









一、环境说明
1.机器:三台虚拟机
2.Linux版本
cat /proc/versionLinux version 3.19.0-25-generic (buildd@lgw01-20) (gcc version 4.8.2 (Ubuntu 4.8.2-19ubuntu1) ) #26~14.04.1-Ubuntu SMP
3.jdk版本
java -versionjava version “1.8.0_65”
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
4.集群节点:一个masters,两个slave
二、准备工作
1.安装jdk:http://blog.csdn.net/u014706843/article/details/50442329
2.ssh免密码验证:http://blog.csdn.net/u014706843/article/details/50442533
3 建立hadoop运行帐号
即为hadoop集群专门设置一个用户组及用户,这部分比较简单,参考示例如下:
sudo groupadd hadoop //设置hadoop用户组
sudo useradd –s /bin/bash –d /home/xx–m xx–g hadoop –G root//添加一个xx用户,此用户属于hadoop用户组,且具有root权限。
sudo passwd xx//设置用户xx登录密码
su xx//切换到zhm用户中
上述3个虚机结点均需要进行以上步骤来完成hadoop运行帐号的建立。
三、安装Hadoop
1、下载Hadoop安装包
下载地址:http://hadoop.apache.org/releases.html
选择二进制安装包(binary),可以减少出错的概率。
2、解压 ,输入一下指令
tar -xzvf hadoop-2.6.3.tar.gz 3、修改文件名字
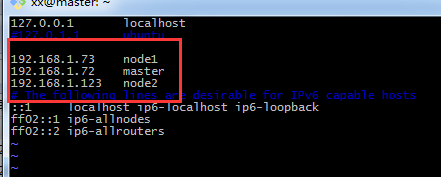
mv hadoop-2.6.3 hadoop4、配置hosts文件
vi /etc/hosts大家可以参考自己的IP地址以及相应的主机名完成配置,我的如下图
5、修改配置文件
主要涉及的配置文件有7个:都在/hadoop/etc/hadoop文件夹下,可以用gedit命令对其进行编辑。如果没有安装gedit的话,可以使用vi命令,我使用的是vi命令。
xx@master:~$ sudo cd hadoop/etc/hadoop5.1、配置 hadoop-env.sh文件–>修改JAVA_HOME
xx@master:~$ sudo vi hadoop-env.sh#The java implementation to use.
export JAVA_HOME=/home/xx/user/java/jdk1.8.0_65
5.2、配置 yarn-env.sh 文件–>>修改JAVA_HOME
xx@master:~$ sudo vi yarn-env.sh文件里面添加内容
# some Java parameters
export JAVA_HOME=/home/xx/user/java/jdk1.8.0_65
5.3、配置slaves文件–>>增加slave节点
xx@master:~$ vi slave添加主机名,我的slave节点名称是node1,node2
5.4配置 core-site.xml文件–>>增加hadoop核心配置(hdfs文件端口是9000、file:/home/xx/hadoop-/tmp/)
xx@master:~$ vi core-site.xml文件内容如下:
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<final>true</final>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/xx/hadoop/tmp</value>
<description>A base for other temporary directories</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
-- INSERT -- 5.5配置 hdfs-site.xml 文件–>>增加hdfs配置信息(namenode、datanode端口和目录位置)
xx@master:~$ vi hdfs-site.xml文件内容如下:
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
