







详细示例代码已上传,参见文末链接!
内容包括双Y轴柱状图表、堆叠柱状图表、饼图、水平条形图表、环形图表、生成词云图表、添加tag标签、数据输出列对齐问题、解决中文乱码、等等,希望对看到的朋友有帮助。
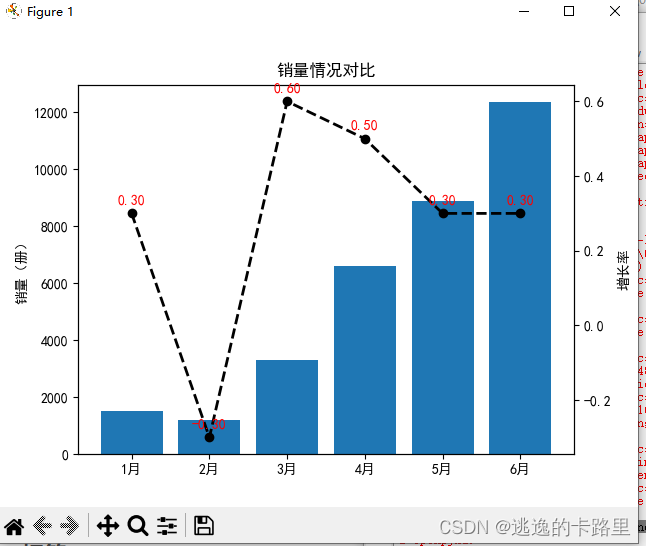
1、双Y轴可视化分析产品销量增长速度及趋势
代码运行需要安装库:
完美解决 ImportError: Missing optional dependency ‘openpyxl’. Use pip or conda to install openpyxl
报错:ModuleNotFoundError: No module named 'pandas’解决方法
pip install pandas
pip install matplotlib
pip install openpyxl
#如果下载失败,可采用下面的方法下载安装
pip install pandas -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
pip install openpyxl -i http://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com
实现代码:
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel('mrbook.xlsx') #导入Excel文件
x=[1,2,3,4,5,6]
y1=df['销量']
y2=df['rate']
fig = plt.figure()
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
ax1 = fig.add_subplot(111) #添加子图
plt.title('销量情况对比') #图表标题
#图表x轴标题
plt.xticks(x,['1月','2月','3月','4月','5月','6月'])
ax1.bar(x,y1,label='left')
ax1.set_ylabel('销量(册)') #y轴标签
ax2 = ax1.twinx() #共享x轴添加一条y轴坐标轴
ax2.plot(x,y2,color='black',linestyle='--',marker='o',linewidth=2,label=u"增长率")
ax2.set_ylabel(u"增长率")
for a,b in zip(x,y2):
plt.text(a, b+0.02, '%.2f' % b, ha='center', va= 'bottom',fontsize=10,color='red')
plt.show()
运行结果:
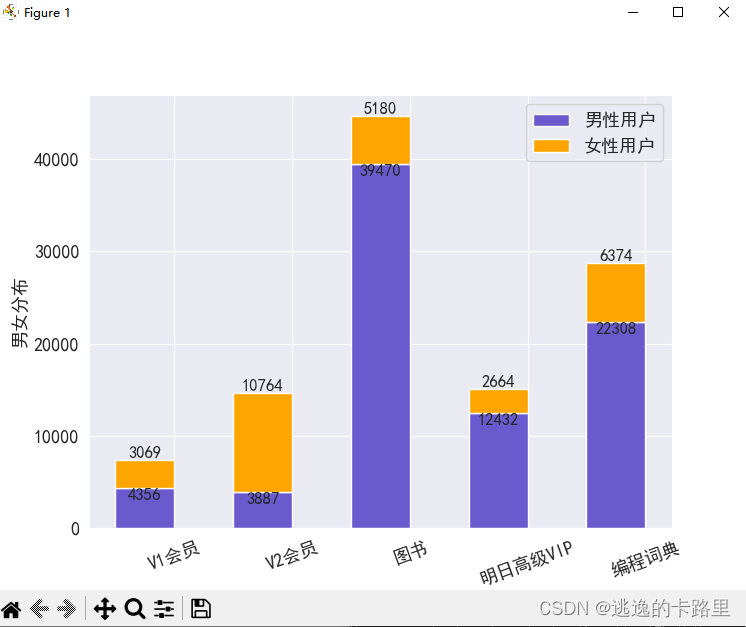
2、堆叠柱状图形分析用户体验结果
运行需要安装第三方模块pandas、matplotlib、seaborn、numpy
pip install pandas
pip install matplotlib
pip install seaborn
pip install numpy
#如果下载失败,可采用下面的方法下载安装
pip install pandas -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
pip install openpyxl -i http://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com
pip install seaborn -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
代码实现:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
sns.set_style('darkgrid')
file ='./data/mrtb_data.xlsx'
df = pd.DataFrame(pd.read_excel(file))
plt.rc('font', family='SimHei', size=13)
# 通过reset_index()函数将groupby()的分组结果重新设置索引
df1 = df.groupby(['类别'])['买家实际支付金额'].sum()
df2 = df.groupby(['类别','性别'])['买家会员名'].count().reset_index()
men_df=df2[df2['性别']=='男']
women_df=df2[df2['性别']=='女']
men_list=list(men_df['买家会员名'])
