







参考文章:http://www.linuxidc.com/Linux/2016-02/128729.htm
http://blog.csdn.net/uq_jin/article/details/51513307
基本参考上面2篇文章就可以吧环境搭好,我也只是拾人牙慧罢了….
前置环境准:jdk安装 (下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html,这个是jdk8的)
hadoop集群搭建步骤:
1:准备好3台机器(或者虚拟机,虚拟机第一次安装可以考虑先装好一台,然后复制2份即可)
2:ssh免密码登陆设置(参考文章http://blog.csdn.net/universe_hao/article/details/52296811)
3:下载hadoop安装包,下载地址:http://hadoop.apache.org/releases.html
4:创建hadoop运行账号 (非必须)
5:配置hosts文件
6:配置namenode,修改site文件,配置hadoop-env.sh文件
7:配置slaves文件
8:启动、查看
9:idea下搭建hadoop开发环境
参考文章:http://blog.csdn.net/uq_jin/article/details/522351
http://blog.csdn.net/youxia918/article/details/46726187
一:机器准备(我的配置:win10,VMware中装了3台centos7),
虚拟机安装可以参考:https://jingyan.baidu.com/article/a3aad71aa180e7b1fa009676.html
镜像地址:http://pan.baidu.com/s/1o87h5hg 密码:za8k
二:ssh免密码登陆可以参考http://blog.csdn.net/universe_hao/article/details/52296811 因为我自己的之前就配置过了这边就贴了,而且我也是参考别人的博客配置的。
三:下载解压 hadoop 到某个目录(例如 /usr/loacl/hadoop)
四:账号创建:
即为hadoop集群专门设置一个用户组及用户,这部分比较简单,参考示例如下:
