i\lambda_jy_iy_j)x_i^Tx_j+\sum_i^n\lambda_i
λimaxL(λi)=−21i∑nj∑n(λiλjyiyj)xiTxj+i∑nλi
即是:
min
λ
i
L
(
λ
i
)
=
1
2
∑
i
n
∑
j
n
(
λ
i
λ
j
y
i
y
j
)
x
i
T
x
j
−
∑
i
n
λ
i
s
.
t
.
λ
i
≥
0
∑
i
n
λ
i
y
i
=
0
\begin{aligned} &\min_{\lambda_i} \mathcal L(\lambda_i)=\frac{1}{2}\sum_i^n\sum_j^n(\lambda_i\lambda_jy_iy_j)x_i^Tx_j-\sum_i^n\lambda_i\\ &s.t.\quad \lambda_i\ge0\\ &\sum_i^n\lambda_iy_i =0 \end{aligned}
λiminL(λi)=21i∑nj∑n(λiλjyiyj)xiTxj−i∑nλis.t.λi≥0i∑nλiyi=0
假设求得:
λ
∗
=
(
λ
1
,
λ
2
,
⋯
,
λ
n
)
\lambda^*=(\lambda_1,\lambda_2,\cdots,\lambda_n)
λ∗=(λ1,λ2,⋯,λn),那么只需要带入
∑
i
n
λ
i
y
i
x
i
\sum_i^n\lambda_iy_ix_i
∑inλiyixi,即可解得
w
∗
w^*
w∗,又通过
w
∗
T
x
i
+
b
=
1
,
λ
i
≥
0
w{^*}^Tx_i+b=1,\lambda_i\ge0
w∗Txi+b=1,λi≥0,即可解得
b
∗
b^*
b∗。此时
x
i
x_i
xi也被称为支持向量(support vector)。
软间隔最大化
在实际的数据集中,总会存在着噪点(noise),或者离群点(outlier)。考虑下图:
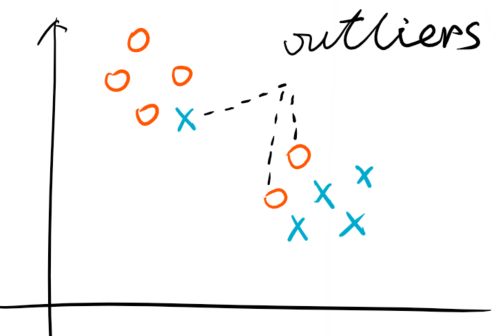
那么显然,这个已经无法简单用一个超平面来解决问题了。面对这样的情况,我们有三个方法,原始数据层面,我们可以做数据清洗,或者特征工程。二是利用非线性模型(实际上,在这里用非线性模型过于大材小用,或者不合理。因为这显然是一个线性可分,但是存在噪点的数据集)。第三个办法就是,允许我们SVM模型可以进行误分类。即是说上文的:
y
i
(
w
T
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
⋯
,
n
y_i(w^Tx_i+b)\ge1,i=1,2,\cdots,n
yi(wTxi+b)≥1,i=1,2,⋯,n
可以对部分样本不成立。那么问题就在于如果巧妙的将允许犯错加入到SVM模型中。
合页损失函数(hinge loss function)
由于有些样本会导致:
y
i
(
w
T
x
i
+
b
)
<
1
,
i
=
1
,
2
,
⋯
,
n
y_i(w^Tx_i+b)<1,i=1,2,\cdots,n
yi(wTxi+b)<1,i=1,2,⋯,n
很自然的,我们就希望能纠正这一点,若犯错,需纠正数值为:
Δ
=
1
−
y
i
(
w
T
x
i
+
b
)
,
g
i
v
e
n
y
i
(
w
T
x
i
+
b
)
<
1
