







1.Hive表的基本数据类型
tinyint, smallint, int, bigint, boolean, float, double,
string, binary, timestamp, decimal, char, varchar, date
2.Hive表的集合类型
Array:ARRAY类型是由一系列相同数据类型的元素组成, 这些元素可以通过下标来访问,例 : array[1]
Map:MAP包.合key->value键值对,可以通过key来访问元素,例如: map[‘key’]
Struct:可以包含不同数据类型的元素,这些元素可以通过“点语法”的方式获得,例如: struct.key1
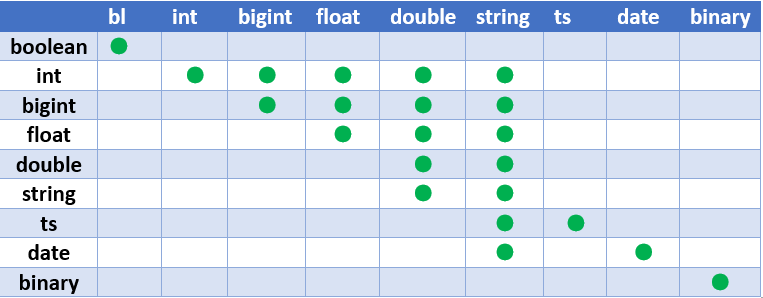
3.Hive的数据类型转换
4.Hive的底层文件存储格式
- #文件格式
- textfile
- sequencefile
- rcfile
- #扩展接口
- 默认的文件读取方式
- 自定义inputformat
- 自定义serde
4.1 RCFile的生成过程
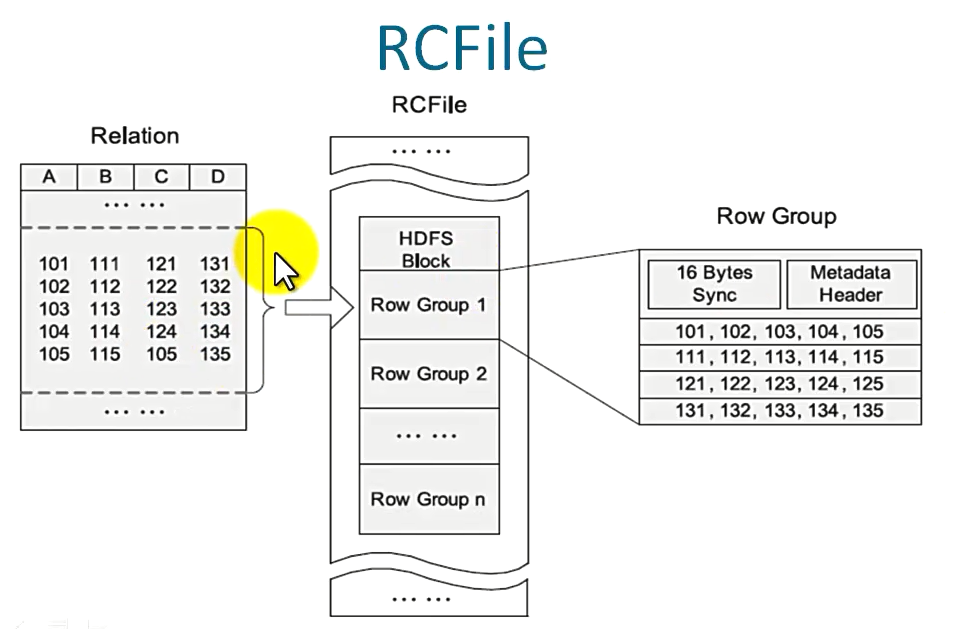
有的时候查询只需要查出某一个列,而表中有可能包含成百上千的字段,所以使用RCFile可以把列 以行的形式存储,提高查询效率,节省时间。
4.2 Hive的基本使用——表
官方定义创建表的方式:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name data_type[COMMENT col_comment],…)]
[PARTITIONED BY (col_name data_type[COMMENT col-comment],…)]
[CLUSTERED BY (col_name1,col_name2,…)[SORTED BY(col_name [ASC|DESC],…)]
INTO num_buckets BUCKETS] [ROW FORMAT row_format][STORED AS file_format] |
STORED BY ‘storage.handler.class.name’[WITH SERDEPROPERTIES(…)] ]
[LOCATION hdfs_path] [TBLPROPERTIES(property_name=property_value,…)] [AS select_statement]
创建表举例:
CREATE [EXTERNAL] TABLE employees( name string, subordinates
array, duductions map
4.2.1 查看表的描述信息
如果在定义表的时候,定义了 comment 注释字段
则在命令行中可以通过:
DESC Table_Name;
查看表的描述信息