women_list=list(women_df['买家会员名'])
num=np.array(list(df1)) #消费金额
#计算男性用户比例
ratio=np.array(men_list)/(np.array(men_list)+np.array(women_list))
np.set_printoptions(precision=2) #使用set_printoptions设置输出的精度
#设置男生女生消费金额
men = num * ratio
women = num * (1-ratio)
df3=df2.drop_duplicates(['类别']) #去除类别重复的记录
name=(list(df3['类别']))
#生成图表
x = name
width = 0.5
idx = np.arange(len(x))
plt.bar(idx, men, width,color='slateblue', label='男性用户')
plt.bar(idx, women, width, bottom=men, color='orange', label='女性用户')
plt.xlabel('消费类别')
plt.ylabel('男女分布')
plt.xticks(idx+width/2, x, rotation=20)
#在图表上显示数字
for a,b in zip(idx,men):
plt.text(a, b, '%.0f' % b, ha='center', va='top',fontsize=12) #对齐方式'top', 'bottom', 'center', 'baseline', 'center_baseline'
for a,b,c in zip(idx,women,men):
plt.text(a, b+c+0.5, '%.0f' % b, ha='center', va= 'bottom',fontsize=12)
plt.legend()
plt.show()
运行结果:
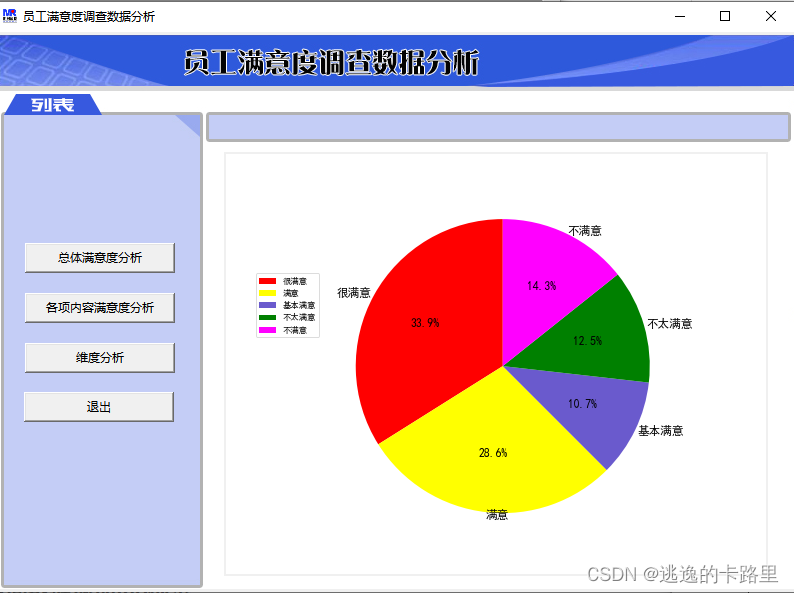
3、多图标实现员工满意度调查数据分析
代码运行需要安装第三方模块pandas、matplotlib、seaborn、numpy、pillow(PIL)
上面程序已经介绍过安装方法,这里不做介绍了。
代码实现:
from tkinter import *
import tkinter as tk
from PIL import Image, ImageTk
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
#设置数据显示的列数和宽度
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号
df = pd.read_excel('./data/employee_data.xlsx')
main = Tk()
main.title('员工满意度调查数据分析')#设置标题栏
#设置窗口的大小
main.geometry('800x560')
main.iconbitmap('./images/mr.ico') #窗体图标
#生成主界面
frame= tk.Frame()
frame.grid(row=0, column=0,padx=1,pady=1)
#添加背景图片
imgInfo = PhotoImage(file = './images/bg2.png')
lblImage = Label(frame, image = imgInfo)
lblImage.grid()
#显示图表
def chart_view(f1):
img_open = Image.open(f1)
img = ImageTk.PhotoImage(img_open)
chart_preview.config(image=img)
chart_preview.image = img
main.update_idletasks() #更新图片,必须update
chart_preview.place(x = 230, y = 120) #图表位置
def chart1():
f1='mr01.png'
#总体情况分析(饼形图)很满意、满意等各多少项,所占百分比
df1=df.groupby(['调查内容','满意度'])['员工匿名'].count().reset_index()
a_df=df1[df1['满意度']=='很满意']
b_df=df1[df1['满意度']=='满意']
c_df=df1[df1['满意度']=='基本满意']
d_df=df1[df1['满意度']=='不太满意']
e_df=df1[df1['满意度']=='不满意']
a=len(list(a_df['调查内容']))
