







一 分别用递归和非递归方式实现二叉树先序、中序和后序遍历
用递归和非递归方式,分别按照二叉树先序、中序和后序打印所有的节点。我们约定:先序遍历顺序为根、左、右;中序遍历顺序为左、根、右;后序遍历顺序为左、右、根。
递归方式
// 递归方式进行先序遍历
public void preorderRecursive(TreeNode root) {
if (root == null) return;
System.out.print(root.val + " "); // 打印当前节点
preorderRecursive(root.left); // 递归遍历左子树
preorderRecursive(root.right); // 递归遍历右子树
}
// 递归方式进行中序遍历
public void inorderRecursive(TreeNode root) {
if (root == null) return;
inorderRecursive(root.left); // 递归遍历左子树
System.out.print(root.val + " "); // 打印当前节点
inorderRecursive(root.right); // 递归遍历右子树
}
// 递归方式进行后序遍历
public void postorderRecursive(TreeNode root) {
if (root == null) return;
postorderRecursive(root.left); // 递归遍历左子树
postorderRecursive(root.right); // 递归遍历右子树
System.out.print(root.val + " "); // 打印当前节点
}非递归方式,用堆栈
public void preOrderUnRecur(Node head) {
System.out.println("pre-order:");
if (head != null) {
Stack<Node> stack = new Stack<Node>();
stack.add(head);
while (!stack.isEmpty()) {
head = stack.pop();
System.out.println(head.value + " "); // 打印当前节点
// 先将右子节点入栈,再将左子节点入栈,保证弹出时的顺序是先左后右
if (head.right != null) {
stack.push(head.right);
}
if (head.left != null) {
stack.push(head.left);
}
}
}
System.out.println();
}
public void inOrderUnRecur(Node head) {
System.out.println("in-order:");
if (head != null) {
Stack<Node> stack = new Stack<Node>();
while (!stack.isEmpty() || head != null) {
if (head != null) {
stack.push(head);
head = head.left; // 将左子节点入栈
} else {
head = stack.pop();
System.out.println(head.value + " "); // 打印当前节点
head = head.right; // 遍历右子树
}
}
}
System.out.println();
}
public void posOrderUnRecur1(Node head) {
System.out.println("post-order:");
if (head != null) {
Stack<Node> s1 = new Stack<Node>();
Stack<Node> s2 = new Stack<Node>();
s1.push(head);
while (!s1.isEmpty()) {
head = s1.pop();
s2.push(head);
// 先将右子节点入栈,再将左子节点入栈,保证弹出时的顺序是先左后右,进入s2时就是先右后左
if (head.right != null) {
s1.push(head.right);
}
if (head.left != null) {
s1.push(head.left);
}
}
while (!s2.isEmpty()) {
System.out.println(s2.pop().value + " "); // 打印当前节点
}
}
System.out.println();
}
public void posOrderUnRecur2(Node h) {
System.out.println("post-order:");
if (h != null) {
Stack<Node> s1 = new Stack<Node>();
s1.push(h);
Node cNode = null;
while (!s1.isEmpty()) {
cNode = s1.peek();
if (cNode.left != null && h != cNode.left && h != cNode.right) {
s1.push(cNode.left); // 将左子节点入栈
} else if (cNode.right != null && h != cNode.right) {
s1.push(cNode.right); // 将右子节点入栈
} else {
System.out.print(s1.pop().value + " "); // 打印当前节点
h = cNode;
}
}
}
System.out.println();
}这些函数都使用了栈来模拟递归过程。具体来说:
- preOrderUnRecur函数使用栈来模拟先序遍历的过程,先将根节点入栈,并在循环中弹出节点并打印,先将右子节点入栈,再将左子节点入栈。
- inOrderUnRecur函数使用栈来模拟中序遍历的过程,始终将左子节点入栈,直到没有左子节点,然后弹出节点并打印,再将右子节点入栈。
- posOrderUnRecur1函数使用两个栈来模拟后序遍历的过程,最终打印第二个栈中的节点,具体过程是先将根节点入栈1,然后循环中弹出节点并入栈2,先将左子节点入栈1,再将右子节点入栈1。
- posOrderUnRecur2函数使用单个栈来模拟后序遍历的过程,通过判断当前节点的左右子节点和上一个弹出的节点来确定是否打印当前节点
二 打印二叉树的边界节点
【题目】
给定一棵二叉树的头节点head,按照如下两种标准分别实现二叉树边界节点的逆时针打印。
标准一:1.头节点为边界节点。
2.叶节点为边界节点。3.如果节点在其所在的层中是最左的或最右的,那么该节点也是边界节点。
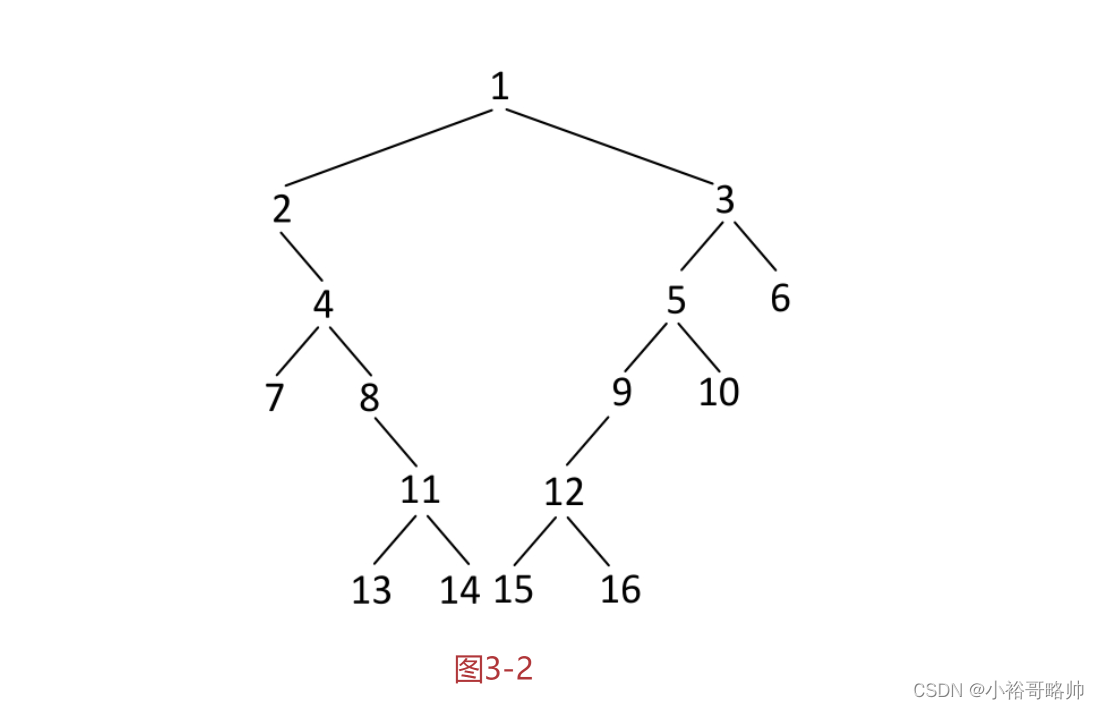
按标准一的打印结果为:
1,2,4,7,11,13,14,15,16,12,10,6,3
【要求】
1.如果节点数为N,两种标准实现的时间复杂度要求都为O(N),额外空间复杂度要求都为O(h),h为二叉树的高度。
2.两种标准都要求逆时针顺序且不重复打印所有的边界节点。
public class PrintBinaryTreeBoundaryNodeStandard1 {
// 定义二叉树节点类
public static class Node {
public int data;
public Node left;
public Node right;
public Node(int data) {
this.data = data;
}
}
// 主函数,打印二叉树边界节点
public static void printBoundaryNodeStandard1(Node root) {
if (root == null) {
return;
}
// 获取二叉树高度,用于创建边界节点数组
int height = getHeight(root, 0);
Node[][] edgeMap = new Node[height][2];
// 构建边界节点映射
setEdgeMap(root, 0, edgeMap);
// 打印左边界
for (int i = 0; i != edgeMap.length; i++) {
System.out.print(edgeMap[i][0].data + " ");
}
// 打印既不是左边界,也不是右边界的叶子节点
printLeafNotInMap(root, 0, edgeMap);
// 打印右边界,但不是左边界的节点
for (int i = edgeMap.length - 1; i != -1; i--) {
if (edgeMap[i][0] != edgeMap[i][1]) {
System.out.print(edgeMap[i][1].data + " ");
}
}
System.out.println();
}
// 获取二叉树的高度
private static int getHeight(Node root, int level) {
if (root == null) {
return level;
}
return Math.max(getHeight(root.left, level + 1), getHeight(root.right, level + 1));
}
// 构建边界节点映射
private static void setEdgeMap(Node root, int level, Node[][] edgeMap) {
if (root == null) {
return;
}
// 更新最左边界节点
edgeMap[level][0] = edgeMap[level][0] == null ? root : edgeMap[level][0];
// 更新最右边界节点
edgeMap[level][1] = root;
// 递归构建左子树边界映射
setEdgeMap(root.left, level + 1, edgeMap);
// 递归构建右子树边界映射
setEdgeMap(root.right, level + 1, edgeMap);
}
// 打印既不是左边界,也不是右边界的叶子节点
private static void printLeafNotInMap(Node root, int level, Node[][] map) {
if (root == null) {
return;
}
// 如果是叶子节点且不在边界节点映射中,则打印
if (root.left == null && root.right == null && root != map[level][0] && root != map[level][1]) {
System.out.print(root.data + " ");
}
// 递归遍历左子树
printLeafNotInMap(root.left, level + 1, map);
// 递归遍历右子树
printLeafNotInMap(root.right, level + 1, map);
}
}解题思路:
- 首先定义了二叉树节点类
Node,包含数据和左右子节点。 - 主函数
printBoundaryNodeStandard1用于打印二叉树边界节点,首先获取二叉树的高度,并根据高度创建边界节点数组edgeMap。 - 使用
setEdgeMap函数构建边界节点映射,其中更新每层最左边和最右边的节点。 - 依次打印左边界节点、非边界叶子节点、右边界节点。
getHeight函数用于获取二叉树的高度,printLeafNotInMap函数用于打印既不是左边界,也不是右边界的叶子节点。
三 如何较为直观地打印二叉树
* 【题目】
* 二叉树可以用常规的三种遍历结果来描述其结构,但是不够直观,尤其是二叉树中有重复值的时候,仅通过三种遍历的结果来构造二叉
* 树的真实结构更是难上加难,有时候根本不可能。给定一棵二叉树的头节点head,已知二叉树节点值的类型为32位整数,请实现一个
* 打印二叉树的函数,可以直观地展示树的形状,也便于画出真实的结构。
*
* 【难度】
* 中等
*
* 【解答】
* 这是一道较开放的题目,面试者不仅要设计出符合要求且不会产生歧义的打印方式,还要考虑实现难度,在面试时仅仅写出思路必然是
* 不满足代码面试要求的。本文给出一种符合要求且代码量不大的实现,希望读者也能实现并优化自己的设计。具体过程如下:
*
* 1、设计打印的样式。实现者首先应该解决的问题是用什么样的方式来无歧义地打印二叉树。本文设计的打印样式如下所示。
The binary tree is:
v3v
v5v
^1^
H2H
v8v
^3^
^7^
* 下面解释一下如何看打印的结果。首先,二叉树大概的样子是把打印结果顺时针旋转90度;接下来,怎么清晰地确定任何一个节点的父
* 节点呢?如果一个节点打印结果的前缀与后缀都有"H",说明这个节点是头节点,当然就不存在父节点。如果一个节点打印结果的前缀
* 与后缀都有"v",表示父节点在该节点所在列的前一列,在该节点所在行的下方,并且是离该节点最近的节点。如果一个节点打印结果
* 的前缀与后缀都有"^",表示父节点在该节点所在列的前一列,在该节点所在行的上方,并且是离该节点最近的节点。
*
* 2、一个需要重点考虑的问题——规定节点打印时占用的统一长度。我们必须规定一个节点在打印时到底占多长。在Java中,整型值占
* 用长度最长的值是Integer.MIN_VALUE(即-2147483648),占用的长度为11,加上前缀和后缀("H"、"v"或"^")之后占用长
* 度为13。为了在打印之后更好地区分,再把前面加上两个空格,后面加上两个空格,总共占用长度为17。也就是说长度为17的空间必
* 然可以放下任何一个32位整数,同时样式还不错。至此,我们约定,打印每一个节点的时候,必须让每一个节点在打印时占用长度都为
* 17,如果不足,前后都用空格补齐。
*
* 3、确定了打印的样式,规定了占用长度的标准,最后来解释具体的实现。打印的整体过程结合了二叉树先右子树、再根节点、最后左
* 子树的递归遍历过程。如果递归到一个节点,首先遍历它的右子树。右子树遍历结束后,回到这个节点。如果这个节点所在层为
* layer,那么先打印layer*17个空格(不换行),然后开始制作该节点的打印内容,这个内容当然包括节点的值,以及确定的前后缀
* 字符。如果该节点是其父节点的右孩子,前后缀为"v",如果是其父节点的左孩子,前后缀为"^",如果是头节点,前后缀为"H"。最
* 后在前后分别贴上数量几乎一致的空格,占用长度为17的打印内容就制作完成了,打印这个内容后换行,最后进行左子树的遍历过程。
*
* 直观地打印二叉树的所有过程请参看如下代码中的print方法
public class BinaryTreePrinter1 {
// 定义二叉树节点类
public static class Node {
public int data; // 节点数据
public Node left; // 左子节点
public Node right; // 右子节点
// 构造函数
public Node(int data) {
this.data = data;
}
}
// 打印二叉树的主函数
public static void print(Node root) {
System.out.println("The binary tree is:");
// 调用辅助函数进行中序遍历打印
printInOrder(root, 0, "H", 17);
}
// 辅助函数:中序遍历打印二叉树