groupadd hadoop //设置hadoop用户组
useradd –s /bin/bash –d /home/hadoop –m hadoop –g hadoop –G admin
//添加一个hadoop 用户,此用户属于hadoop用户组,且具有admin权限。
passwd xxxxx//设置用户hadoop登录密码
su hadoop //切换到hadoop
五:配置hosts
配置hosts文件的作用:用于确定每个结点的IP地址,方便后续master结点能快速查到并访问各个结点。
配置hosts需要确定每个结点的IP地址,可以使用ifconfig命令进行查看当前虚机结点的IP地址,例如: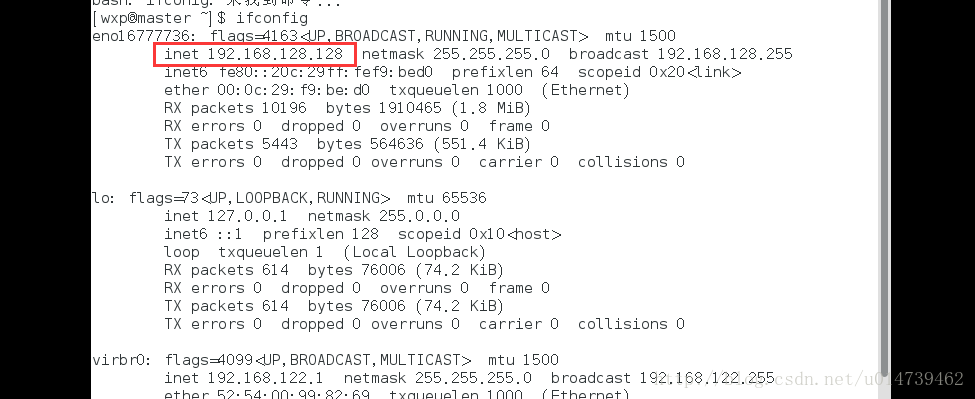
如果IP地址不对,可以通过ifconfig命令更改结点的物理IP地址:ifconfig eth1 1912.168.xxx.xxx
(这里可以使用VMware吧虚拟机的Ip设置死,这样比较方便)
hosts配置示例:
192.168.128.128 master
192.168.128.132 study_node_1