\Delta=1-y_i(w^Tx_i+b),\ given \ y_i(w^Tx_i+b)<1
Δ=1−yi(wTxi+b), given yi(wTxi+b)<1
从而使得:
y
i
(
w
T
x
i
+
b
)
+
Δ
≥
1
,
g
i
v
e
n
y
i
(
w
T
x
i
+
b
)
<
1
y_i(w^Tx_i+b)+\Delta\ge1,\ given\ y_i(w^Tx_i+b)<1
yi(wTxi+b)+Δ≥1, given yi(wTxi+b)<1
下面给出合页损失函数的定义:
ξ
i
=
m
a
x
{
0
,
1
−
y
i
(
w
T
x
i
+
b
)
}
\xi_i=max\{0,1-y_i(w^Tx_i+b)\}
ξi=max{0,1−yi(wTxi+b)}
同样使得:
y
i
(
w
T
x
i
+
b
)
+
ξ
i
≥
1
y_i(w^Tx_i+b)+\xi_i\ge1
yi(wTxi+b)+ξi≥1
如果我们令:
y
i
(
w
T
x
i
+
b
)
=
z
y_i(w^Tx_i+b)=z
yi(wTxi+b)=z,那么
f
(
z
)
f(z)
f(z)的图像则为:
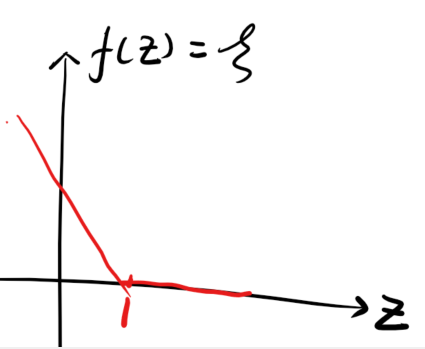
从硬到软(原始问题)
由上文知,硬间隔的原始问题:
min
w
,
b
1
2
w
T
w
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
⋯
,
n
\min_{w,b}\frac{1}{2}w^Tw\\ s.t.\quad y_i(w^Tx_i+b)\ge1,i=1,2,\cdots,n
w,bmin21wTws.t.yi(wTxi+b)≥1,i=1,2,⋯,n
又由上文的分析,限制条件变更为:
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
−
ξ
i
,
i
=
1
,
2
,
⋯
,
n
s.t.\quad y_i(w^Tx_i+b)\ge1-\xi_i,\ i=1,2,\cdots,n
s.t.yi(wTxi+b)≥1−ξi, i=1,2,⋯,n
但是只这样子做,会存在一个问题,因为我们对
ξ
i
\xi_i
ξi所作出的犯错修正没有作出任何限制。因而,模型为了使得最小间隔尽量的大,而进行任意的犯错修正,最终导致误分类点很多。因此,我们需要对
ξ
i
\xi_i
ξi的修正行为,进行限制。那么很自然的,考虑到,修正行为的强度和修正值成正比,因而,我们将
ξ
i
\xi_i
ξi的值作为损失的角色,加入到
min
w
,
b
1
2
w
T
w
\min_{w,b}\frac{1}{2}w^Tw
minw,b21wTw中,最终得到软间隔的原始问题:
min
w
,
b
1
2
w
T
w
+
C
∑
i
n
ξ
i
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
−
ξ
i
,
i
=
1
,
2
,
⋯
,
n
\min_{w,b}\frac{1}{2}w^Tw+C\sum_i^n\xi_i\\ s.t.\quad y_i(w^Tx_i+b)\ge1-\xi_i,\ i=1,2,\cdots,n
w,bmin21wTw+Ci∑nξis.t.yi(wTxi+b)≥1−ξi, i=1,2,⋯,n