b=len(list(b_df['调查内容']))
c=len(list(c_df['调查内容']))
d=len(list(d_df['调查内容']))
e=len(list(e_df['调查内容']))
plt.figure(figsize=(9,7)) #调节图形大小
labels = ['很满意','满意','基本满意','不太满意','不满意'] #定义标签
sizes = [a,b,c,d,e] #设置饼形图每块的值
colors = ['red', 'yellow', 'slateblue', 'green','magenta'] #设置饼形图每块的颜色
patches, l_text, p_text = plt.pie(sizes, #绘图数据
labels=labels,#添加区域水平标签
colors=colors,# 设置饼图的自定义填充色
labeldistance=1.02,#设置各扇形标签(图例)与圆心的距离
autopct='%.1f%%',# 设置百分比的格式,这里保留一位小数
startangle=90,# 设置饼图的初始角度
radius = 0.5, # 设置饼图的半径
center = (0.2,0.2), # 设置饼图的原点
textprops = {'fontsize':14, 'color':'k'}, # 设置文本标签的属性值
pctdistance=0.6)# 设置百分比标签与圆心的距离
# 设置x,y轴刻度一致,这样饼图才能是圆的
plt.axis('equal')
#显示图例
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 0.8))
plt.grid()
plt.savefig('mr01.png',dpi=60)
chart_view(f1)
def chart2():
f1='mr02.png'
df['很满意'] = df.apply(lambda row: 1 if row['满意度']=='很满意'else 0, axis=1)
df['满意'] = df.apply(lambda row: 1 if row['满意度']=='满意'else 0, axis=1)
df['基本满意'] = df.apply(lambda row: 1 if row['满意度']=='基本满意'else 0, axis=1)
df['不太满意'] = df.apply(lambda row: 1 if row['满意度']=='不太满意'else 0, axis=1)
df['不满意'] = df.apply(lambda row: 1 if row['满意度']=='不满意'else 0, axis=1)
df1 = df.groupby(['调查内容'])['很满意','满意','基本满意','不太满意','不满意'].sum().reset_index()
#某一项的满意率=(很满意人数*100+满意人数*80+基本满意人数*60+不太满意人数*30+不满意人数*0)/总人数
df3=(df1['很满意']*100+df1['满意']*80+df1['基本满意']*60+df1['不太满意']*30+df1['不满意']*0)/8
name_list =df1['调查内容'].values.tolist()
num_list=df3.values.tolist()
f, ax = plt.subplots(figsize=(7,5))#调节图表大小
#画横向水平条形图
plt.barh(name_list, num_list,color='dodgerblue')
plt.xticks(fontsize = 8)
plt.yticks(fontsize = 8)
plt.subplots_adjust(left=0.5, wspace=0.35, hspace=0.25,
bottom=0.13, top=0.91)
#横向水平条形图加百分比标注
for y, x in enumerate(df3):
plt.text(x+0.2, y-0.3, "%.f%%" %x,family='simhei',fontsize=11)
f.savefig('mr02.png',dpi=80)
chart_view(f1)
def chart3():
f1='mr03.png'
df['很满意'] = df.apply(lambda row: 1 if row['满意度']=='很满意'else 0, axis=1)
df['满意'] = df.apply(lambda row: 1 if row['满意度']=='满意'else 0, axis=1)
df['基本满意'] = df.apply(lambda row: 1 if row['满意度']=='基本满意'else 0, axis=1)