192.168.128.130 study_node_2
六:修改环境变量以及hadoop的配置文件了,即各种site文件,文件存放在/hadoop/etc下(这个不同版本的hadoop目录好像不一样,我这边是2.7.3是在etc下)。
修改 /etc/profile
export HADOOP_HOME=/xxx/xxx/hadoop-2.7.3
export PATH=
PATH:
HADOOP_HOME/bin
source /etc/profile
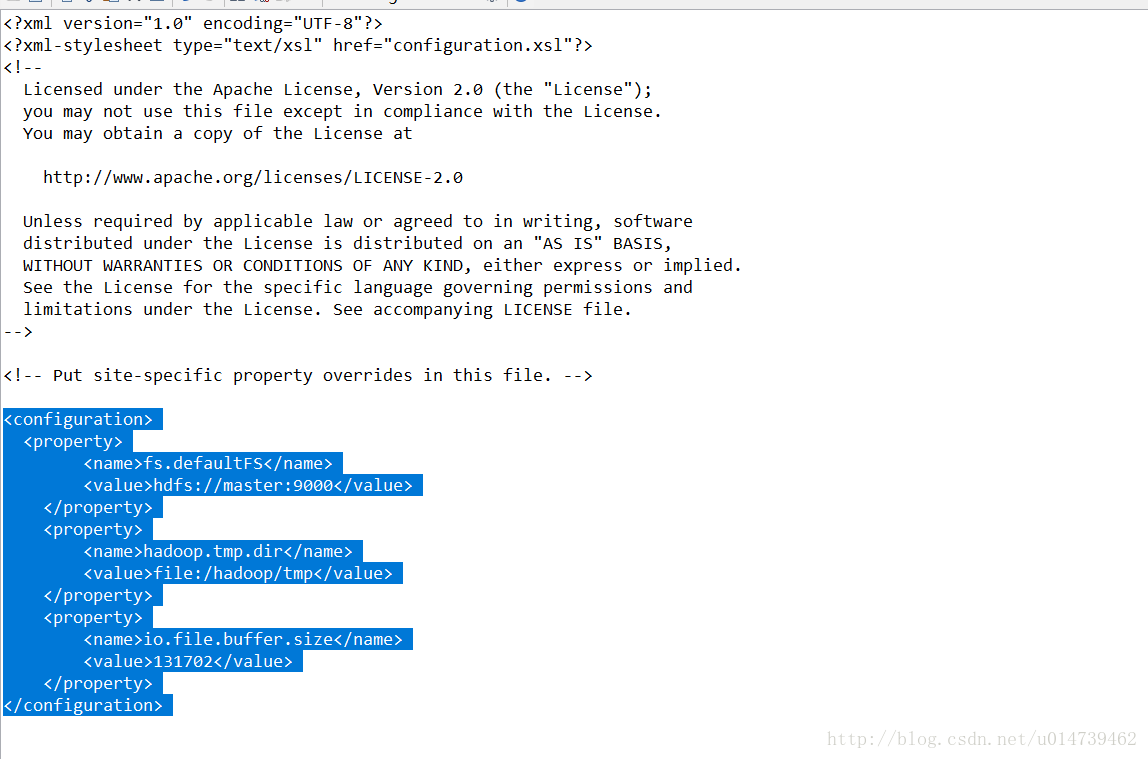
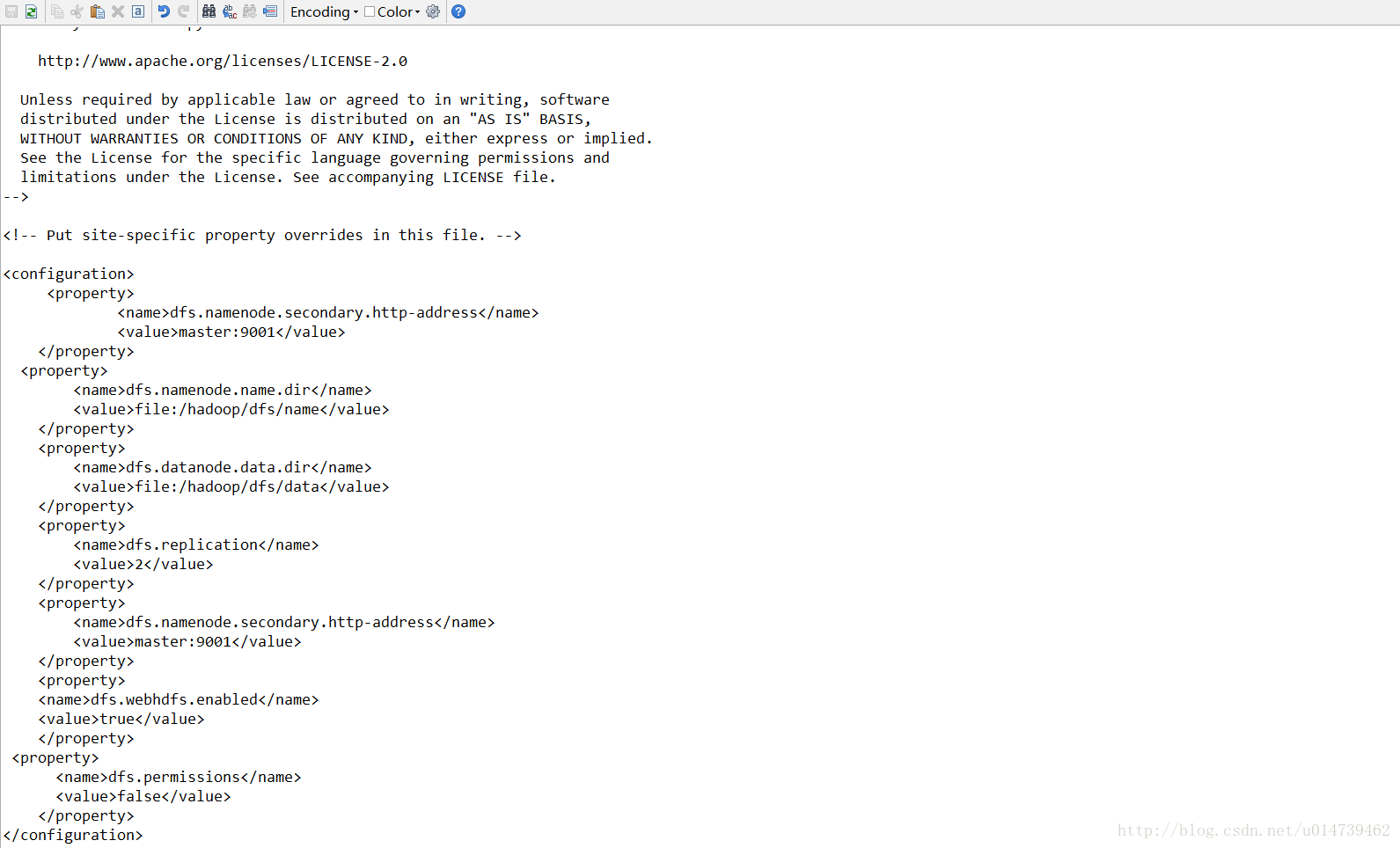
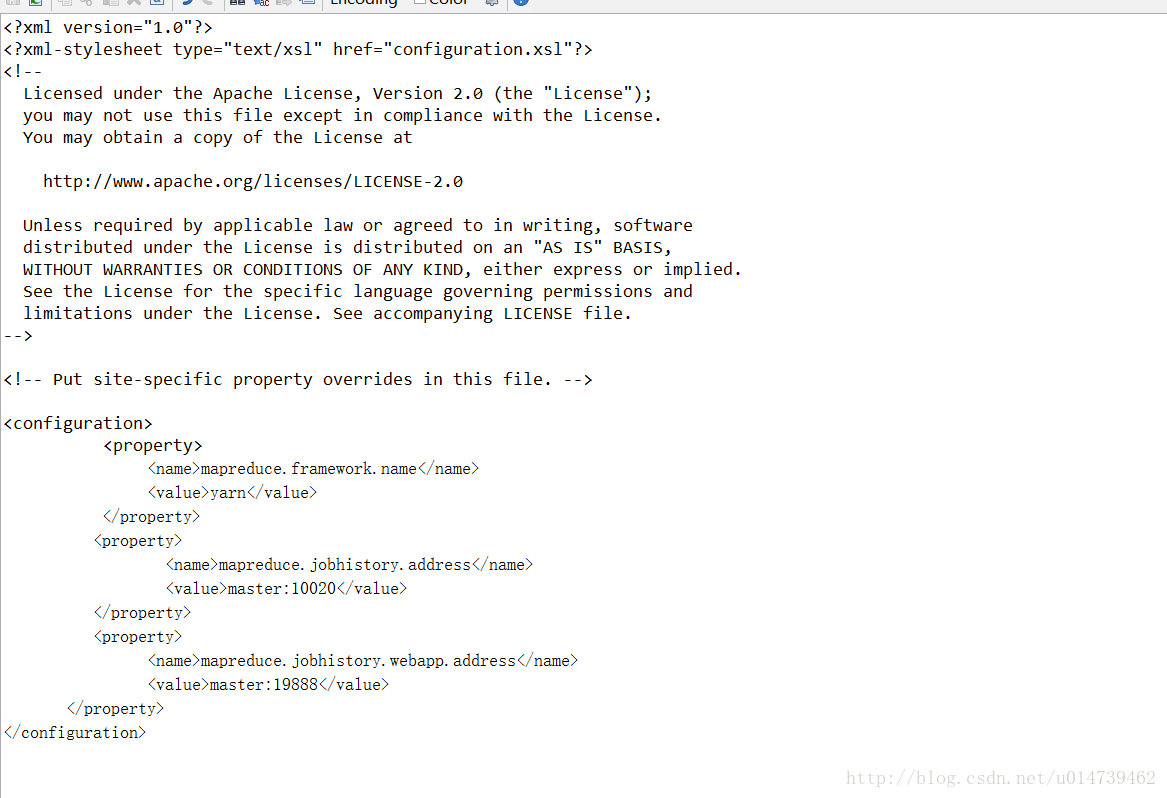
配置core-site.xml、hdfs-site.xml、mapred-site.xml这三个文件。
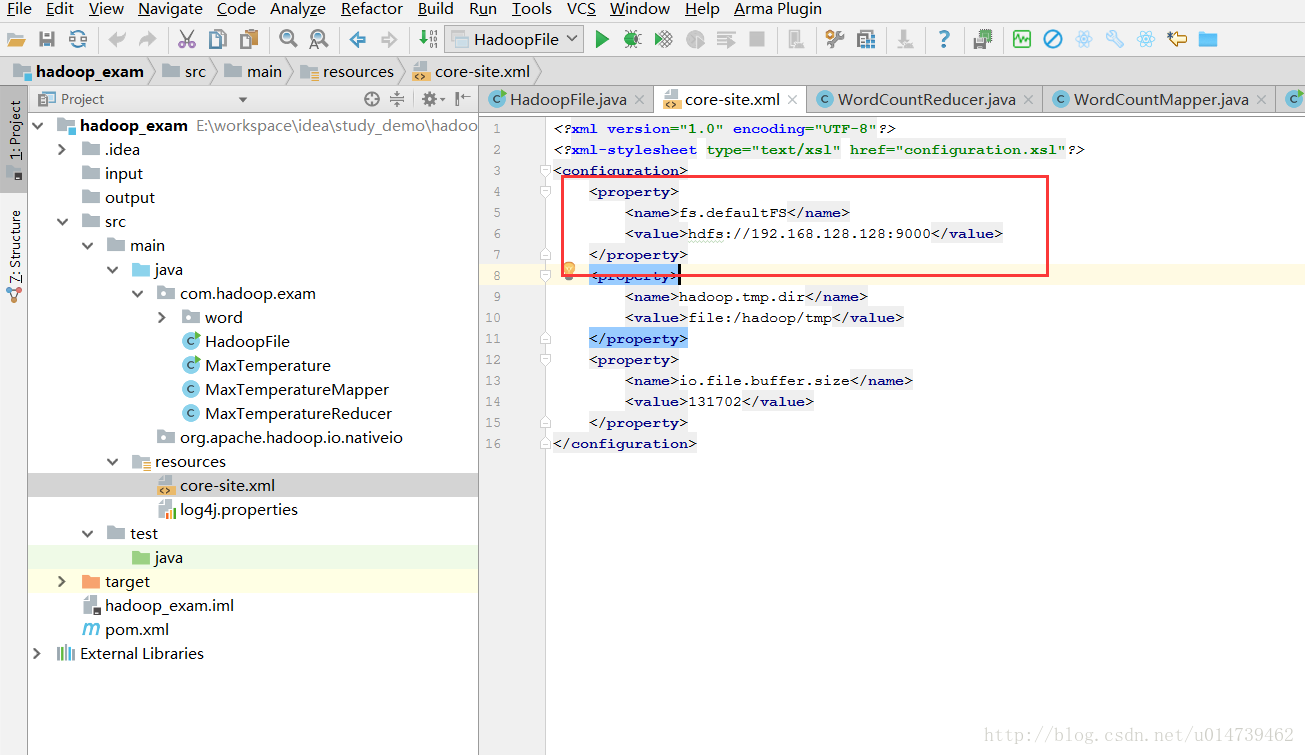
core-site.xml:
hdfs-site.xml:
mapred-site.xml
更多配置参考相关文档或者文章