最终,软间隔成为一方面使得
min
1
2
w
T
w
\min\frac{1}{2}w^Tw
min21wTw,即最小间隔最大,一方面使得
min
C
∑
i
n
ξ
i
\min C\sum_i^n\xi_i
minC∑inξi,即误分类点尽量少。其中
C
C
C是调和两者的系数。
软间隔的对偶问题
其与硬间隔的对偶问题相似,就略了。
线性不可分SVM
核方法
Driving Example
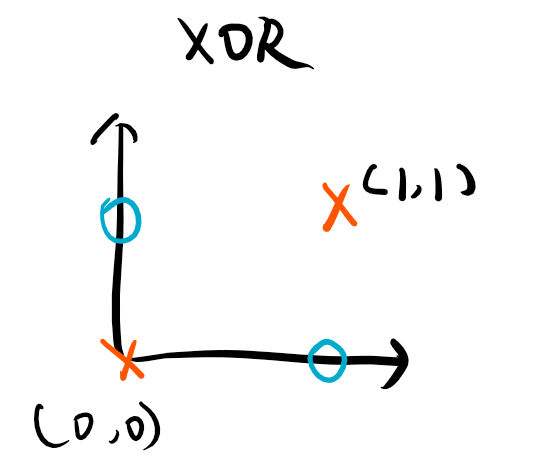
考虑下面两个例子:
1.同维度映射
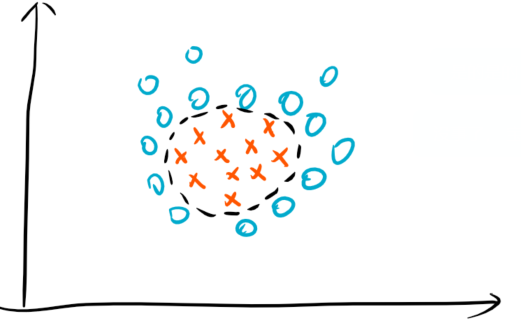
很直观的可以看出来,这对于线性SVM来说,是“十二月天找杨梅”。因此,我们只能通过某种非线性映射将样本点映射到新的空间,比如下图:
上面的映射相当于,从输入空间
x
=
(
x
1
,
x
2
)
\mathbf x=(x_1,x_2)
x=(x1,x2)通过
ϕ
(
x
)
\phi(\mathbf x)
ϕ(x)映射到了
x
=
(
x
1
2
,
x
2
2
)
\mathbf x=(x_1^2,x_2^2)
x=(x12,x22)
2.高维映射
考虑使用如下的映射:
ϕ
(
x
)
=
(
x
1
,
x
2
,
(
x
1
−
x
2
)
2
)
\phi(\mathbf x)=(x_1,x_2,(x_1-x_2)^2)
ϕ(x)=(x1,x2,(x1−x2)2),得到:
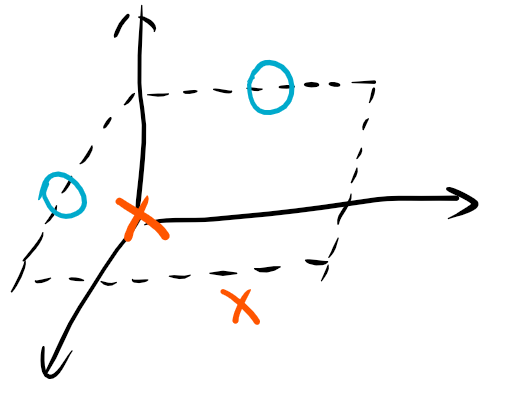
从而变得线性可分。
核技巧
由上文可知,我们求解SVM的时候最后一步化简有:
min
λ
i
L
(
λ
i
)
=
1
2
∑
i
n
∑
j
n
(
λ
i
λ
j
y
i
y
j
)
x
i
T
x
j
−
∑
i
n
λ
i
\min_{\lambda_i} \mathcal L(\lambda_i)=\frac{1}{2}\sum_i^n\sum_j^n(\lambda_i\lambda_jy_iy_j)x_i^Tx_j-\sum_i^n\lambda_i
λiminL(λi)=21i∑nj∑n(λiλjyiyj)xiTxj−i∑nλi
注意到其中有,
x
i
T
x
j
x_i^Tx_j
xiTxj,这是我们需要计算的,那么如果我们进行了映射,式子就变为
ϕ
(
x
i
)
⋅
ϕ
(
x
j
)
,
⋅
为
内
积
\phi(x_i)\cdot \phi(x_j),\cdot为内积
ϕ(xi)⋅ϕ(xj),⋅为内积。这时计算它就变为,先找到映射
ϕ
(
x
)
\phi(x)
ϕ(x),再计算内积。那么我们是否可以找到一个函数一步达到目的呢,核技巧需要用到的核函数就诞生了。
核函数
定义
设
X
\mathcal X
X为输入空间,
H
\mathcal H
H为特征空间,并且有映射:
ϕ
(
x
)
:
X
−
>
H
\phi(x):\mathcal X->\mathcal H
ϕ(x):X−>H
而核函数满足有:
K
(
x
,
z
)
=
ϕ
(
x
)
⋅
ϕ
(
z
)
x
,
z
∈
X
K(x,z)=\phi(x)\cdot\phi(z) \qquad x,z\in\mathcal X