df['不太满意'] = df.apply(lambda row: 1 if row['满意度']=='不太满意'else 0, axis=1)
df['不满意'] = df.apply(lambda row: 1 if row['满意度']=='不满意'else 0, axis=1)
df1 = df.groupby(['类别'])['很满意','满意','基本满意','不太满意','不满意'].sum().reset_index()
#某一项的满意率=(很满意人数*100+满意人数*80+基本满意人数*60+不太满意人数*30+不满意人数*0)/总人数
num1=df1['类别']
df3=(df1['很满意']*100+df1['满意']*80+df1['基本满意']*60+df1['不太满意']*30+df1['不满意']*0)/(df1['很满意']+df1['满意']+df1['基本满意']+df1['不太满意']+df1['不满意'])
print(df3)
labels = np.array(df1['类别']) # 标签
dataLenth = 4 # 数据长度
data_radar = np.array(df3) # 数据
angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False) # 分割圆周长
data_radar = np.concatenate((data_radar, [data_radar[0]])) # 闭合
angles = np.concatenate((angles, [angles[0]])) # 闭合
plt.figure(figsize=(6,5)) #调节图形大小
plt.polar(angles, data_radar, 'bo-', linewidth=1) # 极坐标系
plt.thetagrids(angles * 180/np.pi, labels) # 标签
plt.fill(angles, data_radar, facecolor='r', alpha=0.25)# 填充
plt.ylim(0, 100) #设置显示的极径范围
plt.savefig('mr03.png',dpi=80)
chart_view(f1)
def close():
main.destroy() #关闭tkinter窗口destroy()方法
#添加命令按钮
button1=tk.Button(frame,width=20,text='总体满意度分析',command=chart1).place(x=30, y=210)
button2=tk.Button(frame,width=20,text='各项内容满意度分析',command=chart2).place(x=30, y=260)
button3=tk.Button(frame,width=20,text='维度分析',command=chart3).place(x=30, y=310)
button4=tk.Button(main,width=20,text='退出',command=close).place(x=30, y=360)
#添加显示图表的Label
chart_preview=tk.Label(main)
# 主窗口循环显示
main.mainloop()
main.update()
运行结果:
4、QQ群聊天数据分析
代码运行需要安装第三方模块matplotlib、jieba、wordcloud
闭坑指南:
报错:ModuleNotFoundError: No module named ‘wordcloud’
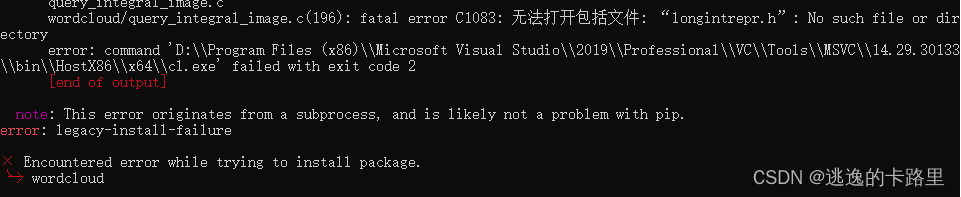
报错cl.exe failed with exit status 2通用解决方法
安装wordcloud失败,出现error: command ‘C:\****\bin\HostX86\x86\cl.exe’ failed with exit status 2
报错: note: This error originates from a subprocess, and is likely not a problem with pip. error: legacy-install-failure
报错问题如图:
有资料说通过pip install wordcloud==,获取所有库版本,然后安装最新的就可以,测试也不行,可能适用于其他的库吧。

最后成功:
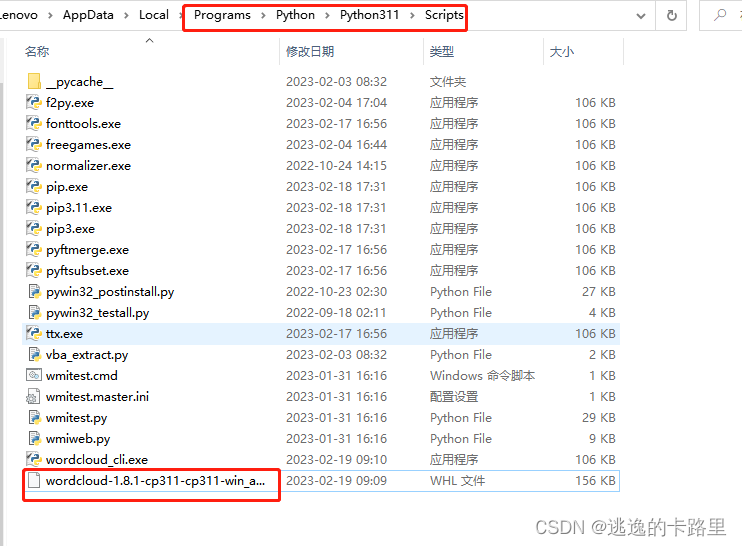