如果想显示更详细的内容,输入:
DESC FORMATEED Table_Name;
查看表的详细描述
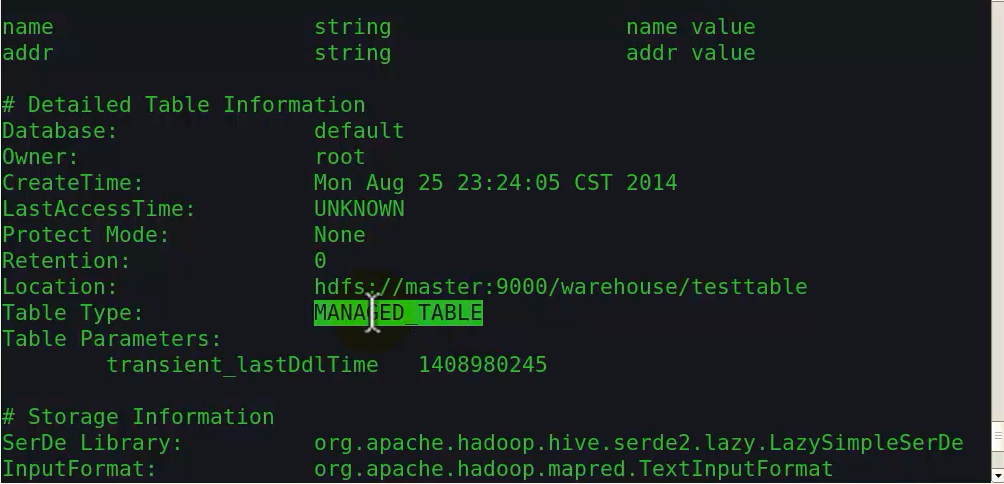
MANAGED_TABLE:内部表
显示建表语句
show create table Table_Name;
4.2.2 将文件中的内容加载进表中
LOAD DATA LOCAL INPATH ‘/…’ OVERWRITE INTO TABLE Table_Name;
OVERWRITE : 以覆盖方式加载上传linux本地文件,如果没有这个字段,则是默认以追加方式存储,会将后面的同名文件改为File_Name_copy_n(n:第几份拷贝,从1开始)
注意:如果指定字段分隔符,必须以指定的字段分隔符严格存放数据,否则必然出错!
4.2.3 删除内部表
drop table Table_Name;
内部表被删掉,数据对应的文件将会被删掉
如果创建表的时候指定了LOCATION ,那么在hdfs上的文件也同样将会被删掉
4.2.4 删除外部表
删除外部表的时候,只删除外部表对应的元数据信息,数据所对应的文件将不会被删除。
4.2.5 复杂格式表的创建

第8行collection items terminated by ‘,’
第10行map keys terminated by ‘:’ 指定map的键值对是以“:”分隔的
源数据格式如下:

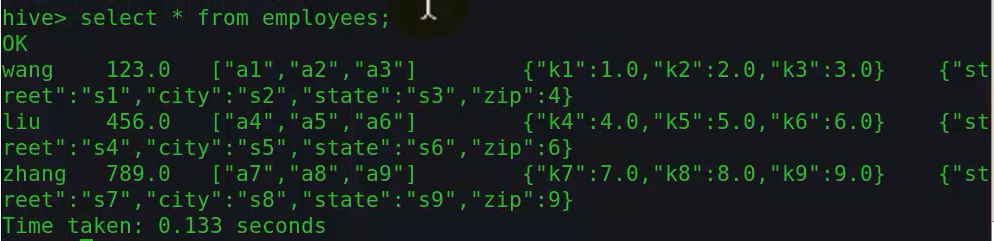
查询数组中的数据
命令格式:select suborinates[n] from employees;
注:n从0开始
查询map中的数据
命令格式:select ductions[“k2”] from employees;
注:加载表数据的时候没有让key一致,需要修改
查询结构体中的数据
命令格式:select address.city from employees;
以下查询是不走map-reduce过程的:
select * from tablename [limit n];
注:外部表 内部表 是一样不走map-reduce的
4.2.6 Hive建表的其他方式
1. 由一个表创建另一个表结构相同的表
create table test3 like test2;
2. 从其他表查询创建
create table test4 as select name.addr from test5;
5. Hive 不同文件类型的读取对比
stored textfile
-直接查看hdfs
- hadoop fs -text
stored as sequencefile
- hadoop fs -text
stored as rcfile
-hive -service refilecat path
stored as inputformat ‘class’
-outformat ‘class’
5.1 创建一张以textfile格式存储的表
create table test_txt(name string,val string) stored as textfile;
表的描述信息:

5.2创建一张以sequencefile格式存储的表
create table test_seq(name string,val string) stored as sequencefile;
表的部分描述信息:

5.3 创建一种以RCfile格式存储的表
create table test_rc(name string,val string) stored as rcfile;
表的描述信息:

5.4 创建一种以自定义文件格式存储的表
create table test_rc(name string,val string) stored as inputformat ‘class’;
注:必须添加jar包之后才能进行后续操作(创建表、查询等)
6. Hive 使用SerDe(Serialize Deserialize)