private static void printInOrder(Node root, int height, String to, int len) {
// 如果节点为空,直接返回
if (root == null) {
return;
}
// 递归调用,先打印右子树
printInOrder(root.right, height + 1, "v", len);
// 构造节点值的字符串表示
String val = to + root.data + to;
int lenM = val.length();
int lenL = (len - lenM) / 2;
int lenR = len - lenM - lenL;
val = getSpace(lenL) + val + getSpace(lenR); // 填充空格
// 打印当前节点
System.out.println(getSpace(height * len) + val);
// 递归调用,打印左子树
printInOrder(root.left, height + 1, "^", len);
}
// 辅助函数:生成指定数量的空格字符串
private static String getSpace(int num) {
String space = " ";
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < num; i++) {
stringBuilder.append(space);
}
return stringBuilder.toString();
}
// 主函数,程序入口
public static void main(String[] args) {
// 构造二叉树
Node node1 = new Node(2);
Node node2 = new Node(3);
Node node3 = new Node(5);
Node node4 = new Node(7);
Node node5 = new Node(8);
Node node6 = new Node(1);
Node node7 = new Node(3);
node1.left = node2;
node1.right = node3;
node2.left = node4;
node2.right = node5;
node3.left = node6;
node3.right = node7;
// 打印二叉树
print(node1);
}
}这段代码的主要思路是使用中序遍历来打印二叉树。具体来说,它采用了递归的方式,在每次递归调用中,先打印右子树,然后构造并打印当前节点的字符串表示,最后打印左子树。
下面是代码中的几个关键步骤:
1. **print方法**:这是打印二叉树的入口方法。它首先输出提示信息,然后调用printInOrder方法开始进行中序遍历打印。
2. **printInOrder方法**:这是辅助方法,用于中序遍历打印二叉树。在每次递归调用中,首先递归打印右子树,然后构造当前节点的字符串表示,并在适当位置填充空格,最后输出当前节点。接着递归打印左子树。
3. **getSpace方法**:这是一个辅助方法,用于生成指定数量的空格字符串。
4. **主函数**:在主函数中构造了一个简单的二叉树,然后调用print方法来打印二叉树。
总的来说,该方法利用中序遍历的特性,先遍历右子树再遍历左子树的顺序,来实现二叉树的打印。在打印每个节点时,通过合适的空格填充来保持节点的对齐,从而使得打印结果更加直观易读。
解法二
public class BinaryTreePrinter2 {
public static class Node {
public int data;
public Node left;
public Node right;
public Node(int data) {
this.data = data;
}
}
// 打印二叉树的入口方法
public static void print(Node root) {
if (root == null) {
System.out.println("Empty binary tree!");
return;
}
// 计算二叉树的高度
int height = getHeight(root);
// 计算输出字符串数组的高度和宽度
int arrHeight = height * 2 - 1;
int arrWidth = (2 << (height - 2)) * 3 + 1;
// 创建字符串数组用于存储二叉树的结构
String[][] r = new String[arrHeight][arrWidth];
// 初始化字符串数组
for (int i = 0; i < arrHeight; i++) {
for (int j = 0; j < arrWidth; j++) {
r[i][j] = " ";
}
}
// 将二叉树结构写入字符串数组
writeToArray(height, root, r, 0, arrWidth / 2);
// 打印字符串数组,形成树形结构的输出
for (String[] line : r) {
StringBuilder strBuilder = new StringBuilder();
for (int i = 0; i < line.length; i++) {
strBuilder.append(line[i]);
// 控制节点之间的间距
if (line[i].length() > 1 && i <= line.length - 1) {
i += line[i].length() > 4 ? 2 : line[i].length() - 1;
}
}
System.out.println(strBuilder);
}
}
// 计算二叉树的高度
private static int getHeight(Node root) {
return root == null ? 0 : (1 + Math.max(getHeight(root.left), getHeight(root.right)));
}
// 将二叉树结构写入字符串数组
private static void writeToArray(int height, Node node, String[][] r, int i, int j) {
if (node == null) {
return;
}
// 将节点数据转换为字符串并写入数组
r[i][j] = String.valueOf(node.data);
// 计算当前节点所在的层数
int curLevel = (i + 1) >> 1;
if (curLevel == height) {
return;
}
// 计算当前层与树顶的距离
int gap = height - curLevel - 1;
// 处理左子树
if (node.left != null) {
r[i + 1][j - gap] = "/"; // 左斜线
writeToArray(height, node.left, r, i + 2, j - gap * 2);
}
// 处理右子树
if (node.right != null) {
r[i + 1][j + gap] = "\\"; // 右斜线
writeToArray(height, node.right, r, i + 2, j + gap * 2);
}
}
public static void main(String[] args) {
// 构造一个简单的二叉树
Node node1 = new Node(2);
Node node2 = new Node(3);
Node node3 = new Node(5);
Node node4 = new Node(7);
Node node5 = new Node(8);
Node node6 = new Node(1);
Node node7 = new Node(3);
node1.left = node2;
node1.right = node3;
node2.left = node4;
node2.right = node5;
node3.left = node6;
node3.right = node7;
// 打印二叉树
print(node1);
}
}
四 二叉树的序列化和反序列化
【题目】二叉树被记录成文件的过程叫作二叉树的序列化,通过文件内容重建原来二叉树的过程叫作二叉树的反序列化。给定一棵二叉树的头点head,并已知二叉树节点值的类型为32位整型。请设计一种二叉树序列化和反序列化的方案,并用代码实现。
方法一:通过先序遍历实现序列化和反序列化。
*
* 先介绍先序遍历下的序列化过程,首先假设序列化的结果字符串为str,初始时str=""。先序遍历二叉树,如果遇到null节点,就在
* str的末尾加上"#!","#"表示这个节点为空,节点值不存在,"!"表示一个值的结束;如果遇到不为空的节点,假设节点值为3,就
* 在str的末尾加上"3!"。
* 为什么在每一个节点值的后面都要加上"!"呢?因为如果不标记一个值的结束,最后产生的结果会有歧义。
* 先序遍历序列化的全部过程请参看如下代码中的serialize1方法。
*
* 接下来介绍如何通过先序遍历序列化的结果字符串str,重构二叉树的过程,即反序列化。
* 把结果字符串str变成字符串类型的数组,记为values,数组代表一棵二叉树先序遍历的节点顺序。
* 先序遍历反序列化的全部过程请参看如下代码中的deserialize1方法。
import java.util.LinkedList;
import java.util.Queue;
// 定义二叉树节点类
class Node {
int data;
Node left;
Node right;
// 构造函数
Node(int data) {
this.data = data;
}
}
public class BinaryTreeSerializationDeserialization1 {
// 序列化二叉树为字符串
public static String serialize1(Node root) {
// 如果根节点为空,返回 "#" 表示空节点
if (root == null) {
return "#!";
}
// 否则,将节点值加入字符串,后面加上 "!" 作为分隔符
String r = root.data + "!";
// 递归序列化左子树和右子树
r += serialize1(root.left);
r += serialize1(root.right);
return r;
}
// 反序列化字符串为二叉树
public static Node deserialize1(String s) {
// 将序列化的字符串按 "!" 分割成数组
String[] values = s.split("!");
Queue<String> queue = new LinkedList<>();
// 将分割后的字符串放入队列中
for (int i = 0; i != values.length; i++) {
queue.offer(values[i]);
}
// 调用辅助方法进行反序列化
return preOrderDeserialize(queue);
}
// 辅助方法,根据前序遍历的顺序进行反序列化
private static Node preOrderDeserialize(Queue<String> queue) {
// 从队列中取出一个值
String value = queue.poll();
// 如果值为 "#",表示当前节点为空,返回 null
if (value.equals("#")) {
return null;
}
// 否则,将值转换为整数作为当前节点的值
Node root = new Node(Integer.parseInt(value));
// 递归反序列化左子树和右子树
root.left = preOrderDeserialize(queue);
root.right = preOrderDeserialize(queue);
return root;
}
// 测试函数
public static void main(String[] args) {
// 创建一棵二叉树
Node node1 = new Node(2);
Node node2 = new Node(3);
Node node3 = new Node(5);
Node node4 = new Node(7);
Node node5 = new Node(8);
Node node6 = new Node(1);
Node node7 = new Node(3);
node1.left = node2;
node1.right = node3;
node2.left = node4;
node2.right = node5;
node3.left = node6;
node3.right = node7;
// 序列化二叉树
String s = serialize1(node1);
System.out.printf("The serialized string is: %s%n", s);
// 反序列化二叉树
Node root = deserialize1(s);
// 打印反序列化后的二叉树
BinaryTreePrinter2.print(root);
}
}方法二:通过层遍历实现序列化和反序列化。
* 先介绍层遍历下的序列化过程,首先假设序列化的结果字符串为str,初始时str=""。然后实现二叉树的按层遍历,具体方式是利用队列结构,这也是宽度遍历图的常见方式。层遍历序列化的全部过程请参看如下代码中的serialize2方法。
*
* 先序遍历的反序列化其实就是重做先序遍历,遇到"#"就生成null节点,结束生成后续子树的过程。
* 与根据先序遍历的反序列化过程一样,根据层遍历的反序列化是重做层遍历,遇到"#"就生成null节点,同时不把null节点放到队列 里即可。层遍历反序列化的全部过程请参看如下代码中的deserialize2方法。
```java
public class BinaryTreeSerializationDeserialization2 {
/**
* 二叉树节点类
*/
static class Node {
int data;
Node left, right;
Node(int data) {
this.data = data;
left = right = null;
}
}
/**
* 将二叉树序列化为字符串
* @param root 根节点
* @return 序列化后的字符串
*/
public static String serialize2(Node root) {
// 如果根节点为空,则返回一个特殊标记 "#!"
if (root == null) {
return "#!";
}
// 使用 StringBuilder 存储序列化结果
StringBuilder result = new StringBuilder(root.data + "!");
// 使用队列进行层序遍历二叉树
Queue<Node> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
root = queue.poll();
// 如果左子节点不为空,将其值添加到结果中,并将左子节点加入队列
if (root.left != null) {
result.append(root.left.data).append("!");
queue.offer(root.left);
} else {
// 如果左子节点为空,添加特殊标记 "#!"
