









一 python
1.各函数
1.1python库的安装与导入
#pip install os
#pip install matplotlib
#pip install seaborn
#pip install scikit-learn
#pip install scipy
#修 改 工 作 目 录
import os
os.getcwd () # 查看当前工作环境
os.chdir( 'F :\my course\database ') # 修改工作环境
os.getcwd ()
#模 块 价 值
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns #统 计 绘 图
from sklearn.preprocessing import StandardScaler
from scipy.stats import norm
from scipy import stats #统 计
from sklearn.impute import Simple Imputer #导 入 模 块1.2python读入和检查数据
# 读 入 分 析 数 据
2 df= pd.read_csv("customer1997 .csv")
3
4 # 检 查 数 据、 行 数、 列 数、 列 属 性 和 类 型
5 df.shape # 行 数 和 列 出
6 df.info () # 每 个 属 性 的 行 数 和 类 型
7 df.columns # 属 性 列 名 称
8 # 查 看 数 据 集 前5 行
9 df.head (5)1.3数据属性的描述性分析
1 # 分 别 查 看RFM 的 描 述 统 计 量
2 # 方 法1 使 用describe() 输 出 数 值 属 性 的 行 数、 均 值、 标 准 差、 最 小 值、 Q1 ,Q2 ,Q3 ,最 大 值 3 df.describe ()
4 # 方 法2 使 用describe() 输 出 数 值 属 性 的 行 数、 均 值、 标 准 差、 最 小 值、 Q1 ,Q2 ,Q3 ,最 大 值 5 df[ 'Rec en cy '].describe () # 注 意 大 小 写 是 敏 感 的
6 # 方 法3 使 用 函 数 对 某 列 进 行 描 述 统 计
7 print( '对 客 户 的 到 店 次 数 进 行 描 述 统 计 ')
8 print( '最 小 值 是 ' , df[ 'Frequency '].min ())
9 print( '均 值 是 ' , df[ 'Frequency '].mean ())
10 print( ' 中 位 数 是 ' , df[ 'Frequency '].median ())
11 print( '第25 百 分 位 数 ' , df[ 'Frequency '].quantile(q=0.25))
12 print( '第75 百 分 位 数 ' , df[ 'Frequency '].quantile(q=0.75))
13 print( '最 大 值 是 ' , df[ 'Frequency '].max ())
14 print( '极 差 是 ' , df[ 'Frequency '].max ()-df[ 'Frequency '].min ())
15 print( '方 差 和 标 准 差 ' , df[ 'Frequency '].var(),df[ 'Frequency '].std())
16 print( '变 异 系 数 ' , df[ 'Frequency '].std()/df[ 'Frequency '].mean ())
17 print( '偏 度 和 峰 度 ' , df[ 'Frequency '].skew (),df[ 'Frequency '].kurt os is ())
18
19 # 数 值 型 属 性 统 计 分 布 图
20 # 绘 制 分 布 图 确 保 import seaborn as sns 被 执 行
21 df[ 'Monetary ']
22 sns.distplot(df[ 'Monetary '])
23 # 绘 制 盒 型 图