K(x,z)=ϕ(x)⋅ϕ(z)x,z∈X
因而上式
min
λ
i
L
(
λ
i
)
=
1
2
∑
i
n
∑
j
n
(
λ
i
λ
j
y
i
y
j
)
x
i
T
x
j
−
∑
i
n
λ
i
\min_{\lambda_i} \mathcal L(\lambda_i)=\frac{1}{2}\sum_i^n\sum_j^n(\lambda_i\lambda_jy_iy_j)x_i^Tx_j-\sum_i^n\lambda_i
λiminL(λi)=21i∑nj∑n(λiλjyiyj)xiTxj−i∑nλi
则变为
min
λ
i
L
(
λ
i
)
=
1
2
∑
i
n
∑
j
n
(
λ
i
λ
j
y
i
y
j
)
K
(
x
,
z
)
−
∑
i
n
λ
i
\min_{\lambda_i} \mathcal L(\lambda_i)=\frac{1}{2}\sum_i^n\sum_j^n(\lambda_i\lambda_jy_iy_j)K(x,z)-\sum_i^n\lambda_i
λiminL(λi)=21i∑nj∑n(λiλjyiyj)K(x,z)−i∑nλi
正定核
首先明确一点说,没有特殊说明,那么核函数指的就是正定核函数。
那么满足什么条件的函数才能被称为核函数
K
(
x
,
z
)
K(x,z)
K(x,z)呢。
希尔伯特(Hilbert space)空间
如果函数
K
(
x
,
z
)
K(x,z)
K(x,z)是定义在
X
×
X
\mathcal X \times \mathcal X
X×X上的对称函数,并且对任意的
x
1
,
x
2
⋯
,
x
m
∈
X
,
K
(
x
,
z
)
x_1,x_2\cdots,x_m\in \mathcal X,K(x,z)
x1,x2⋯,xm∈X,K(x,z)关于
x
1
,
x
2
,
⋯
,
x
m
x_1,x_2,\cdots,x_m
x1,x2,⋯,xm的Gram矩阵是半正定的。那么,我们可以根据函数
K
(
x
,
z
)
K(x,z)
K(x,z)构成一个具有内积性质的希尔伯特空间。
空间构造过程略。
正定核的充要条件
必要性:
即已知为正定核,证明其为对称函数,且Gram矩阵为半正定。
对称性:
由正定核定义可得:
K
(
x
,
z
)
=
ϕ
(
x
)
⋅
ϕ
(
z
)
K(x,z)=\phi(x)\cdot\phi(z)
K(x,z)=ϕ(x)⋅ϕ(z)
由内积对称性:
K
(
x
,
z
)
=
ϕ
(
z
)
⋅
ϕ
(
x
)
=
K
(
z
,
x
)
K(x,z)=\phi(z)\cdot\phi(x)=K(z,x)
K(x,z)=ϕ(z)⋅ϕ(x)=K(z,x)
因此,其为对称函数。
半正定性:
对于任意
x
1
,
x
2
,
⋯
,
x
m
x_1,x_2,\cdots,x_m
x1,x2,⋯,xm,构造
K
(
x
,
z
)
K(x,z)
K(x,z)关于
x
1
,
x
2
,
⋯
,
x
m
x_1,x_2,\cdots,x_m
x1,x2,⋯,xm的Gram矩阵:
[
K
i
j
]
m
×
m
=
[
K
(
x
i
,
x
j
)
]
m
×
m
[K_{ij}]_{m\times m}=[K(x_i,x_j)]_{m\times m}
[Kij]m×m=[K(xi,xj)]m×m