<final>true<final>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/xx/hadoop/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<final>true</final>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration> 5.6配置 mapred-site.xml 文件–>>增加mapreduce配置(使用yarn框架、jobhistory使用地址以及web地址)
xx@master:~$ vi mapred-site.xml文件内容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobhistory.adress</name>
<value>master:10020</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<final>true</final>
</property>
</configuration>
5.7配置 yarn-site.xml 文件–>>增加yarn功能
xx@master:~$ vi yarn-site.xml文件内容如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<final>true</final>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
<final>true</final>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
5.8将配置好的hadoop文件copy到另一台slave机器上
xx@master:~$ scp -r ./hadoop node1:~到节点node1和node2上面查看,看到Hadoop文件目录已经复制过去,这样slave节点node1,node2已经安装好了Hadoop-2.6.3。
四、验证
1、格式化namenode:
xx@master:~/hadoop$ ./bin/hdfs namenode -format出现以下信息就是格式化成功:
INFO common.Storage: Storage directory /home/xx/hadoop/name has been successfully formatted.2、启动hdfs:
xx@master:~/hadoop$ ./sbin/start-dfs.sh启动内容如下:
Starting namenodes on [master]
master: starting namenode, logging to /home/xx/hadoop/logs/hadoop-xx-namenode-master.out
node1: starting datanode, logging to /home/xx/hadoop/logs/hadoop-xx-datanode-node1.out
node2: starting datanode, logging to /home/xx/hadoop/logs/hadoop-xx-datanode-node2.out
Starting secondary namenodes [master]
master: starting secondarynamenode, logging to /home/xx/hadoop/logs/hadoop-xx-secondarynamenode-master.out
xx@master:~/hadoop/sbin$ jps
4042 Jps
3612 NameNode
3871 SecondaryNameNode在slave节点node1,node2上面会有datanode的进程,如果没有就是没有启动成功。有时候会手误,导致配置文件少了节点或者少了‘/’等符号,master节点就会报错,修改完master节点的文件之后,要记得slave节点上面也要修改,不然你在master节点上看不到详细错误信息。
3、停止hdfs
xx@master:~/hadoop/sbin$ ./stop-dfs.sh停止内容如下:
Stopping namenodes on [master]
master: stopping namenode
node2: stopping datanode
node1: stopping datanode