result.append("#!");
}
// 如果右子节点不为空,将其值添加到结果中,并将右子节点加入队列
if (root.right != null) {
result.append(root.right.data).append("!");
queue.offer(root.right);
} else {
// 如果右子节点为空,添加特殊标记 "#!"
result.append("#!");
}
}
return result.toString();
}
/**
* 将字符串反序列化为二叉树
* @param s 序列化后的字符串
* @return 反序列化后的根节点
*/
public static Node deserialize2(String s) {
// 将序列化后的字符串根据特殊标记 "#" 分割成节点值数组
String[] values = s.split("!");
int index = 0;
// 根据数组第一个值创建根节点
Node root = generateNodeByString(values[index++]);
// 使用队列辅助进行反序列化
Queue<Node> queue = new LinkedList<>();
if (root != null) {
queue.offer(root);
}
Node node = null;
// 遍历节点值数组,逐个恢复二叉树的结构
while (!queue.isEmpty()) {
node = queue.poll();
// 根据节点值数组恢复左子节点
node.left = generateNodeByString(values[index++]);
// 根据节点值数组恢复右子节点
node.right = generateNodeByString(values[index++]);
// 如果左子节点不为空,将其加入队列
if (node.left != null) {
queue.offer(node.left);
}
// 如果右子节点不为空,将其加入队列
if (node.right != null) {
queue.offer(node.right);
}
}
return root;
}
/**
* 根据字符串生成节点
* @param s 输入字符串
* @return 生成的节点,如果为"#"则返回null
*/
private static Node generateNodeByString(String s) {
// 如果字符串为特殊标记 "#", 返回null
if (s.equals("#")) {
return null;
}
// 否则根据字符串值创建新的节点
return new Node(Integer.parseInt(s));
}
/**
* 测试主函数
* @param args 主函数参数
*/
public static void main(String[] args) {
// 创建一棵二叉树
Node node1 = new Node(2);
Node node2 = new Node(3);
Node node3 = new Node(5);
Node node4 = new Node(7);
Node node5 = new Node(8);
Node node6 = new Node(1);
Node node7 = new Node(3);
// 构建二叉树的结构
node1.left = node2;
node1.right = node3;
node2.left = node4;
node2.right = node5;
node3.left = node6;
node3.right = node7;
// 序列化二叉树
String s = serialize2(node1);
// 输出序列化结果
System.out.printf("The serialized string is: %s%n", s);
// 反序列化二叉树
Node root = deserialize2(s);
// 打印反序列化后的二叉树
BinaryTreePrinter2.print(root);
}
}
```
五 遍历二叉树的神级方法
*
* 【题目】
* 给定一棵二叉树的根节点root,完成二叉树的先序、中序和后序遍历。如果二叉树的节点数为N,要求时间复杂度为O(N),额外空间
* 复杂度为O(1)。
*
* 【难度】
* 相当困难
*
* 【解答】
* 本题真正的难点在于对复杂度的要求,尤其是额外空间复杂度为O(1)的限制。之前的题目已经剖析过如何用递归和非递归的方法实现
遍历二叉树,很不幸,之前所有的方法虽然常用,但都无法做到额外空间复杂度为O(1)。这是因为遍历二叉树的递归方法实际使用了
* 函数栈,非递归的方法使用了申请的栈,两者的额外空间都与树的高度相关,所以空间复杂度为O(h),h为二叉树的高度。如果完全不
* 用栈结构能完成三种遍历吗?可以。答案是使用二叉树节点中大量指向null的指针,本题实际上就是大名鼎鼎的Morris遍历,由
* Joseph Morris于1979年发明。
*
* 首先来看普通的递归和非递归解法,其实都使用了栈结构,在处理完二叉树某个节点后可以回到上层去。为什么从下层回到上层会如此
* 之难?因为二叉树的结构如此,每个节点都有指向孩子节点的指针,所以从上层到下层容易,但是没有指向父节点的指针,所以从下层
* 到上层需要用栈结构辅助完成。
* Morris遍历的实质就是避免用栈结构,而是让下层到上层有指针,具体是通过让底层节点指向null的空闲指针指回上层的某个节点,
* 从而完成上层到上层的移动。我们知道,二叉树上的很多节点都有大量的空闲指针,比如,某些节点没有右孩子,那么这个节点的
* right指针就指向null,我们称为空闲状态,Morris遍历正是利用了这些空闲指针。
*
* 在介绍Morris先序和后序遍历之前,我们先展示Morris中序遍历的过程。
* 1、假设当前子树的头节点为h,让h的左子树中最右节点的right指针指向h,然后h的左子树继续步骤1的处理过程,直到遇到某一
个节点没有左子树时记为node,进入步骤2。
* 2、从node开始通过每个节点的right指针进行移动,并依次打印,假设移动到的节点为cur。对每一个cur节点都判断cur节点的左
子树中最右节点是否指向cur。
* 1)如果是。让cur节点的左子树中最右节点的right指针指向空,也就是把步骤1调整后再逐渐调整回来,然后打印cur,继续通过cur的right指针移动到下一个节点,重复步骤2。
* 2)如果不是,以cur为头的子树重回步骤1执行。
* 3、步骤2最终移动到null,整个过程结束。
* 通过上述步骤描述我们知道,先序遍历在打印某个节点时,一定是在步骤2开始移动的过程中,而步骤2最初开始的位置一定是子树的
* 最左节点,在通过right指针移动的过程中,我们发现要么是某个节点移动到其右子树上,发生这种情况的时候,左子树和根节点已经
* 打印结束,然后开始右子树的处理过程;要么是某个节点移动到某个上层的节点,发生这种情况的时候,必然是这个上层节点的左子树
* 整体打印完毕,然后开始处理根节点(也就是这个上层节点)和右子树的过程。
* Morris中序遍历的具体实现请参看如下代码中的inOrder方法。
* 从代码可以轻易看出,Morris中序遍历的额外空间复杂度为O(1),只使用了有限几个变量。时间复杂度方面可以这么分析,二叉树的
* 每条边最多经历一次步骤1的调整过程,再最多以历一次步骤3的调回来的过程,所有边的节点个数为N,所以调整和调回的过程,其
* 时间复杂度为O(N),打印所有节点的时间复杂度为O(N)。所以,总的时间复杂度为O(N)。
*
* Morris先序遍历的实现是Morris中序遍历的简单改写。先序遍历的打印时机放在了步骤2所描述的移动过程中,而先序遍历只要把打
* 印时机放在步骤1发生的时候即可。步骤1发生的时候,正在处理以h为头的子树,并且是以h为头的子树首次进入调整过程,此时直接
* 打印h,就可以做到先序打印。
* Morris先序遍历的具体实现请参看如下代码中的preOrder方法。
*
* Morris后序遍历的实现也是Morris中序遍历实现的改写,但包含更复杂的调整过程。总的来说,逻辑很简单,就是依次逆序打印所有
* 节点的左子树的右边界,打印的时机放在步骤2的条件1)被触发的时候,也就是调回去的过程发生的时候。
* Morris后序遍历的具体实现请参看如下代码中的postOrder方法。
Morris中序遍历
Morris中序遍历的步骤如下:
- 设定当前子树的头节点为
h,找到h的左子树中最右边的节点,然后将该节点的right指针指向h,从而形成一种指向上层的路径。 - 接着在左子树中执行同样的操作,直到没有左子树为止。
- 当遍历到一个节点时,检查其左子树的最右边节点的
right指针是否指向当前节点:- 如果是,说明左子树已经遍历完,需解除指向并打印当前节点,然后向右移动。
- 如果不是,说明是第一次遇到此节点,继续向左子树遍历。
- 最终遍历到
null,整个中序遍历结束。
Morris先序遍历
Morris先序遍历和Morris中序遍历类似,但打印时机不同:
- 在设置指向父节点的路径时立即打印当前节点。
- 然后重复Morris中序遍历的操作。
Morris后序遍历
Morris后序遍历稍微复杂一些,打印的时机在回溯过程中逆序打印左子树的右边界:
- 在解开指向上层的路径时,逆序打印左子树的右边界。
- 当左子树被完全遍历后,处理根节点和右子树。
总体上,Morris遍历使用二叉树中的空闲指针形成路径,避免了额外的栈空间。尽管涉及一些额外调整和重新设定指向,但其时间复杂度为O(N),空间复杂度为O(1)。这使得它成为一种高效的二叉树遍历方法。
public class BinaryTreeTraverseGod {
// 中序遍历
public static void inOrder(Node root) {
if (root == null) {
return;
}
Node cur1 = root;
Node cur2 = null;
while (cur1 != null) {
cur2 = cur1.left;
if (cur2 != null) {
// 找到cur1的左子树的最右节点
while (cur2.right != null && cur2.right != cur1) {
cur2 = cur2.right;
}
if (cur2.right == null) {
// 将cur1的左子树的最右节点的右指针指向cur1,然后移动cur1到左孩子节点
cur2.right = cur1;
cur1 = cur1.left;
continue;
} else {
// 恢复树的结构,打印当前节点,并移动到右孩子节点
cur2.right = null;
}
}
// 打印当前节点,并移动到右孩子节点
System.out.print(cur1.data + " ");
cur1 = cur1.right;
}
System.out.println();
}
// 先序遍历
public static void preOrder(Node root) {
if (root == null) {
return;
}
Node cur1 = root;
Node cur2 = null;
while (cur1 != null) {
cur2 = cur1.left;
if (cur2 != null) {
// 找到cur1的左子树的最右节点
while (cur2.right != null && cur2.right != cur1) {
cur2 = cur2.right;
}
if (cur2.right == null) {
// 将cur1的左子树的最右节点的右指针指向cur1,打印当前节点,并移动到左孩子节点
cur2.right = cur1;
System.out.print(cur1.data + " ");
cur1 = cur1.left;
continue;
} else {
// 恢复树的结构
cur2.right = null;
}
} else {
// 如果没有左子树,则直接打印当前节点,并移动到右孩子节点
System.out.print(cur1.data + " ");
}
cur1 = cur1.right;
}
System.out.println();
}
// 后序遍历
public static void postOrder(Node root) {
if (root == null) {
return;
}
Node cur1 = root;
Node cur2 = null;
while (cur1 != null) {
cur2 = cur1.left;
if (cur2 != null) {
// 找到cur1的左子树的最右节点
while (cur2.right != null && cur2.right != cur1) {
cur2 = cur2.right;
}
if (cur2.right == null) {
// 将cur1的左子树的最右节点的右指针指向cur1,并移动到左孩子节点
cur2.right = cur1;
cur1 = cur1.left;
continue;
} else {
// 恢复树的结构,并打印当前节点的左边界节点
cur2.right = null;
printEdge(cur1.left);
}
}
// 移动到右孩子节点
cur1 = cur1.right;
}
// 打印当前节点的右边界节点
printEdge(root);
System.out.println();
}
// 打印边界节点
private static void printEdge(Node root) {
// 反转树的右边界
Node tail = reverseEdge(root);
Node cur = tail;
while (cur != null) {
// 打印节点值,并移动到下一个节点
System.out.print(cur.data + " ");
cur = cur.right;
}
// 恢复树的右边界
reverseEdge(tail);
}
// 反转树的右边界
private static Node reverseEdge(Node from) {
Node pre = null;
Node next = null;
while (from != null) {
next = from.right;
from.right = pre;
pre = from;
from = next;
}
return pre;
