







转载自http://blog.csdn.net/wxg694175346/article/list/1
前面十章爬虫笔记陆陆续续记录了一些简单的Python爬虫知识,
用来解决简单的贴吧下载,绩点运算自然不在话下。
不过要想批量下载大量的内容,比如知乎的所有的问答,那便显得游刃不有余了点。
于是乎,爬虫框架Scrapy就这样出场了!
Scrapy = Scrach+Python,Scrach这个单词是抓取的意思,
暂且可以叫它:小抓抓吧。
小抓抓的官网地址:点我点我。
那么下面来简单的演示一下小抓抓Scrapy的安装流程。
具体流程参照:官网教程
友情提醒:一定要按照Python的版本下载,要不然安装的时候会提醒找不到Python。建议大家安装32位是因为有些版本的必备软件64位不好找。
1.安装Python(建议32位)
建议安装Python2.7.x,3.x貌似还不支持。
安装完了记得配置环境,将python目录和python目录下的Scripts目录添加到系统环境变量的Path里。
在cmd中输入python如果出现版本信息说明配置完毕。
2.安装lxml
lxml是一种使用 Python 编写的库,可以迅速、灵活地处理 XML。点击这里选择对应的Python版本安装。
3.安装setuptools
用来安装egg文件,点击这里下载python2.7的对应版本的setuptools。
4.安装zope.interface
可以使用第三步下载的setuptools来安装egg文件,现在也有exe版本,点击这里下载。
5.安装Twisted
Twisted是用Python实现的基于事件驱动的网络引擎框架,点击这里下载。
6.安装pyOpenSSL
pyOpenSSL是Python的OpenSSL接口,点击这里下载。
7.安装win32py
提供win32api,点击这里下载
8.安装Scrapy
终于到了激动人心的时候了!安装了那么多小部件之后终于轮到主角登场。
直接在cmd中输入easy_install scrapy回车即可。
9.检查安装
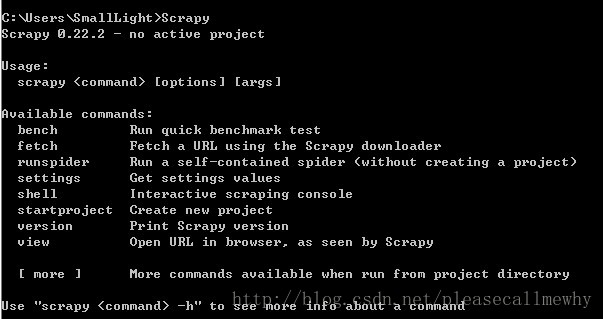
打开一个cmd窗口,在任意位置执行scrapy命令,得到下列页面,表示环境配置成功。















 63万+
63万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