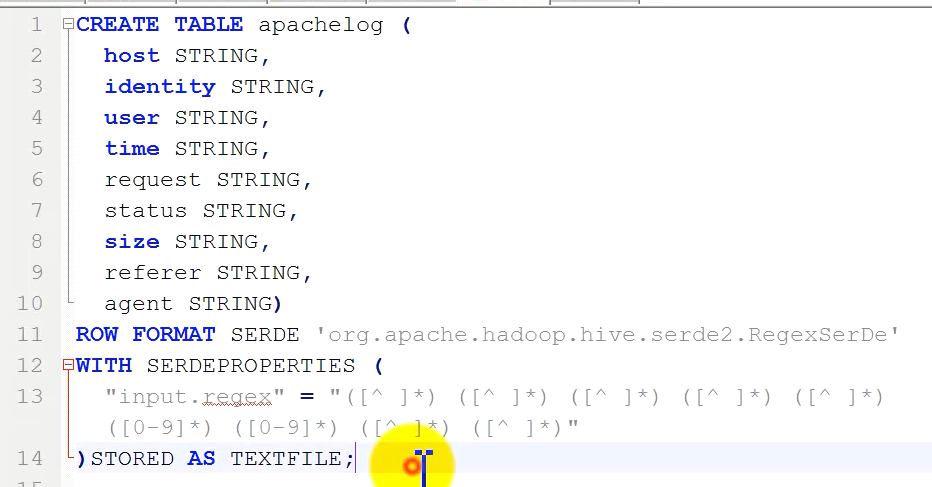
7. Hive 分区表
7.1 分区:
在Hive Select 查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作
分区表指的是在创建表时指定 partition 的分区空间
7.2 分区语法
create table tablename(
name string
)
Partitioned by(key type,…)
创建分区表示例:
create table employees (
name string,
salary float,
subdinates array<string>,
deductions map<string,float>,
address struct<street:string,city:string,state:string,zip:int>
)
partitioned by(dt string,type string)
row format delimited fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n'
stored as textfile

注:分区下可以再继续创建分区,类似于文件的子目录
7.3 增加分区
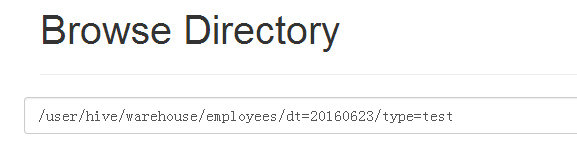
给employees表下添加分区20160623/test
hive> alter table employees add if not exists partition(dt=’20160623’,type=’test’);

通过浏览器查看,同样发现目录下多了这些文件夹
8. hive分桶(Bucket)
8.1 分桶
- 对于每一个表(table)或者分区,hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分
- Hive是针对某一列进行分桶
- Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中
好处:
- 获得更高的查询处理效率
- 使取样(sampling)更高效
创建分桶表
创建分桶之前需要先作如下设置:
set hive.enforce.bucketing=true;然后再创建表:
create table bucketed_user (
id int,
name string
)
clustered by(id) sorted by(name) into 4 buckets
row format delimited fields terminated by ‘\t’ stored as textfile;
向表中插入数据:
insert overwrite table bucketed_user select name,addr from test_txt;
通过浏览器可以查看到
hdfs:/user/warehouse/bucketed_user/目录下多了4个文件

说明分桶成功
对该表数据的查找是通过计算哈希值实现的,计算该字段的哈希值,直接定位到与该字段哈希值相等的桶中,加快了查询效率
8.2 分区与分桶的比较
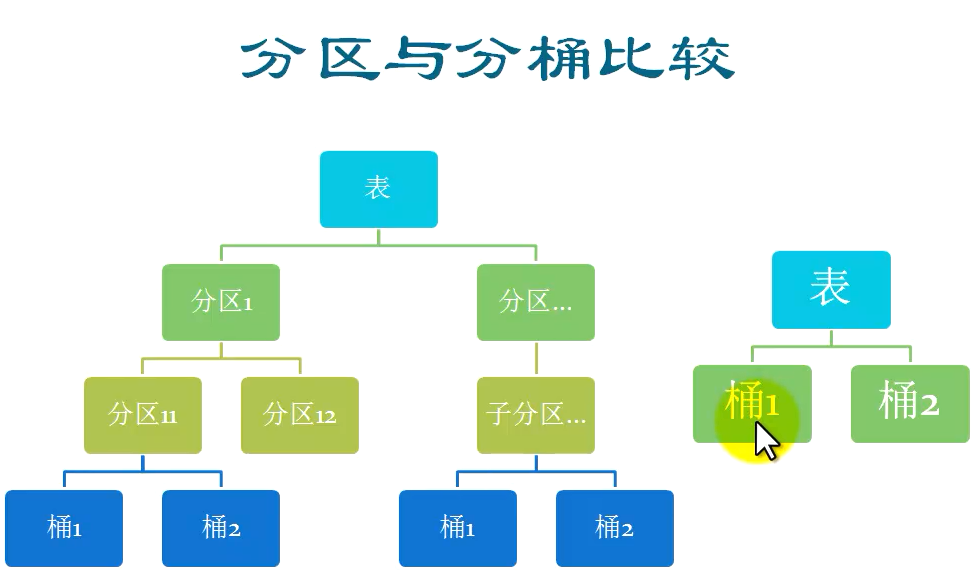
注:分区的层级必须是一致的
(例如左图中分桶的层级在左右两个子树中都是第4层)
分区表中的底层可以使用分桶实现,桶是存储类型的最低形式,分桶表不能再分区














 116
116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