24 sns.boxplot(df[ 'Monetary '])
25 # 绘 制 核 密 度 图
26 sns.kdeplot(df[ 'Monetary '], shade=True , bw=.5, color="olive")1.4分类属性的描述性分析
1 # 分 类 数 据 的 频 数 统 计
2 # 按 会 员 卡 等 级 统 计 人 数、 RFM 的 均 值、 描 述 统 计 量
3 # 设 置 数 据 对 象 的 分 组 属性 ,并 创 建 新 的 数 据 对 象
4 member card_summary=df.groupby( 'member_card ')
5 member card_summary [ 'customer_id '].count ()
6 member card_summary [ 'Rec en cy '].mean ()
7 member card_summary .mean ()
8 member card_summary [ 'Frequency '].describe ()
9 member card_summary [ 'Monetary '].describe ()1.5两个分类属性的交叉统计分析
1 # 两 个 个 分 类 属 性 的 交 叉 统 计 分 析
2 # 按 会 员 卡 和 性 别 的 输 出 交 叉 表
3 pd.crosstab(df[ 'member_card '], df[ 'gender '])
4 #对 交 叉 结 果 进 行 归 一 化
5 pd.crosstab(df[ 'member_card '], df[ 'gender '],normalize=True)
6 #在 最 右 边 增 加 一 个 汇 总 列
7 pd.crosstab(df[ 'member_card '], df[ 'gender '],normalize=True ,margins=True)
8 # 对 每 列 进 行 归 一 化
9 pd.crosstab(df[ 'member_card '], df[ 'gender '],normalize= 'columns ')
10 # 绘 制 频 数 图/条 形 图
11 # 对 比 每 个 会 员 等 级 的 不 同 性 别 的 客 户 数 量
12 sns.countplot(y="member_card" ,hue= 'gender ' ,data=df)
13 # 两 个 分 类 属 性 增 加1个 数 值 属 性 的 盒 形 图
14 sns.boxplot(x="member_card" ,y="Frequency" ,hue="gender" ,data=df)1.6两个数值属性的相关分析
# 两 个 数 值 属 性
2 # 绘 制 相 关 矩 阵 和 热 力 图
3 # 输 出 数 值 型 属 性 的 两 两 相 关 系 数 表
4 df.corr ()
5 #绘 制 热 力 图
6 corr=df.corr ()
7 corr=(corr)
8 sns.heatmap(corr , xticklabels=corr.columns.values , yticklabels=corr.columns.values) 9 #绘 制2个 变 量 散 点 图 (scatterplot)
10 sns.scatterplot(x="Frequency" , y="Monetary" , data=df)
11 #绘 制 带 回 归 线 的 散 点 图 (lmplot)
12 sns.lmplot(x="Frequency" , y="Monetary" , data=df)
13 #在 散 点 图 上 增 加 一 个 分 类 属 性
14 sns.lmplot(x="Frequency" , y="Monetary" ,hue="gender" , data=df)
15 # 集 群 散 点 图(swarmplot)
16 sns.swarmplot(x=df[ 'gender '], y=df[ 'Monetary '])
17 sns.swarmplot(x=df[ 'gender '], y=df[ 'Frequency '])
18
19
20 #简 单 散 点 图 的 绘 图 语 法: sns .scatterplot( x=X对 应 变量 , y=Y对 应 变 量)