配置hadoop-env.sh文件
这个需要根据实际情况来配置。
配置jdk目录
export JAVA_HOME=/usr/java/jdk1.8.0_101
更多配置参考相关文档或者文章
七:配置slaves文件
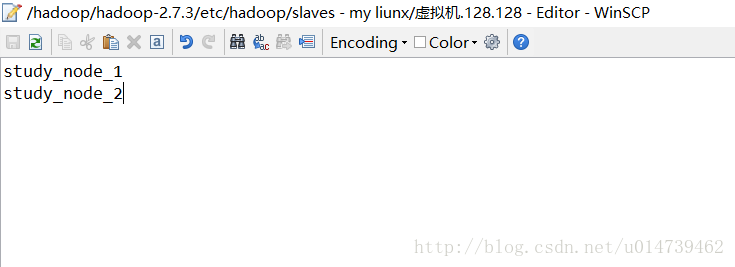
八:启动
第一次启动得格式化
./bin/hdfs namenode -format
启动dfs: ./sbin/start-dfs.sh
启动yarn: ./sbin/start-yarn.sh
查看:master

查看 slave
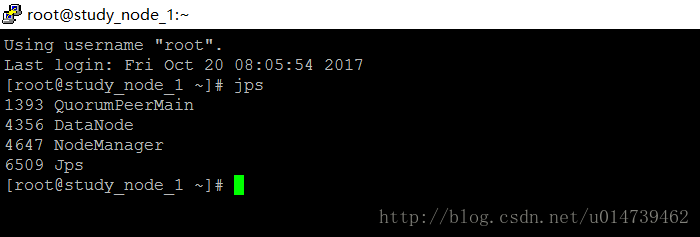
查看yarn: :http://192.168.128.128:8088/cluster

状态查看:http://192.168.128.128:9001/status.html

查看hdfs
http://192.168.128.128:50070/dfshealth.html#tab-overview

至此集群环境搭建完成