}
public static void main(String[] args) {
// 构建二叉树
Node node1 = new Node(2);
Node node2 = new Node(3);
Node node3 = new Node(5);
Node node4 = new Node(7);
Node node5 = new Node(8);
Node node6 = new Node(1);
Node node7 = new Node(3);
node1.left = node2;
node1.right = node3;
node2.left = node4;
node2.right = node5;
node3.left = node6;
node3.right = node7;
// 先序遍历
System.out.print("先序遍历: ");
preOrder(node1);
// 中序遍历
System.out.print("中序遍历: ");
inOrder(node1);
// 后序遍历
System.out.print("后序遍历: ");
postOrder(node1);
}
}
六 在二叉树中找到累加和为指定值的最长路径长度
【题目】
* 给定一棵二叉树的根节点root和一个32位整数sum,二叉树节点值类型为整型,求累加和为sum的最长路径长度。路径是指从某个节点往下,每次最多选择一个孩子节点或者不选所形成的节点链。
* 注:本题不用考虑节点值相加可能溢出的情况。
import java.util.HashMap;
class Node {
int data;
Node left, right;
public Node(int data) {
this.data = data;
left = right = null;
}
}
public class GetMaxLengthOfSpecifiedSumInBinaryTree {
/**
* 获取累加和为指定值的最长路径长度
*
* @param root 根节点
* @param sum 指定的累加和
* @return 最长路径长度
*/
public static int getMaxLength(Node root, int sum) {
// 哈希表,记录累加和及其对应的路径长度
HashMap<Integer, Integer> sumMap = new HashMap<>();
sumMap.put(0, 0); // 初始化,重要,表示累加和为0时的路径长度为0
return preOrder(root, sum, 0, 1, 0, sumMap);
}
/**
* 先序遍历二叉树,查找累加和为指定值的最长路径长度
*
* @param root 当前节点
* @param sum 指定的累加和
* @param preSum 从根节点到当前节点的累加和
* @param level 当前节点的层级
* @param maxLen 最长路径长度
* @param sumMap 哈希表,记录累加和及其对应的路径长度
* @return 最长路径长度
*/
private static int preOrder(Node root, int sum, int preSum, int level, int maxLen,
HashMap<Integer, Integer> sumMap) {
// 如果当前节点为空,直接返回当前的最长路径长度
if (root == null) {
return maxLen;
}
// 计算当前节点的累加和
int curSum = preSum + root.data;
// 如果当前累加和第一次出现,则将其记录到哈希表中
if (!sumMap.containsKey(curSum)) {
sumMap.put(curSum, level);
}
// 如果存在累加和为(curSum - sum)的节点,则更新最长路径长度
if (sumMap.containsKey(curSum - sum)) {
maxLen = Math.max(level - sumMap.get(curSum - sum), maxLen);
}
// 递归遍历左右子节点
maxLen = preOrder(root.left, sum, curSum, level + 1, maxLen, sumMap);
maxLen = preOrder(root.right, sum, curSum, level + 1, maxLen, sumMap);
// 在递归退出后,如果当前累加和对应的路径长度与当前层级相等,说明该路径已经不在有效路径中,从哈希表中移除该累加和
if (level == sumMap.get(curSum)) {
sumMap.remove(curSum);
}
// 返回最长路径长度
return maxLen;
}
public static void main(String[] args) {
// 构建测试二叉树
Node node1 = new Node(2);
Node node2 = new Node(3);
Node node3 = new Node(5);
Node node4 = new Node(7);
Node node5 = new Node(8);
Node node6 = new Node(1);
Node node7 = new Node(3);
node1.left = node2;
node1.right = node3;
node2.left = node4;
node2.right = node5;
node3.left = node6;
node3.right = node7;
// 指定累加和
int targetSum = 8;
// 计算最长路径长度并输出结果
System.out.println("累加和为指定值的最长路径长度是: " + getMaxLength(node1, targetSum));
}
}
解题思路
-
递归先序遍历二叉树:
- 从根节点开始,按照先序遍历的方式递归遍历二叉树,同时传递当前节点的累加和和层级信息。
-
维护累加和:
- 在递归过程中,计算当前节点的累加和,并将其记录到哈希表中。
-
检查指定累加和:
- 对于每个节点,检查当前累加和与指定的累加和之差是否在哈希表中,如果存在,则更新最长路径长度。
-
递归遍历左右子节点:
- 递归遍历当前节点的左右子节点,传递更新后的累加和、层级信息和最长路径长度。
-
状态恢复:
- 在递归退出后,如果当前累加和对应的路径长度与当前层级相等,说明该路径已经不在有效路径中,从哈希表中移除该累加和,以确保正确性。
七 找到二叉树中的最大搜索二叉子树
* 【题目】
* 给定一棵二叉树的根节点root,已知其中所有节点的值都不一样,找到含有节点最多的搜索二叉子树,并返回这棵子树的头节点。
*
* 【要求】
* 如果节点数为N,要求时间复杂度为O(N),额外空间复杂度为O(h),h为二叉树的高度。
*
* 【难度】
* 中等
*
* 【解答】
* 以节点root为根的树中,最大的搜索二叉子树只可能来自以下两种情况。
* 第一种:如果来自root左子树上的最大搜索二叉子树是以root.left为根的;来自root右子树上的最大搜索二叉子树是以
* root.right为头的;root左子树上的最大搜索二叉子树的最大值小于root.data;root右子树上的最大搜索二叉子树的最小值大
* 于root.data,那么以节点root为根的整棵树都是搜索二叉树。
* 第二种:如果不满足第一种情况,说明以节点root为根的树整体不能连成搜索二叉树。这种情况下,以root为根的树上的最大搜索二
* 叉子树是来自root的左子树上的最大搜索二叉子树和来自root的右子树上的最大搜索二叉子树之间,节点数较多的那个。
*
* 通过以上分析,求解的具体过程如下:
* 1、整体过程是二叉树的后序遍历。
* 2、遍历到当前节点记为cur时,先遍历cur的左子树收集4个信息,分别是左子树上最大搜索二叉子树的根节点(lBST)、节点数
* (lSize)、最小值(lMin)和最大值(lMax)。再遍历cur的右子树收集4个信息,分别是右子树上最大搜索二叉子树的根节点
* (rBST)、节点数(rSize)、最小值(rMin)和最大值(rMax)。
* 3、根据步骤2所收集的信息,判断是否满足第一种情况,如果满足第一种情况,就返回cur节点,如果满足第二种情况,就返回lBST
* 和rBST中较大的一个。
* 4、可以使用全局变量的方式实现步骤2中收集节点数、最小值和最大值的问题。
*
* 找到最大搜索二叉子树的具体过程请参看如下代码中的getMaxSubBST方法。
```java
public class FindMaxSubBST {
/**
* 获取包含最大搜索二叉子树的根节点
*
* @param root 树的根节点
* @return 包含最大搜索二叉子树的根节点
*/
public static Node getMaxSubBST(Node root) {
int[] record = new int[3]; // 用于记录当前子树的信息,包括节点数、最小值、最大值
return postOrder(root, record); // 调用后序遍历函数
}
/**
* 后序遍历二叉树,获取包含最大搜索二叉子树的根节点
*
* @param root 当前子树的根节点
* @param record 记录当前子树的信息的数组,包括节点数、最小值、最大值
* @return 包含最大搜索二叉子树的根节点
*/
private static Node postOrder(Node root, int[] record) {
if (root == null) { // 当前节点为空,返回空节点
record[0] = 0; // 节点数置为0
record[1] = Integer.MAX_VALUE; // 最小值置为最大值
record[2] = Integer.MIN_VALUE; // 最大值置为最小值
return null;
}
int value = root.data; // 当前节点的值
Node left = root.left; // 当前节点的左子节点
Node right = root.right; // 当前节点的右子节点
Node lBST = postOrder(left, record); // 递归处理左子树
int lSize = record[0]; // 左子树节点数
int lMin = record[1]; // 左子树最小值
int lMax = record[2]; // 左子树最大值
Node rBST = postOrder(right, record); // 递归处理右子树
int rSize = record[0]; // 右子树节点数
int rMin = record[1]; // 右子树最小值
int rMax = record[2]; // 右子树最大值
record[1] = Math.min(lMin, value); // 更新当前子树的最小值
record[2] = Math.max(rMax, value); // 更新当前子树的最大值
if (left == lBST && right == rBST && lMax < value && value < rMin) {
// 如果当前节点满足条件成为搜索二叉子树的根节点
record[0] = lSize + rSize + 1; // 更新当前子树的节点数
return root; // 返回当前节点作为搜索二叉子树的根节点
}
record[0] = Math.max(lSize, rSize); // 更新当前子树的节点数为左右子树中较大的节点数
return lSize > rSize ? lBST : rBST; // 返回节点数较多的搜索二叉子树的根节点
}
/**
* 测试函数,用于创建二叉树并打印包含最大搜索二叉子树的根节点
*/
public static void main(String[] args) {
// 创建测试二叉树
Node node1 = new Node(5);
Node node2 = new Node(2);
Node node3 = new Node(8);
Node node4 = new Node(1);
Node node5 = new Node(3);
Node node6 = new Node(7);
Node node7 = new Node(9);
node1.left = node2;
node1.right = node3;
node2.left = node4;
node2.right = node5;
node3.left = node6;
node3.right = node7;
// 获取包含最大搜索二叉子树的根节点并打印
Node node = getMaxSubBST(node1);
print(node);
}
}
```八 找到二叉树中符合搜索二叉树条件的最大拓扑结构
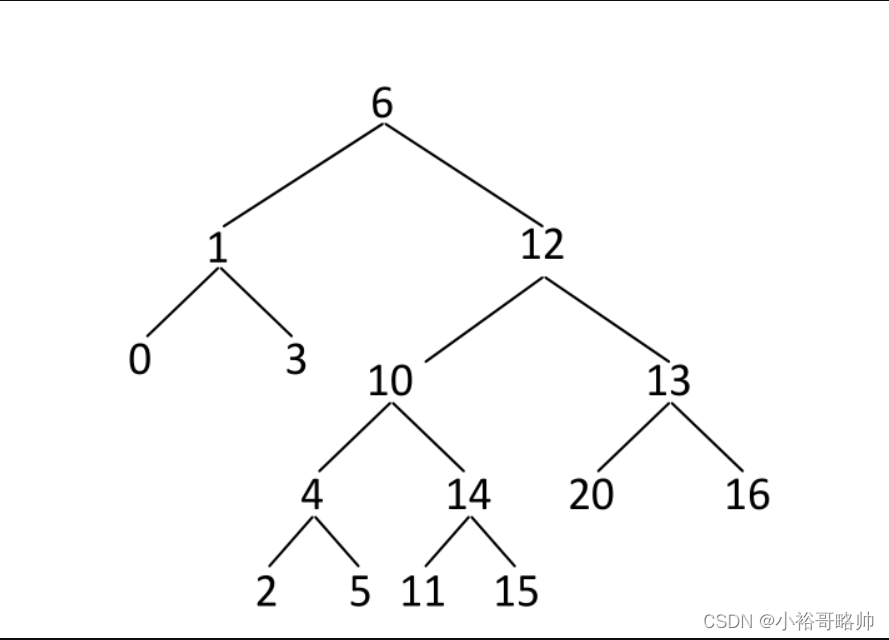
【题目】给定一棵二叉树的头节点head,已知所有节点的值都不一样,返回其中最大的且符合搜索二叉树条件的最大拓扑结构的大小。例如,二叉树如图3-19所示。
其中最大的且符合搜索二叉树条件的拓扑结构如图3-20所示。
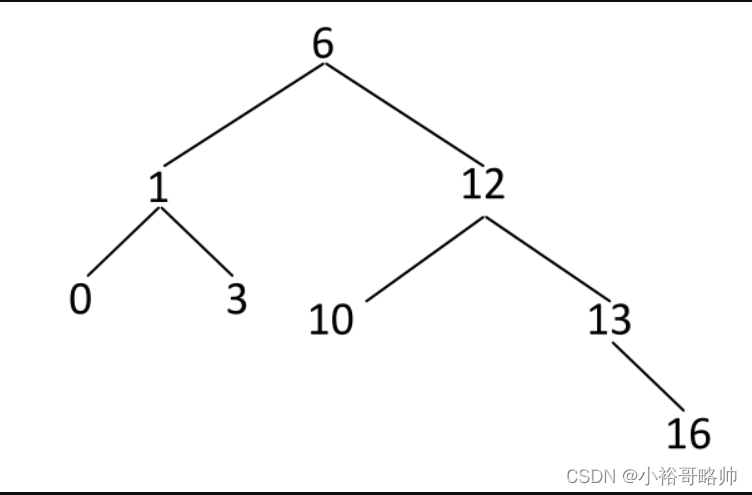 这个拓扑结构节点数为8,所以返回8。
这个拓扑结构节点数为8,所以返回8。
方法一
public int bstTopoSize1(Node head)
{
// 若头节点为空,则返回最大拓扑结构大小为0
if (head == null) {
return 0;
}
// 计算以当前节点为根节点的最大拓扑结构大小
int max = maxTopo(head, head);
// 分别计算左子树和右子树的最大拓扑结构大小,取最大值
max = Math.max(bstTopoSize1(head.left), max);
max = Math.max(bstTopoSize1(head.right), max);
return max;
}
// 计算以当前节点h为根节点,包含节点n的最大拓扑结构大小
private int maxTopo(Node h, Node n) {
// 若节点h和n都不为空,并且以h为根节点的子树是二叉搜索树,则计算包含n的最大拓扑结构大小
if (h != null && n != null && isBSTNode(h, n, n.value)) {