21 #分 组 散 点 图 的 绘 图 语 法: sns .scatterplot( x=X对 应 变量 , y=Y对 应 变量 , hue=分 组 依 据 的 类 别 变 量) 22 # 带 回 归 线 的 散 点 图 的 绘 图 语 法: sns .regplot( x=X对 应 变量 , y=Y对 应 变 量)
23 # 带 回 归 线 的 分 组 散 点 图 的 绘 图 语 法: sns .lmplot(x=X变 量 列名 , y=Y变 量 列名 , hue=分 组 依 据 的 类 别 变 量 列 名 , data=数 据 表)
24 #集 群 散 点 图(swarmplot) 的 绘 图 语 法: sns .swarmplot( x=X对 应 的 类 别 变量 , y=Y对 应 变 量)1.7分类属性和数值属性的方差分析
1 # 1个 分 类 属 性 和1个 数 值 属 性
2 # 绘 制 盒 型 图
3 sns.boxplot(x=df[ 'member_card '],y=df[ 'Monetary '],data=df)
4 sns.boxplot(x=df[ 'gender '],y=df[ 'Monetary '],data=df)
5 # 单 因 素 方 差 分 析: 比 较 均 值 的 差 异 性
6 from scipy import stats
7 from statsmodels.formula.api import ol s
8 from statsmodels.stats.anova import anova_lm
9 from statsmodels.stats.multi comp import pairwise_tukeyhsd
10
11 df2=pd.con cat ([df[ 'gender '],df[ 'Monetary ']],axis=1)
12 anova_monetary= anova_lm(ol s( 'Monetary~C (gender) ' ,data=df2[[ 'gender ' , 'Monetary ']]).fit()) 13 print(anova_monetary)
14 ## 在0.05 的 显 著 水 平 下, 不 同 性 别 客 户 的 消 费 金 额 是 有 差 异 的
15 # 绘 制 不 同 组 的 核 密 度 图
16 # 使 用loc()取 出 不 同 组 的 数 据
17 p1=sns.kdeplot(df.loc[(df[ 'gender ']== 'M '), 'Rec en cy '], shade=True , color="r" ,label= 'M ') 18 p2=sns.kdeplot(df.loc[(df[ 'gender ']== 'F '), 'Rec en cy '], shade=True , color="b" ,label= 'F ') 19 plt.show ()
20 ##绘 制 叠 加 图 时 多 行 一 起 执 行1.8时间序列数据
1 # 带 有 时 间 属 性
2 # 读 入 分 析 数 据
3 import numpy a s np
4 import pandas a s pd
5 from datetime import datetime
6 import matplotlib.pylab a s plt
7 # 读 取 数 据, pd .read_csv 默 认 生 成DataFrame对 象, 需 将 其 转 换 成Series对 象
8 df = pd.read_csv( 'daily sales1997 .csv ' , encoding= 'utf-8 ' , index_col= 'date ')
9 df.info ()
10 df.index
11 df.index = pd.to_datetime(df.index) # 将 字 符 串 索 引 转 换 成 时 间 索 引
12 ts = df[ 'sales '] # 生 成pd .Series对 象
13 # 查 看 数 据 格 式
14 ts.head ()
15 ts.head ().index