10:开发环境搭建(idea,可以直接参考该文章:http://blog.csdn.net/uq_jin/article/details/52235121)
1:下载hadoop 解压到本地目录,并配置环境变量
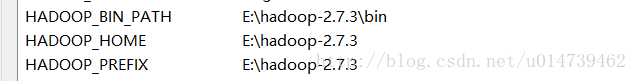
2:创建maven工程,加入hadoop原来
3:配置core-site.xml
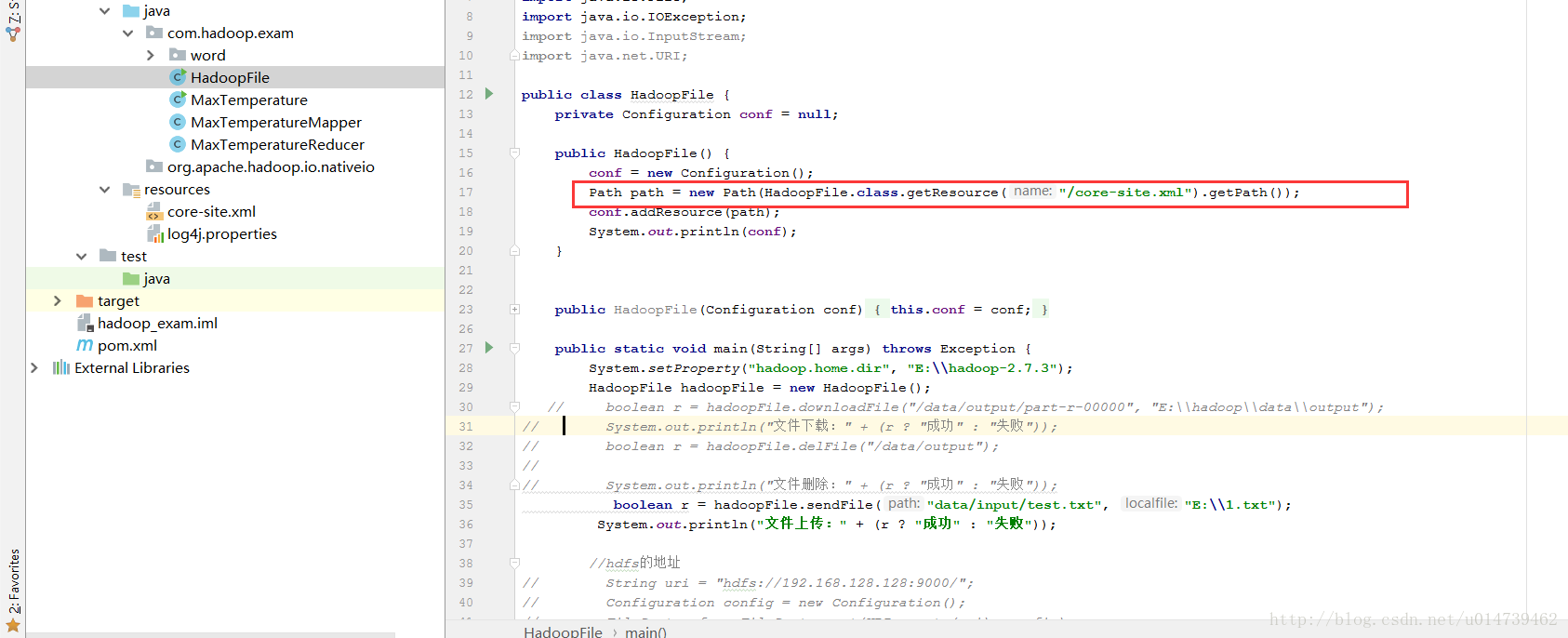
备注:
1:如果使用克隆虚拟机的方式生成slave节点,需要修改克隆机器名,编辑/etc/hostname,文件内容改为刚才slaves文件中配置的值。
2.在master上ssh连接slave1和slave2,测试免密码登陆是否成功,执行
ssh study_node_1 (即主机名称)
3.在master上启动hadoop,执行
start-all.sh
注意事项:
1.hadoop用户必须有/usr/local/hadoop文件夹读写权限















 2144
2144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