return maxTopo(h, n.left) + maxTopo(h, n.right) + 1;
}
return 0; // 否则返回0
}
// 判断节点n是否为以节点h为根节点的搜索二叉树中的节点
private boolean isBSTNode(Node h, Node n, int value) {
// 若节点h为空,则返回false
if (h == null) {
return false;
}
// 若节点h等于节点n,则返回true
if (h == n) {
return true;
}
// 递归判断n在左子树或右子树
return isBSTNode(h.value > value ? h.left : h.right, n, value);
}对于方法一的时间复杂度分析,我们把所有的子树(N 个)都找了一次最大拓扑,每找一次,所考查的节点数都可能是O(N)个节点,所以方法一的时间复杂度为O(n*n)。
解法二:
public static class Record
{
public int l; // 表示左子树的最大拓扑结构的数量
public int r; // 表示右子树的最大拓扑结构的数量
public Record(int l, int r) {
super();
this.l = l;
this.r = r;
}
}
public int bstTopoSize2(Node head)
{
// 使用 Map 存储节点与记录的映射关系
Map<Node, Record> map = new HashMap<Node, Record>();
return posOrder(head, map);
}
private int posOrder(Node h, Map<Node, Record> map) {
if (h == null) {
return 0;
}
// 分别递归计算左右子树的最大拓扑结构数量
int ls = posOrder(h.left, map);
int rs = posOrder(h.right, map);
// 更新 Map 中左子树和右子树的信息
modifyMap(h.left, h.value, map, true);
modifyMap(h.right, h.value, map, false);
// 获取左子树和右子树的记录
Record lr = map.get(h.left);
Record rr = map.get(h.right);
// 计算当前节点的最大拓扑结构数量
int lbst = lr == null ? 0 : lr.l + lr.r + 1;
int rbst = rr == null ? 0 : rr.l + rr.r + 1;
map.put(h, new Record(lbst, rbst));
// 返回当前节点的最大拓扑结构数量
return Math.max(lbst + rbst + 1, Math.max(ls, rs));
}
private int modifyMap(Node n, int v, Map<Node, Record> m, boolean isLeft) {
if (n == null || (!m.containsKey(n))) {
return 0;
}
Record r = m.get(n);
// 如果当前节点需要删除,则更新数量并返回
if ((isLeft && n.value > v) || (!isLeft && n.value < v)) {
m.remove(n);
return r.l + r.r + 1;
}
else {
// 否则递归更新子树信息
int minus = modifyMap(isLeft ? n.right : n.left, v, m, isLeft);
if (isLeft) {
r.r = r.r - minus;
} else {
r.l = r.l - minus;
}
m.put(n, r);
return minus;
}
}这种解法是基于后序遍历的思想来求解最大拓扑结构的大小。具体思路如下:
1. 从根节点开始递归地后序遍历整棵二叉树;
2. 在后序遍历的过程中,先分别递归计算左子树和右子树的最大拓扑结构大小;
3. 对于当前节点,先更新Map中左子树和右子树的信息,然后计算包含当前节点的最大拓扑结构大小;
4. 根据当前节点以及左右子树的信息,在Map中更新当前节点的记录;
5. 最后返回整棵二叉树中最大的拓扑结构大小,即左子树拓扑结构大小加右子树拓扑结构大小再加1的最大值。
在这个过程中,通过递归地更新Map中的记录信息,确保了在整个后序遍历的过程中能够动态地计算每个节点对应的左子树和右子树的拓扑结构大小。同时,根据搜索二叉树的性质,通过移除不符合条件的节点并更新数量,来保证最终计算得到的拓扑结构一定是合法的。
这种解法利用了后序遍历的特点,通过动态维护Map中节点的记录信息,能够高效地计算出最大符合搜索二叉树条件的拓扑结构大小。
希望这个具体的思路能够帮助你更好地理解这种解法的实现。如果有任何疑问,欢迎继续提出。
九 二叉树的按层打印与ZigZag打印
给定一棵二叉树的头节点head,分别实现按层和Z igZag打印二叉树的函数。例如,二叉树如图3-29所示。
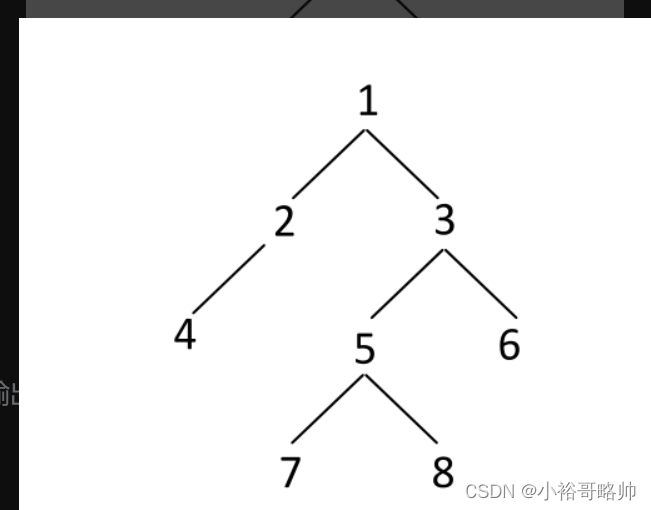
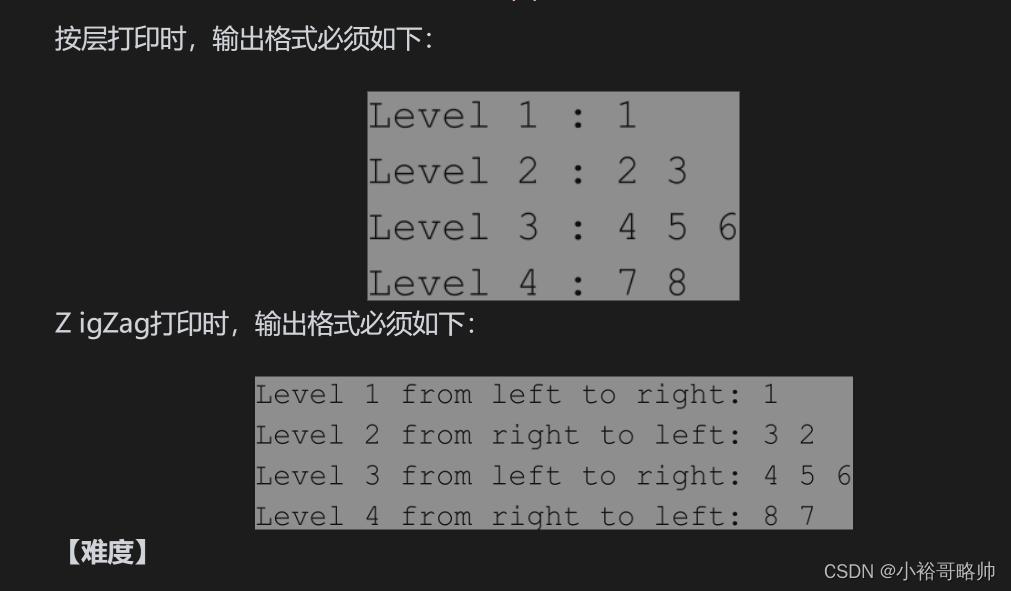
解法:
// 按层打印二叉树
public void printByLevel(Node head) {
if (head == null) {
return;
}
Queue<Node> queue = new LinkedList<>(); // 创建队列用于层序遍历
int level = 1; // 初始化层数为1
Node last = head; // 当前层的最右节点
Node nlast = null; // 下一层的最右节点
queue.offer(head);
System.out.println("Level " + (level++) + ":"); // 打印第一层
while (!queue.isEmpty()) {
head = queue.poll(); // 出队节点进行打印
System.out.print(head.value + " ");
if (head.left != null) {
queue.offer(head.left); // 左孩子入队
nlast = head.left; // 更新下一层最右节点
}
if (head.right != null) {
queue.offer(head.right); // 右孩子入队
nlast = head.right; // 更新下一层最右节点
}
if (head == last && !queue.isEmpty()) { // 当遍历到当前层的最后一个节点时,打印下一层,并更新节点
System.out.println("\nLevel " + (level++) + ":");
last = nlast; // 更新当前层最右节点
}
}
System.out.println();
}
// ZigZag打印二叉树
public void printByZigZag(Node head) {
if (head == null) {
return;
}
Deque<Node> deque = new LinkedList<>(); // 创建双端队列用于ZigZag打印
int level = 1; // 初始化层数为1
boolean lr = true; // 标记当前打印方向
Node last = head; // 当前层的最右节点
Node nLast = null; // 下一层的最右节点
deque.offerFirst(head);
printLevelAndOrientation(level++, lr); // 打印第一层及方向
while (!deque.isEmpty()) {
if (lr) {
head = deque.pollFirst(); // 从队头取出节点
if (head.left != null) {
nLast = nLast == null ? head.left : nLast; // 更新下一层最右节点
deque.offerLast(head.left); // 左孩子入队(队尾)
}
if (head.right != null) {
nLast = nLast == null ? head.right : nLast; // 更新下一层最右节点
deque.offerLast(head.right); // 右孩子入队(队尾)
}
} else {
head = deque.pollLast(); // 从队尾取出节点
if (head.right != null) {
nLast = nLast == null ? head.right : nLast; // 更新下一层最右节点
deque.offerFirst(head.right); // 右孩子入队(队头)
}
if (head.left != null) {
nLast = nLast == null ? head.left : nLast; // 更新下一层最右节点
deque.offerFirst(head.left); // 左孩子入队(队头)
}
}
System.out.print(head.value + " ");
if (head == last && !deque.isEmpty()) {
lr = !lr; // 改变打印方向
last = nLast; // 更新当前层最右节点
nLast = null; // 重置下一层最右节点
System.out.println();
printLevelAndOrientation(level++, lr); // 打印下一层及方向
}
}
System.out.println();
}
// 打印层号和打印方向
private void printLevelAndOrientation(int level, boolean lr) {
System.out.println("Level " + level + " from:");
System.out.println(lr ? "left to right" : "right to left");
}解题思路:
- 按层打印二叉树的思路是利用队列结构实现层序遍历,每次遍历一层节点,并按顺序打印节点值。
- ZigZag 打印二叉树的思路是利用双端队列结构实现,根据标记变量控制打印方向,交替从队头和队尾取出节点进行打印,并按顺序更新下一层节点入队顺序。
十 调整搜索二叉树中两个错误的节点
【题目】
一棵二叉树原本是搜索二叉树,但是其中有两个节点调换了位置,使得这棵二叉树不再是搜索二叉树,请找到这两个错误节点并返回。已知二叉树中所有节点的值都不一样,给定二叉树的头节点head,返回一个长度为2的二叉树节点类型的数组errs,errs[0]表示一个错误节点,errs[1]表示另一个错误节点。
如果在中序遍历时节点值出现了两次降序,第一个错误的节点为第一次降序时较大的节点,第二个错误的节点为第二次降序时较小的节点。
public Node[] getTwoErrNodes(Node head)
{
Node[] errs = new Node[2]; // 存放错误节点的数组
if (head == null) {
return errs;
}
Stack<Node> stack = new Stack<>(); // 辅助栈存放节点
Node pre = null; // 用于记录中序遍历中当前节点的前一个节点
while (!stack.isEmpty() || head != null) {
if (head != null) {
stack.push(head);
head = head.left; // 一直向左走,直到左子树为空
} else {
head = stack.pop(); // 当前节点为空时,弹出栈顶节点进行处理
// 中序遍历中如果发现 pre 的值比当前节点值大,说明存在错误节点
if (pre != null && pre.value > head.value) {
errs[0] = errs[0] == null ? pre : errs[0]; // 第一个错误节点为中序遍历中第一个比前一个节点值大的节点
errs[1] = head; // 第二个错误节点为中序遍历中当前节点
}
pre = head;
head = head.right; // 处理当前节点的右子树
}
}
return errs;
}- 创建一个存放错误节点的数组 errs,初始值为 null。
- 利用栈实现中序遍历,栈中存放节点,pre 用于记录中序遍历中当前节点的前一个节点。
- 如果当前节点不为空,将其入栈并继续向左走;
- 如果当前节点为空,弹出栈顶节点进行处理:
- 若 pre 的值比当前节点值大,则存在错误节点,将错误节点加入 errs 数组;
- 更新 pre 为当前节点,处理当前节点的右子树。
- 重复以上步骤直至遍历完整棵树,返回 errs 数组。
十一 判断t1树是否包含t2树全部的拓扑结构
【题目】给定彼此独立的两棵树头节点分别为t1和t2,判断t1树是否包含t2树全部的拓扑结构。例如,如图3-34所示的t1树和如图3-35所示的t2树。
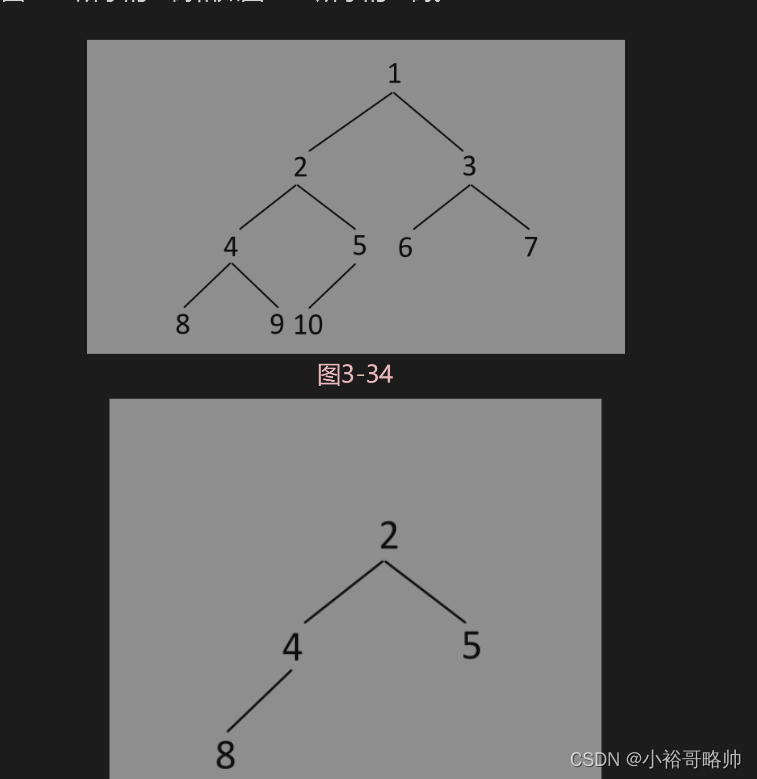
t1树包含t2树全部的拓扑结构,所以返回true。
public static boolean contains(Node t1, Node t2) {
if (t2 == null) {
return true; // t2 为空,说明 t2 已经遍历完成,t1 包含 t2 的所有拓扑结构
}
if (t1 == null) {
return false; // t1 为空,无法包含 t2 的拓扑结构
}
// 递归检查 t1 和 t2 是否为相同的子树,或者 t1 的左子树或右子树是否包含 t2
return check(t1, t2) || contains(t1.left, t2) || contains(t1.right, t2);
}
private static boolean check(Node h, Node t2) {
// 递归终止条件,如果 t2 为空,说明 t2 已经遍历完成,返回 true
if (t2 == null) {
return true;
}
// 如果 h 为空或 h 的值不等于 t2 的值,说明 t1 不包含 t2 的拓扑结构,返回 false