若要证明其半正定性,那么由定义只需证明:
对
于
任
意
α
∈
R
m
,
α
T
[
K
i
j
]
m
×
m
α
≥
0
对于任意\alpha\in \mathbb R^m,\alpha^T[K_{ij}]_{m\times m}\alpha\ge 0
对于任意α∈Rm,αT[Kij]m×mα≥0
展开有:
[
α
1
α
2
⋯
α
m
]
[
K
11
K
12
⋯
K
1
m
K
21
K
22
⋯
K
2
m
⋮
⋮
⋮
⋮
K
m
1
K
m
2
⋯
K
m
m
]
[
α
1
α
2
⋮
α
m
]
=
∑
i
m
∑
j
m
α
i
α
j
K
i
j
=
∑
i
m
∑
j
m
α
i
α
j
ϕ
(
x
i
)
T
ϕ
(
x
j
)
=
∑
i
m
α
i
ϕ
(
x
i
)
T
∑
j
m
α
j
ϕ
(
x
j
)
=
<
∑
i
m
α
i
ϕ
(
x
i
)
,
∑
j
m
α
j
ϕ
(
x
j
)
>
=
∣
∣
∑
i
m
α
i
ϕ
(
x
i
)
∣
∣
2
≥
0
\begin{aligned}&\left [\begin{matrix} \alpha_1 \alpha_2 \cdots \alpha_m \end{matrix}\right] \left [\begin{matrix} K_{11}&K_{12}&\cdots &K_{1m}\\K_{21}&K_{22}&\cdots &K_{2m}\\ \vdots &\vdots &\vdots &\vdots \\K_{m1}&K_{m2}&\cdots&K_{mm} \end{matrix}\right] \left [\begin{matrix} \alpha_1 \\ \alpha_2 \\ \vdots \\\alpha_m \end{matrix}\right]\\ &=\sum_i^m\sum_j^m\alpha_i\alpha_jK_{ij}\\ &=\sum_i^m\sum_j^m\alpha_i\alpha_j\phi(x_i)^T\phi(x_j)\\ &=\sum_i^m\alpha_i\phi(x_i)^T\sum_j^m\alpha_j\phi(x_j)\\ &=<\sum_i^m\alpha_i\phi(x_i),\sum_j^m\alpha_j\phi(x_j)>\\ &=\vert\vert\sum_i^m\alpha_i\phi(x_i)\vert\vert^2\ge0\\ \end{aligned}
[α1α2⋯αm]⎣⎢⎢⎢⎡K11K21⋮Km1K12K22⋮Km2⋯⋯⋮⋯K1mK2m⋮Kmm⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡α1α2⋮αm⎦⎥⎥⎥⎤=i∑mj∑mαiαjKij=i∑mj∑mαiαjϕ(xi)Tϕ(xj)=i∑mαiϕ(xi)Tj∑mαjϕ(xj)=<i∑mαiϕ(xi),j∑mαjϕ(xj)>=∣∣i∑mαiϕ(xi)∣∣2≥0
因此是核函数则满足:1.对称性 2.Gram矩阵为半正定
充要性(待续)
















 2907
2907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