Stopping secondary namenodes [master]
master: stopping secondarynamenode
xx@master:~/hadoop/sbin$ jps
6632 Jps4、启动yarn:
xx@master:~/hadoop/sbin$ ./start-yarn.sh启动内容如下:
starting yarn daemons
starting resourcemanager, logging to /home/xx/hadoop/logs/yarn-xx-resourcemanager-master.out
node2: starting nodemanager, logging to /home/xx/hadoop/logs/yarn-xx-nodemanager-node2.out
node1: starting nodemanager, logging to /home/xx/hadoop/logs/yarn-xx-nodemanager-node1.out
xx@master:~/hadoop/sbin$ jps
7412 Jps
7135 ResourceManager
5、停止yarn:
xx@master:~/hadoop/sbin$ ./stop-yarn.sh停止过程内容如下:
stopping yarn daemons
stopping resourcemanager
node2: stopping nodemanager
node1: stopping nodemanager
no proxyserver to stop
xx@master:~/hadoop/sbin$ jps
7532 Jps
xx@master:~/hadoop/sbin$
6、查看集群状态:
xx@master:~/hadoop/bin$ ./hdfs dfsadmin -reportConfigured Capacity: 245987983360 (229.09 GB)
Present Capacity: 229095870464 (213.36 GB)
DFS Remaining: 229095813120 (213.36 GB)
DFS Used: 57344 (56 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.1.73:50010 (node1)
Hostname: node1
Decommission Status : Normal
Configured Capacity: 194334412800 (180.99 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 12184432640 (11.35 GB)
DFS Remaining: 182149951488 (169.64 GB)
DFS Used%: 0.00%
DFS Remaining%: 93.73%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Jan 03 22:15:18 EST 2016
Name: 192.168.1.123:50010 (node2)
Hostname: node2
Decommission Status : Normal
Configured Capacity: 51653570560 (48.11 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 4707680256 (4.38 GB)
DFS Remaining: 46945861632 (43.72 GB)
DFS Used%: 0.00%
DFS Remaining%: 90.89%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Jan 03 22:15:17 EST 2016
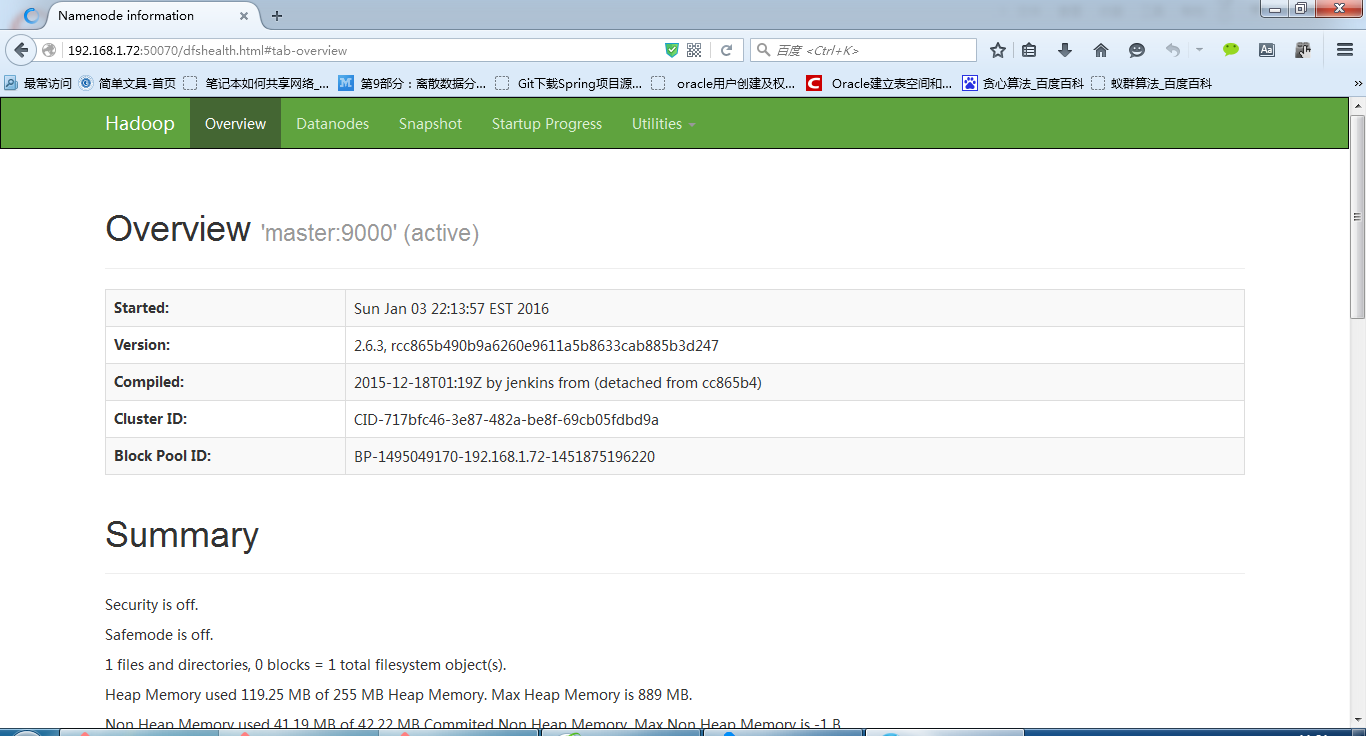
7、查看hdfs:http://192.168.1.72:50070/
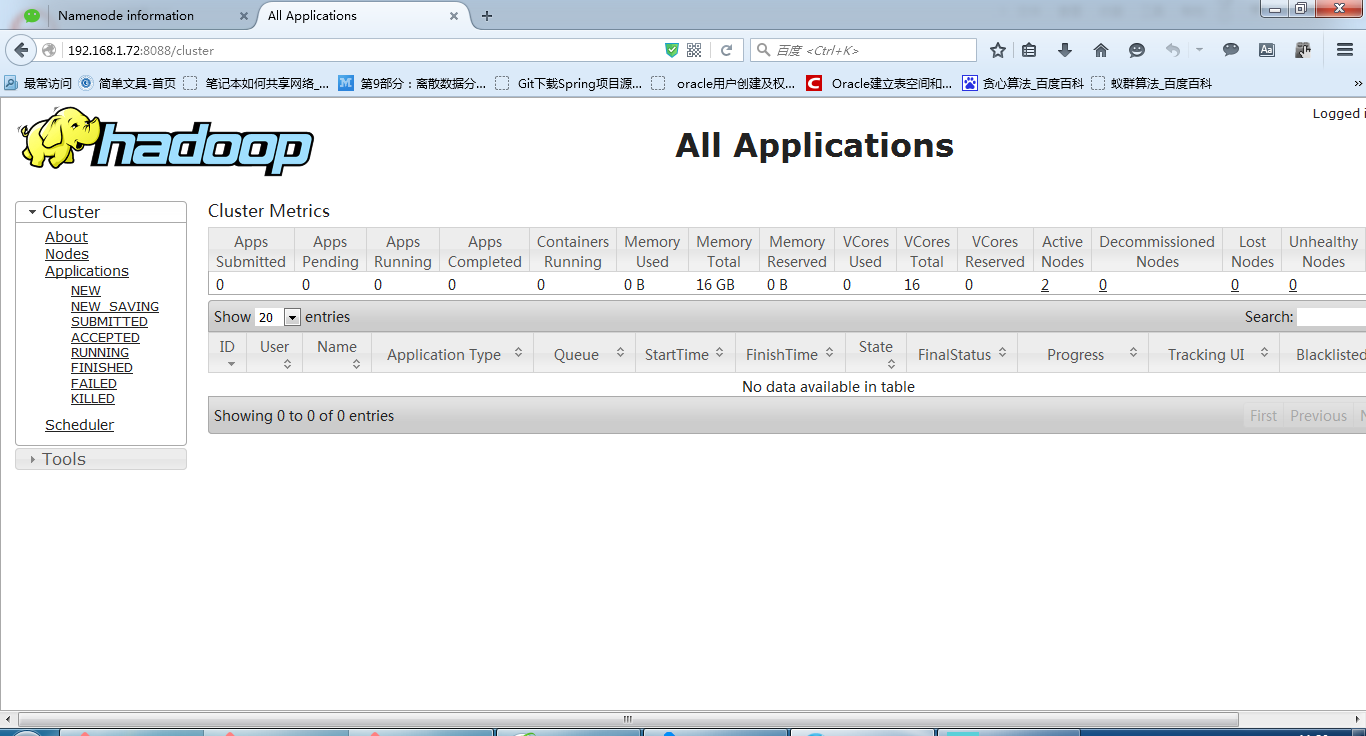
8、查看RM:http://192.168.1.72:8088/
9、运行wordcount程序
9.1创建 input目录:
xx@master:~/hadoop$ mkdir input9.2、在input创建f1、f2并写内容
xx@master:~/hadoop$ touch input/f1
xx@master:~/hadoop$ vi ./input/f1