if (h == null || h.value != t2.value) {
return false;
}
// 递归检查 h 的左子树和 t2 的左子树,以及 h 的右子树和 t2 的右子树是否相同
return check(h.left, t2.left) && check(h.right, t2.right);
}- contains 方法用于判断树 t1 是否包含树 t2 的全部拓扑结构。
- 如果 t2 为空,说明 t2 已经遍历完成,返回 true,表示 t1 包含 t2 的所有拓扑结构。
- 如果 t1 为空,说明 t1 无法包含 t2 的拓扑结构,返回 false。
- 递归检查 t1 和 t2 是否为相同的子树,或者 t1 的左子树或右子树是否包含 t2。
check 方法用于递归检查两棵树是否相同:
- 如果 t2 为空时,说明 t2 已经遍历完成,返回 true。
2. 如果 h 为空或 h 的值不等于 t2 的值,说明 t1 不包含 t2 的拓扑结构,返回 false。
3. 递归检查 h 的左子树和 t2 的左子树,以及 h 的右子树和 t2 的右子树是否相同。
十二 判断t1树中是否有与t2树拓扑结构完全相同的子树
【题目】给定彼此独立的两棵树头节点分别为t1和t2,判断t1中是否有与t2树拓扑结构完全相同的子树。
如果t1的节点数为N,t2的节点数为M,则本题最优解是时间复杂度为O(N+M)的方法。首先简单介绍一个时间复杂度为O(N×M)的方法,对于t1的每棵子树,都去判断是否与t2树的拓扑结构完全一样,这个过程的时间复杂度为O(M),t1的子树一共有N棵,所以时间复杂度为O(N×M),
class TreeNode {
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val) {
this.val = val;
}
}
public boolean hasSameStructure(TreeNode t1, TreeNode t2) {
if (t1 == null) {
return false; // t1 为空,无法包含与 t2 相同的拓扑结构
}
if (isSameStructure(t1, t2)) {
return true; // 当前子树与 t2 拓扑结构完全相同
}
// 继续检查左右子树是否包含与 t2 相同的子树
return hasSameStructure(t1.left, t2) || hasSameStructure(t1.right, t2);
}
public boolean isSameStructure(TreeNode t1, TreeNode t2) {
if (t2 == null) {
return true;
}
if (t1 == null || t1.val != t2.val) {
return false;
}
return isSameStructure(t1.left, t2.left) && isSameStructure(t1.right, t2.right);
}public boolean isSubtree(Node t1, Node t2) {
// 将 t1 和 t2 序列化成字符串
String t1Str = serialByPre(t1);
String t2Str = serialByPre(t2);
// 调用 KMP 算法查找 t2Str 在 t1Str 中的位置
return getIndexOf(t1Str, t2Str) != -1;
}
private String serialByPre(Node head) {
// 序列化树到字符串
if (head == null) {
return "#!";
}
// 将当前节点的值添加到字符串中
String res = head.value + "!";
// 递归序列化左子树
res += serialByPre(head.left);
// 递归序列化右子树
res += serialByPre(head.right);
// 返回序列化后的字符串
return res;
}
private int getIndexOf(String s, String m) {
// KMP 算法查找字符串 m 在 s 中的位置
if (s == null || m == null || m.length() < 1 || s.length() < m.length()) {
return -1;
}
char[] ss = s.toCharArray();
char[] ms = m.toCharArray();
int si = 0; // s 的索引
int mi = 0; // m 的索引
int[] next = getNextArray(ms); // 获取模式串 m 的 next 数组
while (si < ss.length && mi < ms.length) {
if (ss[si] == ms[mi]) { // 当前字符匹配,同时移动 si 和 mi
si++;
mi++;
} else if (next[mi] == -1) { // 没有前缀匹配,si 移动到下一个字符
si++;
} else { // 有前缀匹配,mi 移动到 next[mi]
mi = next[mi];
}
}
// 如果mi 等于 ms.length 时,说明模式串 m 已经完全匹配,返回 si-mi,即匹配位置的起始索引;否则返回 -1,表示没有找到完全匹配的子串。
return mi == ms.length ? si - mi : -1;
}
private int[] getNextArray(char[] ms) {
// 构建模式串的 next 数组
if (ms.length == 1) {
return new int[]{-1};
}
int[] next = new int[ms.length];
next[0] = -1;
next[1] = 0;
int pos = 2; // 当前计算的位置
int cn = 0; // 最长前缀匹配长度
// 根据 next 数组规则计算每个位置
while (pos < next.length) {
if (ms[pos - 1] == ms[cn]) {
next[pos++] = ++cn;
} else if (cn > 0) {
cn = next[cn];
} else {
next[pos++] = 0;
}
}
// 返回构建好的 next 数组
return next;
}以上代码实现了对树的序列化和 KMP 算法的应用,通过对树进行先序序列化为字符串,然后在字符串中搜索与目标子树拓扑结构相同的子串。
十三 判断二叉树是否为平衡二叉树
【题目】平衡二叉树的性质为:要么是一棵空树,要么任何一个节点的左右子树高度差的绝对值不超过1。给定一棵二叉树的头节点head,判断这棵二叉树是否为平衡二叉树。
【要求】如果二叉树的节点数为N,则要求时间复杂度为O(N)。
要判断一棵二叉树是否为平衡二叉树,可以设计一个递归函数来判断每个节点的左右子树的高度差是否不超过1,并且递归地检查每个子树也满足这个条件。具体步骤如下:
- 设计一个返回值为节点高度的递归函数 getHeight(Node node),用于计算以该节点为根的子树的高度。
- 在递归函数中,首先处理递归终止条件,即节点为空时返回高度为0。
- 递归计算左子树和右子树的高度,并分别赋值给 leftHeight 和 rightHeight。
- 判断左右子树的高度差的绝对值是否大于1,如果大于1则返回-1表示不是平衡二叉树。
- 返回左右子树的最大高度加1作为当前节点的高度。
- 在主函数中,调用递归函数 getHeight() 来判断每个节点是否满足平衡二叉树的条件。
class TreeNode {
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val) {
this.val = val;
}
}
public boolean isBalanced(TreeNode root) {
return getHeight(root) != -1;
}
private int getHeight(TreeNode node) {
if (node == null) {
return 0;
}
// 递归计算左子树高度
int leftHeight = getHeight(node.left);
if (leftHeight == -1) {
return -1; // 左子树不平衡,直接返回-1
}
// 递归计算右子树高度
int rightHeight = getHeight(node.right);
if (rightHeight == -1) {
return -1; // 右子树不平衡,直接返回-1
}
// 判断当前节点的左右子树高度差是否超过1
if (Math.abs(leftHeight - rightHeight) > 1) {
return -1; // 高度差超过1,不是平衡二叉树,返回-1
}
// 返回当前节点的高度
return Math.max(leftHeight, rightHeight) + 1;
}十四 根据后序数组重建搜索二叉树
【题目】
给定一个整型数组arr,已知其中没有重复值,判断arr是否可能是节点值类型为整型的搜索二叉树后序遍历的结果。
进阶问题:如果整型数组 arr 中没有重复值,且已知是一棵搜索二叉树的后序遍历结果,通过数组arr重构二叉树。
叉树的后序遍历为先左、再右、最后根的顺序,所以,如果一个数组是二叉树后序遍历的结果,那么头节点的值一定会是数组的最后一个元素。根据搜索二叉树的性质,比后序数组最后一个元素值小的数组会在数组的左边,比数组最后一个元素值大的数组会在数组的右边。比如,arr=[2,1,3,6,5,7,4],比 4 小的部分为[2,1,3],比 4 大的部分为[6,5,7]。如果不满足这种情况,则说明这个数组一定不可能是搜索二叉树后序遍历的结果。接下来,数组划分成左边数组和右边数组,相当于二叉树分出了左子树和右子树,只要递归地进行如上判断即可
进阶问题的分析与原问题同理,一棵树的后序数组中最后一个值为二叉树头节点的值,数组左部分都比头节点的值小,用来生成头节点的左子树,剩下的部分用来生成右子树。
public boolean isPostArray(int[] arr) {
// 判断给定的整型数组arr是否可能是搜索二叉树的后序遍历结果
if (arr == null || arr.length == 0) {
return false;
}
// 调用isPost方法进行递归判断
return isPost(arr, 0, arr.length - 1);
}
private boolean isPost(int[] arr, int start, int end) {
// 递归判断后序遍历数组是否符合搜索二叉树的性质
if (start == end) {
return true;
}
int less = -1; // 记录比根节点值小的最后一个节点的索引
int more = end; // 记录比根节点值大的最后一个节点的索引
for (int i = start; i < end; i++) {
if (arr[end] > arr[i]) {
less = i;
} else {
more = more == end ? i : more;
}
// 根节点不存在左子树的情况
if (less == -1 || more == end) {
return isPost(arr, start, end - 1);
}
// 左右子树之间应该紧密相邻
if (less != more - 1) {
return false;
}
}
// 递归判断左右子树是否满足搜索二叉树的性质
return isPost(arr, start, less) && isPost(arr, more, end - 1);
}
public Node posArrayToBST(int[] posArr) {
// 根据后序遍历数组重构搜索二叉树
if (posArr == null) {
return null;
}
// 调用posToBST方法进行递归构建二叉树
return posToBST(posArr, 0, posArr.length - 1);
}
private Node posToBST(int[] posArr, int start, int end) {
// 递归构建搜索二叉树
if (start > end) {
return null;
}
// 根据后序遍历的最后一个节点创建根节点
Node head = new Node(posArr[end]);
int less = -1; // 记录比根节点值小的最后一个节点的索引
int more = end; // 记录比根节点值大的最后一个节点的索引
for (int i = start; i < end; i++) {
if (posArr[end] > posArr[i]) {
less = i;
} else {
more = more == end ? i : more;
}
}
// 递归构建左右子树
head.left = posToBST(posArr, start, less);
head.right = posToBST(posArr, more, end - 1);
return head;
}解题思路:
- isPostArray方法:判断给定的整型数组arr是否可能是搜索二叉树的后序遍历结果。方法首先判断数组arr是否为空,然后调用isPost方法进行递归判断。
- isPost方法:递归地判断后序遍历数组是否符合搜索二叉树的性质,即左子树节点值小于根节点值,右子树节点值大于根节点值。通过遍历寻找左子树和右子树的分界点,然后递归检查子树是否满足性质。
- posArrayToBST方法:根据后序遍历数组重构搜索二叉树。方法首先判断数组posArr是否为空,然后调用posToBST方法递归构建整棵搜索二叉树。
- posToBST方法:根据后序遍历数组构建搜索二叉树。递归地找到根节点、左子树和右子树,构建整棵二叉树结构。
十五 判断一棵二叉树是否为搜索二叉树和完全二叉树
【题目】给定二叉树的一个头节点head,已知其中没有重复值的节点,实现两个函数分别判断这棵二叉树是否为搜索二叉树和完全二叉树。
-
判断搜索二叉树(BST):
考虑BST的性质,对于每个节点,它的左子树上的所有节点都小于它,右子树上的所有节点都大于它。因此,可以通过中序遍历二叉树,并保持前一个节点的值,确保中序遍历得到的节点值是有序递增的。如果满足这个条件,则是BST。 -