安装wordcloud时出现错误,一直安装不上,换了很多种方法,用命令行安装也出现了error: command ‘C:\****\bin\HostX86\x86\cl.exe’ failed with exit status 2如下提示,所以后面我直接去官网下载whl文件,记得找到和你python和windows相匹配的版本,其中cp311,代表的是你的python3.11版本。
wordcloud库 下载地址

之后把whl文件放到你的pip.exe文件对应的父文件夹Scripts下,然后命令行cd到该文件夹下,然后 pip install ****.whl
pip install wordcloud-1.8.1-cp311-cp311-win_amd64.whl
代码示例:
import re
import matplotlib.pyplot as plt
from matplotlib import colors
import jieba
import wordcloud
# 按行读取群聊天记录(文本文件)
f = open('qun.txt','r',encoding='utf-8')
fl = f.readlines()
del fl[:8] #del删除切片(前8行数据)
fl = fl[1::3] #提取下标为1,步长为3的切片
str1 = ' '.join(fl) #join()函数分割文本数据
#滤除无用文本
str1 = str1.replace('[QQ红包]请使用新版手机QQ查收红包。','')
str1 = str1.replace('[群签到]请使用新版QQ进行查看。','')
#通过re模块的findall将[表情]和[图片]转义成字符,然后使用replace滤除
list1 = re.findall(r'\[.+?\]', str1)
for item in list1:
str1 = str1.replace(item, '')
#自定义颜色
color_list=['#CD853F','#DC143C','#00FF7F','#FF6347','#8B008B','#00FFFF','#0000FF','#8B0000','#FF8C00','#1E90FF','#00FF00','#FFD700','#008080','#008B8B','#8A2BE2','#228B22','#FA8072','#808080']
colormap=colors.ListedColormap(color_list)
# 分词制作词云图
word_list = jieba.cut(str1, cut_all=True)
word = ' '.join(word_list)
Mywordcloud= wordcloud.WordCloud(mask=None, font_path='simhei.ttf',width=3000,colormap=colormap,height=2000,background_color = '#383838').generate(word)
plt.imshow(Mywordcloud)
plt.axis('off')
plt.show()
运行结果:

5、批量为电商数据添加tag标签
运行代码需要安装第三方模块pandas
代码示例:
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
aa ='mrbook.xlsx'
df = pd.DataFrame(pd.read_excel(aa)) #读取Excel数据为dataframe
#定义标签函数
def add_tag(data):
global tag
tag=''
if '零' in data:
tag ='零基础|'+tag
if '例' in data:
tag='实例|'+tag
if '项目' in data:
tag='项目|'+tag
if 'C#' in data:
tag='C#|'+tag
if 'Android' in data:
tag='Android|'+tag
if 'SQL' in data:
tag='SQL|'+tag
if 'Python' in data:
tag='Python|'+tag
if 'Oracle' in data:
tag='Oracle|'+tag
return tag
#将添加的标签保存到tag列中
df['tag'] = df['图书名称'].apply(add_tag)
print(df)
#保存数据为excel
df.to_excel('mrbook副本.xlsx')
运行结果:

最后
希望对看到的朋友有所帮助,下载地址:python学习代码示例数据分析和图表的应用(第一部分)

















 3388
3388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











