







1. 编写UDF函数
有时候hive提供的官方函数不能满足业务需求,这里hive还提供了更加灵活的解决方案:UDF(User Defined Function用户自定义函数)。下面简要介绍一下如何编写并使用用户自定义函数
需求:在查询分区字段“nation”的时候,希望把它变成对应的内容。如:查询“China”,输出的是“zhongguo”,以此类推
a) 继承org.apache.hadoop.hive.ql.exec.UDF类,实现evaluate() 方法
evaluate()函数在父类中是没有的
package cn.itcast.hive.udf;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class NationUDF extends UDF{
public static Map<String, String> nationMap = new HashMap<String, String>();
static{
nationMap.put("China", "zhongguo");
nationMap.put("Japan", "xiaoriben");
nationMap.put("USA", "meidi");
}
Text t = new Text();
//自定义函数的名称必须叫evaluate!
public Text evaluate(Text nation){
String nation_e = nation.toString();
String name = nationMap.get(nation_e);
if(name ==null){
name = "huoxingren";
}
t.set(name);
return t;
}
}b) 自定义函数调用过程:
1. 添加 jar 包(在hive命令行里面执行)
hive> add jar /root/NationUDF.jar;
2. 创建临时函数
hive> create temporary function getNation as 'cn.itcast.hive.udf.NationUDF';
临时函数的缺点是在下次启动hive集群时自动失效。当然,我们也可以直接创建永久函数,这样就不用担心失效的问题了,问题在于创建过程比较复杂,需要修改源码。
3. 调用
hive> select id, name,size, getNation(nation) from beauties order by size desc;
结果:
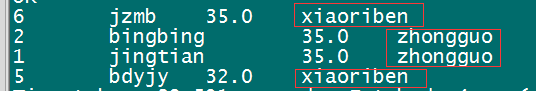
结果中产生了我们在NationUDF.java 文件中所转换的字符,说明UDF成功被hive启用。
4. 将查询结果保存到HDFS中
这种方式也就是通过SQL将查询结果插入到新建的表中
hive> create table result
row format delimited fields terminated by '\t'
as select * from beauty order by id desc;
创建的表文件是最终保存在HDFS上的















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