16 #查 看 某 日 的 值 既 可 以 使 用 字 符 串 作 为 索 引, 又 可 以 直 接 使 用 时 间 对 象 作 为 索 引
17 ts[ '1997-01-05 ']
18 ts[datetime (1997 ,10 ,1)]
19 #切 片 操 作
20 ts[ '1997-5 ' : '1997-6 ']
21 #绘 制 时 间 序 列 图
22 ts.plot(fig size=(12 ,8))2.例子
(1)
hotel.csv

def hotel_data():
df = pd.read_csv('hotel.csv')
# print(df)
return df
def get_shape(): # 获取行列值
shape = hotel_data().shape
print(shape)
def get_info():
info = hotel_data().info
print(info)
def get_column():
column = hotel_data().columns
print(column)
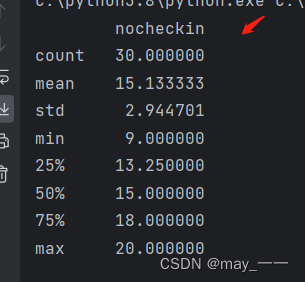
def get_describe(): # 描述数据:数量,均值,最小值,最大值,25%,50%,75%
describe = hotel_data().describe()
print(describe)
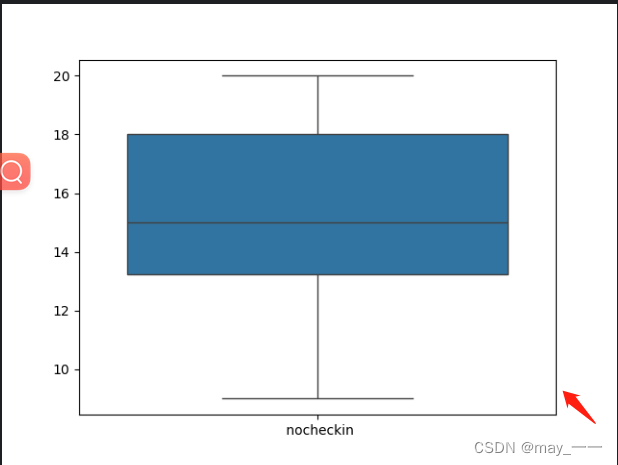
def get_box(): # 盒型图
data = hotel_data()
sns.boxplot(data)
# sns.boxplot(data['nocheckin'], vert=False, showfliers=True)
plt.show()
def get_dis(): # 柱形图
data = hotel_data()
sns.displot(data)
plt.show()
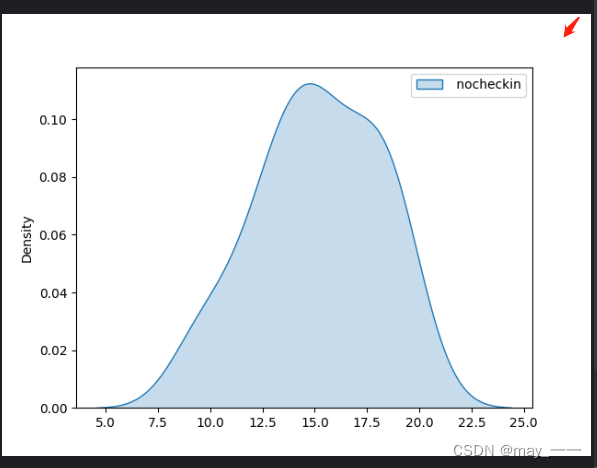
def get_kdef(): # 分布图
data = hotel_data()
# sns.kdeplot(data, shade=True, bw=.5, color="olive")
sns.kdeplot(data, fill=True, bw_method=.5, color="olive")
plt.show()hotel_data()结果:
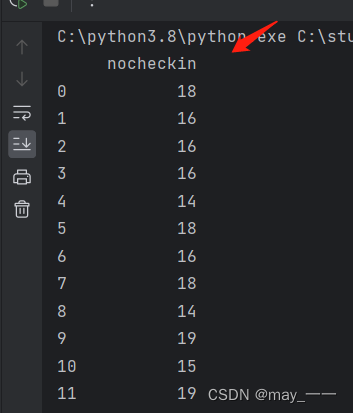
get_describe()结果:
get_column()结果:
get_box()结果:
get_dis()结果:

get_kdef()结果:
(2)
customer1997.csv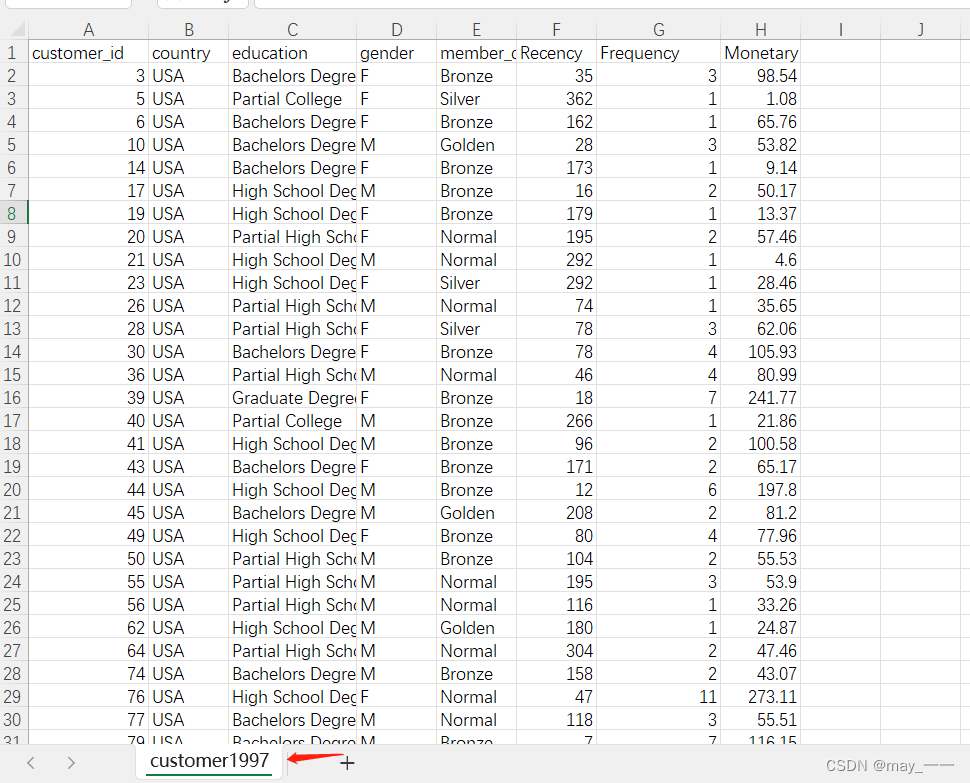
def get_summary(): # 分组频数统计
data = customer_data()
member_summary = data.groupby('member_card')
data1 = data.groupby('member_card').count()
print(data1)
data2 = member_summary['customer_id'].count() # 单个变量 每类会员卡人数
print(data2)
data3 = member_summary['Monetary'].mean() # 双变量 会员卡 消费金额 每类会员卡平均
print(data3)
data4 = member_summary['Monetary'].describe()
print(data4)结果

二 execl
1.调出“数据分析”按钮
文件--选项--加载项--转到--分析工具库
查看
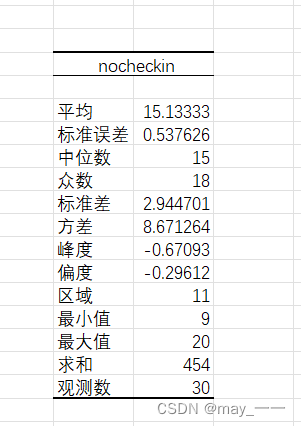
 2.数据分析使用
2.数据分析使用
选中数据,点击“数据分析”,选中“描述分析”


结果如下:















 2387
2387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