判断完全二叉树(Complete Binary Tree):
完全二叉树的定义是除了最后一层外,所有层的节点个数都是满的,最后一层的节点都靠左排列。可以利用层次遍历(BFS)二叉树,并记录是否遇到空节点。如果在遇到空节点后,后面仍有非空节点出现,则不是完全二叉树。
import java.util.*;
// 定义二叉树节点
class TreeNode {
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val) {
this.val = val;
}
}
public class Solution {
// 判断是否为搜索二叉树
public boolean isBST(TreeNode root) {
if (root == null) {
return true;
}
List<Integer> inorder = new ArrayList<>();
inOrder(root, inorder);
// 检查中序遍历的节点值是否递增
for (int i = 1; i < inorder.size(); i++) {
if (inorder.get(i) <= inorder.get(i - 1)) {
return false;
}
}
return true;
}
// 中序遍历二叉树并将节点值存储在列表中
private void inOrder(TreeNode node, List<Integer> list) {
if (node == null) {
return;
}
inOrder(node.left, list);
list.add(node.val);
inOrder(node.right, list);
}
// 判断是否为完全二叉树
public boolean isCompleteTree(TreeNode root) {
if (root == null) {
return true;
}
Queue<TreeNode> queue = new LinkedList<>();
boolean flag = false; // 标记是否遇到空节点
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
if (node == null) {
flag = true;
} else {
if (flag) {
return false;
}
queue.offer(node.left);
queue.offer(node.right);
}
}
return true;
}
}
十六 通过有序数组生成平衡搜索二叉树
【题目】给定一个有序数组sortArr,已知其中没有重复值,用这个有序数组生成一棵平衡搜索二叉树,并且该搜索二叉树中序遍历的结果与sortArr一致。
【解答】本题的递归过程比较简单,用有序数组中最中间的数生成搜索二叉树的头节点,然后用这个数左边的数生成左子树,用右边的数生成右子树即可。全部过程请参看如下代码中的generateTree方法。
public class Solution {
// 生成平衡搜索二叉树的入口方法,接受一个有序数组作为输入
public Node generateTree(int[] sortArr) {
if (sortArr == null) {
return null;
}
return generate(sortArr, 0, sortArr.length - 1);
}
// 递归生成平衡搜索二叉树的方法,根据有序数组生成平衡二叉树的节点
private Node generate(int[] sortArr, int start, int end) {
// 若起始位置大于结束位置,说明已经没有元素需要处理,返回null
if (start > end) {
return null;
}
// 计算当前子数组的中间位置
int mid = (start + end) / 2;
// 创建当前节点,值为中间位置的元素值
Node head = new Node(sortArr[mid]);
// 递归生成左子树,范围从start到mid-1
head.left = generate(sortArr, start, mid - 1);
// 递归生成右子树,范围从mid+1到end
head.right = generate(sortArr, mid + 1, end);
return head; // 返回当前节点作为根节点
}
}十七 在二叉树中找到一个节点的后继节点
【题目】
现在有一种新的二叉树节点类型如下:
该结构比普通二叉树节点结构多了一个指向父节点的parent指针。假设有一棵Node类型的节点组成的二叉树,树中每个节点的parent指针都正确地指向自己的父节点,头节点的parent指向 null。只给出一个在二叉树中的某个节点 node,请实现返回 node 的后继节点的函数。在二叉树的中序遍历的序列中,node的下一个节点叫作node的后继节点。例如,如图3-40所示的二叉树。

中序遍历的结果为:1,2,3,4,5,6,7,8,9,10
所以节点1的后继为节点2,节点2的后继为节点3,……,节点10的后继为null。
class Node {
public int value;
public Node left;
public Node right;
public Node parent;
public Node() {
}
public Node(int value) {
this.value = value;
}
}
public class Solution {
// 主函数,用于寻找给定节点的中序遍历后继节点
public Node getNextNode(Node node) {
if (node == null) {
return node;
}
if (node.right != null) { // 如果节点有右子树,则返回右子树中最左侧的节点
return getLeftMost(node.right);
} else { // 如果节点没有右子树
Node parent = node.parent;
while (parent != null && parent.left != node) { // 向上查找直到节点是父节点的左孩子
node = parent;
parent = node.parent;
}
return parent; // 返回找到的父节点
}
}
// 辅助函数,用于找到节点及其子树中最左侧的节点
private Node getLeftMost(Node node) {
if (node == null) {
return node;
}
while (node.left != null) {
node = node.left;
}
return node;
}
}- 如果给定节点有右子树,那么后继节点是其右子树中最左侧的节点,即右子树中最小的节点;
- 如果给定节点没有右子树,那么需要向上查找,直到找到一个节点是其父节点的左孩子,那么该父节点就是所求节点的后继节点。
十八 在二叉树中找到两个节点的最近公共祖先
* 【题目】
* 给定一棵二叉树的头节点head,以及这棵树中的两个节点o1和o2,请返回o1和o2的最近公共祖先节点。
*
* 【难度】
* 原问题:简单
package live.every.day.ProgrammingDesign.CodingInterviewGuide.BinaryTree;
/**
* 在二叉树中找到两个节点的最近公共祖先
*
* 【题目】
* 给定一棵二叉树的头节点head,以及这棵树中的两个节点o1和o2,请返回o1和o2的最近公共祖先节点。
*
* 【难度】
* 原问题:简单
*
* 【解答】
* 先来解决原问题。后序遍历二叉树,假设遍历到的当前节点为cur。因为是后序遍历,所以先处理cur的两棵子树。假设处理cur左子
* 树时返回节点为left,处理右子树时返回right。
* 1、如果发现cur等于null,或者o1、o2,则返回cur。
* 2、如果left和right都为空,说明cur整棵子树上没有发现过o1或o2,返回null。
* 3、如果left和right都不为空,说明左子树上发现过o1或o2,右子树上也发现过o2或o1,说明o1向上与o2向上的过程中,首次在
* cur相遇,返回cur。
* 4、如果left和right有一个为空,另一个不为空,假设不为空的那个记为node,此时node到底是什么?有两种可能,要么node是
* o1或o2中的一个,要么node已经是o1和o2的最近公共祖先。不管是哪种情况,直接返回node即可。
*
* 找到两个节点最近公共祖先的详细过程请参看如下代码中的getLowestAncestor1方法。
*
* @author Created by LiveEveryDay
*/
public class FindLowestCommonAncestorInBinaryTree1 {
public static class Node {
public int data;
public Node left;
public Node right;
public Node(int data) {
this.data = data;
}
}
public static Node getLowestAncestor1(Node root, Node n1, Node n2) {
if (root == null || root == n1 || root == n2) {
return root;
}
Node left = getLowestAncestor1(root.left, n1, n2);
Node right = getLowestAncestor1(root.right, n1, n2);
if (left != null && right != null) {
return root;
}
return left != null ? left : right;
}
public static void main(String[] args) {
Node node1 = new Node(2);
Node node2 = new Node(3);
Node node3 = new Node(5);
Node node4 = new Node(7);
Node node5 = new Node(8);
Node node6 = new Node(1);
Node node7 = new Node(3);
node1.left = node2;
node1.right = node3;
node2.left = node4;
node2.right = node5;
node3.left = node6;
node3.right = node7;
Node n = getLowestAncestor1(node1, node3, node7);
System.out.printf("The lowest common ancestor is: %d", n.data);
}
}
// ------ Output ------
/*
The lowest common ancestor is: 5
*/进阶:如果查询两个节点的最近公共祖先的操作十分频繁,想法让单条查询的查询时间减少。
/**
* 在二叉树中找到两个节点的最近公共祖先
*
* 【题目】
* 给定一棵二叉树的头节点head,以及这棵树中的两个节点o1和o2,请返回o1和o2的最近公共祖先节点。
* 进阶:如果查询两个节点的最近公共祖先的操作十分频繁,想法让单条查询的查询时间减少。
*
* 【难度】
* 进阶问题:中等
*
* 【解答】
* 进阶问题其实是先花较大的力气建立一种记录,以后执行每次查询时就可以完全根据记录进行查询。记录的方式可以有很多种,本文提
* 供两种记录结构供读者参考,两种记录各有优缺点。
*
* 结构一:建立二叉树中每个节点对应的父节点信息,是一张哈希表。
* key代表二叉树中的一个节点,value代表其对应的父节点。只用遍历一次二叉树,这张表就可以创建好,以后每次查询都可以根据这
* 张哈希表进行。
* 假设想查节点4和节点8的最近公共祖先,方法是使用如上的哈希表,把包括节点4在内的所有节点4的祖先节点放进另一个哈希表A
* 中,A表示节点4到头节点这条路径上所有节点的集合。所以A={节点4,节点2,节点1}。然后使用如上的哈希表,从节点8开始往
* 上逐渐移动到头节点。首先是节点8,发现不在A中,然后是节点7,发现也不在A中,接下来是节点3,依然不在A中,最后是节点1,
* 发现在A中,那么节点1就是节点4和节点8的最近公共祖先。只要在移动过程中发现某个节点在A中,这个节点就是要求的公共祖先节
* 点。
* 结构一的具体实现请参看如下代码中Record1类的实现,构造函数是创建记录过程,方法query是查询操作。
* 很明显,结构一建立记录的过程时间复杂度为O(N),额外空间复杂度为O(N)。查询操作时,时间复杂度为O(h),其中,h为二叉树的
* 高度。
*
* 结构二:直接建立任意两个节点之间的最近公共祖先记录,便于以后查询时直接查。
* 建立记录的具体过程如下:
* 1、对二叉树中的每棵子树(一共N棵)都进行步骤2。
* 2、假设子树的头节点为h,h所有的后代节点和h节点的最近公共祖先都是h,记录下来。h左子树的每个节点和h右子树的每个节点的
* 最近公共祖先都是h,记录下来。
* 为了保证记录不重复,设计一种好的实现方式是这种结构实现的重点。
* 结构二的具体实现请参看如下代码中Record2类的实现。
* 如果二叉树的节点数为N,想要记录每两个节点之间的信息,信息的条数为(N-1)xN/2。所以建立结构二的过程的额外空间复杂度为
* O(N^2),时间复杂度为O(N^2),单次查询的时间复杂度为O(1)。
*
* @author Created by LiveEveryDay
*/
public class FindLowestCommonAncestorInBinaryTree2 {
// 定义二叉树的节点类
public static class Node {
public int data;
public Node left;
public Node right;
public Node(int data) {
this.data = data;
}
}
// 使用HashMap记录每个节点的父节点,实现查找最近公共祖先的功能
public static class Record1 {
private final HashMap<Node, Node> map;