Hello world ,
xx@master:~/hadoop$ touch input/f2
xx@master:~/hadoop$ vi ./input/f2
Hello Hadoop .
xx@master:~/hadoop$9.3、在hdfs创建/tmp/input目录
xx@master:~/hadoop$ ./bin/hadoop fs -mkdir /tmp
xx@master:~/hadoop$ ./bin/hadoop fs -mkdir /tmp/input
9.4、将f1、f2文件copy到hdfs /tmp/input目录
xx@master:~/hadoop$ ./bin/hadoop fs -put input/ /tmp
9.5、查看hdfs上是否有f1、f2文件
xx@master:~/hadoop$ ./bin/hadoop fs -ls /tmp/input
Found 2 items
-rw-r--r-- 2 xx supergroup 14 2016-01-03 22:29/tmp/input/f1
-rw-r--r-- 2 xx supergroup 15 2016-01-03 22:29/tmp/input/f29.6、执行wordcount程序
注意空格
xx@master:~/hadoop$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.3.jar wordcount /tmp/input /output运行内容如下:
16/01/03 22:35:03 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.1.72:8032
16/01/03 22:35:04 INFO input.FileInputFormat: Total input paths to process : 2
16/01/03 22:35:04 INFO mapreduce.JobSubmitter: number of splits:2
16/01/03 22:35:05 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1451877255267_0001
16/01/03 22:35:05 INFO impl.YarnClientImpl: Submitted application application_1451877255267_0001
16/01/03 22:35:05 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1451877255267_0001/
16/01/03 22:35:05 INFO mapreduce.Job: Running job: job_1451877255267_0001
16/01/03 22:35:16 INFO mapreduce.Job: Job job_1451877255267_0001 running in uber mode : false
16/01/03 22:35:16 INFO mapreduce.Job: map 0% reduce 0%
16/01/03 22:35:25 INFO mapreduce.Job: map 100% reduce 0%
16/01/03 22:35:33 INFO mapreduce.Job: map 100% reduce 100%
16/01/03 22:35:33 INFO mapreduce.Job: Job job_1451877255267_0001 completed successfully9.7、查看执行出来的文件名
xx@master:~/hadoop$ ./bin/hadoop fs -ls /output/
Found 2 items
-rw-r--r-- 2 xx supergroup 0 2016-01-03 22:35 /output/_SUCCESS
-rw-r--r-- 2 xx supergroup 33 2016-01-03 22:35 /output/part-r-00000
9.8、查看结果
xx@master:~/hadoop$ ./bin/hadoop fs -cat /output/part-r-00000 , 1
. 1
Hadoop 1
Hello 2
world 1
至此,搭建结束!欢迎收藏















 4638
4638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