// 构造函数,初始化HashMap并设置节点的父节点信息
public Record1(Node head) {
map = new HashMap<>();
if (head != null) {
map.put(head, null);
}
setMap(head);
}
// 递归设置每个节点的父节点信息
private void setMap(Node head) {
if (head == null) {
return;
}
if (head.left != null) {
map.put(head.left, head);
}
if (head.right != null) {
map.put(head.right, head);
}
setMap(head.left);
setMap(head.right);
}
// 查找最近公共祖先节点
public Node query(Node o1, Node o2) {
HashSet<Node> path = new HashSet<>();
// 记录从 o1 到根节点的路径
while (map.containsKey(o1)) {
path.add(o1);
o1 = map.get(o1);
}
// 在 o2 到根节点的路径上找到最近的公共节点
while (!path.contains(o2)) {
o2 = map.get(o2);
}
return o2;
}
}
// 使用HashMap记录每个节点与其祖父节点的关系,实现查找最近公共祖先的功能
public static class Record2 {
private final HashMap<Node, HashMap<Node, Node>> map;
// 构造函数,初始化HashMap并设置节点与祖父节点的关系
public Record2(Node head) {
map = new HashMap<>();
initMap(head);
setMap(head);
}
// 初始化HashMap,建立每个节点的对应关系
private void initMap(Node head) {
if (head == null) {
return;
}
map.put(head, new HashMap<>());
initMap(head.left);
initMap(head.right);
}
// 设置每个节点与其祖父节点的关系
private void setMap(Node head) {
if (head == null) {
return;
}
headRecord(head.left, head);
headRecord(head.right, head);
subRecord(head);
setMap(head.left);
setMap(head.right);
}
// 设置每个节点与其父节点的关系
private void headRecord(Node n, Node h) {
if (n == null) {
return;
}
map.get(n).put(h, h);
headRecord(n.left, h);
headRecord(n.right, h);
}
// 设置每个节点与其子节点的关系
private void subRecord(Node head) {
if (head == null) {
return;
}
preLeft(head.left, head.right, head);
subRecord(head.left);
subRecord(head.right);
}
// 设置每个左子节点与右子节点的关系
private void preLeft(Node l, Node r, Node h) {
if (l == null) {
return;
}
preRight(l, r, h);
preLeft(l.left, r, h);
preLeft(l.right, r, h);
}
// 设置每个右子节点与左子节点的关系
private void preRight(Node l, Node r, Node h) {
if (r == null) {
return;
}
map.get(l).put(r, h);
preRight(l, r.left, h);
preRight(l, r.right, h);
}
// 查找最近公共祖先节点
public Node query(Node o1, Node o2) {
if (o1 == o2) {
return o1;
}
if (map.containsKey(o1)) {
return map.get(o1).get(o2);
}
if (map.containsKey(o2)) {
return map.get(o2).get(o1);
}
return null;
}
}
// 主函数,测试最近公共祖先的查找功能
public static void main(String[] args) {
FindLowestCommonAncestorInBinaryTree2 solution = new FindLowestCommonAncestorInBinaryTree2();
// 构建二叉树
Node node1 = new Node(2);
Node node2 = new Node(3);
Node node3 = new Node(5);
Node node4 = new Node(7);
Node node5 = new Node(8);
Node node6 = new Node(1);
Node node7 = new Node(3);
node1.left = node2;
node1.right = node3;
node2.left = node4;
node2.right = node5;
node3.left = node6;
node3.right = node7;
// 使用 Record1 查找最近公共祖先
Record1 record1 = new Record1(node1);
Node n1 = record1.query(node3, node7);
System.out.printf("The lowest common ancestor is: %d%n", n1.data);
// 使用 Record2 查找最近公共祖先
Record2 record2 = new Record2(node1);
Node n2 = record2.query(node3, node7);
System.out.printf("The lowest common ancestor is: %d%n", n1.data);
}
}
// ------ Output ------
/*
The lowest common ancestor is: 5
The lowest common ancestor is: 5
*/十九 Tarjan算法与并查集解决二叉树节点间最近公共祖先的批量查询问题
二十 二叉树节点间的最大距离问题
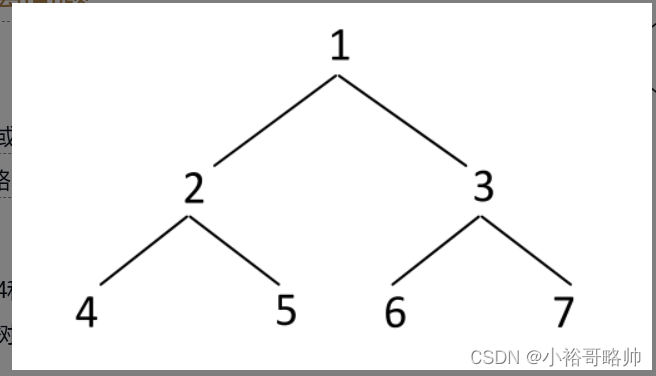
【题目】从二叉树的节点A出发,可以向上或者向下走,但沿途的节点只能经过一次,当到达节点B时,路径上的节点数叫作A到B的距离。比如,图3-43所示的二叉树,节点4和节点2的距离为2,节点5和节点6的距离为5。给定一棵二叉树的头节点head,求整棵树上节点间的最大距离。
【要求】如果二叉树的节点数为N,时间复杂度要求为O(N)。
public class ReturnType {
public int maxDistance;
public int height;
// 构造函数
public ReturnType(int maxDistance, int height) {
super();
this.maxDistance = maxDistance;
this.height = height;
}
// 递归处理二叉树节点的函数
public ReturnType process(Node head) {
// 处理空节点的情况
if (head == null) {
return new ReturnType(0, 0);
}
// 递归处理左子树和右子树
ReturnType leftData = process(head.left);
ReturnType rightData = process(head.right);
// 计算以当前节点为根节点时的高度和最大距离
int height = Math.max(leftData.height, rightData.height) + 1;
int maxDistance = Math.max(leftData.height + rightData.height + 1,
Math.max(leftData.maxDistance, rightData.maxDistance));
// 返回以当前节点为根节点时的结果
return new ReturnType(maxDistance, height);
}
// 获取整棵树上节点间的最大距离的方法
public int getMaxDistance(Node head) {
return process(head).maxDistance;
}
}-
首先定义一个 ReturnType 类,用于存储每个节点递归计算得到的最大距离和高度信息。
-
在 process 方法中,采用递归的方式处理二叉树的每个节点,对左子树和右子树进行递归处理,并根据左右子树的结果计算当前节点的最大距离和高度。
-
计算当前节点的高度时,取左右子树中较大的高度加上 1。
-
计算当前节点的最大距离时,考虑三种情况:左子树的最大距离、右子树的最大距离和左右子树的高度之和加 1,取三者的最大值。
-
在 getMaxDistance 方法中,以根节点为参数调用 process 方法,返回整棵树上节点间的最大距离。
二十一 派对的最大快乐值
【题目】员工信息的定义如下:

公司的每个员工都符合Employee类的描述。整个公司的人员结构可以看作是一棵标准的、没有环的多叉树。树的头节点是公司唯一的老板,除老板外,每个员工都有唯一的直接上级。叶节点是没有任何下属的基层员工(subordinates列表为空),除基层员工外,每个员工都有一个或多个直接下级。这个公司现在要办party,你可以决定哪些员工来,哪些员工不来。
但是要遵循如下规则。
1.如果某个员工来了,那么这个员工的所有直接下级都不能来。
2.派对的整体快乐值是所有到场员工快乐值的累加。
3.你的目标是让派对的整体快乐值尽量大。给定一个头节点boss,请返回派对的最大快乐值。
【要求】如果以boss为头节点的整棵树有N个节点,请做到时间复杂度为O(N)。
public class ReturnData {
public int yesHeadMax; // 员工参加活动时,以该员工为头节点的树的最大快乐值
public int noHeadMax; // 员工不参加活动时,以该员工为头节点的树的最大快乐值
public ReturnData(int yesHeadMax, int noHeadMax) {
super();
this.yesHeadMax = yesHeadMax;
this.noHeadMax = noHeadMax;
}
}
class Employee {
public int happy;
List<Employee> subordinates;
}
public class MaxHappy {
// 获取整个公司派对的最大快乐值
public int getMaxHappy(Employee boss) {
ReturnData allTreeInfo = process(boss);
return Math.max(allTreeInfo.noHeadMax, allTreeInfo.yesHeadMax);
}
// 递归处理以某个员工为头节点的子树,返回该子树的最大快乐值情况
public ReturnData process(Employee X) {
int yesX = X.happy; // 假设员工X参加活动的最大快乐值为自己的快乐值
int noX = 0; // 假设员工X不参加活动的最大快乐值为0
// 处理基层员工的情况
if (X.subordinates.isEmpty()) {
return new ReturnData(yesX, noX);
} else {
// 处理有下属的员工情况
for (Employee next : X.subordinates) {
ReturnData subTreeInfo = process(next);
yesX += subTreeInfo.noHeadMax; // 如果员工X参加活动,则下属员工不参加
noX += Math.max(subTreeInfo.yesHeadMax, subTreeInfo.noHeadMax); // 如果员工X不参加活动,则根据下属员工的情况计算最大快乐值
}
return new ReturnData(yesX, noX);
}
}
}解题思路:
-
定义
ReturnData类来存储以某个员工为头节点的子树的最大快乐值情况,包括员工参加活动和不参加活动的情况。 -
getMaxHappy方法是整个程序的入口,通过调用process方法来获得整个公司派对的最大快乐值。 -
process方法用于递归地处理以某个员工为头节点的子树,计算员工参加活动和不参加活动的最大快乐值情况。 -
对于每个员工,如果他没有下属(即基层员工),则直接返回其快乐值。否则,对于每个直接下属,递归计算其参加和不参加活动的最大快乐值,并根据规则更新当前员工的最大快乐值。
-
最终返回以老板为头节点的整个公司派对的最大快乐值。
通过这种递归的方式,可以高效地计算整个公司派对的最大快乐值,时间复杂度为 O(N)。
二十二 通过先序和中序数组生成后序数组
【题目】已知一棵二叉树所有的节点值都不同,给定这棵树正确的先序和中序数组,不要重建整棵树,而是通过这两个数组直接生成正确的后序数组。
import java.util.HashMap;
public class GeneratePostOrder {
public int[] getPosArr(int[] pre, int[] in) {
// 如果前序或中序数组为空,直接返回null
if (pre == null || in == null) {
return null;
}
int len = pre.length; // 获取数组长度
int[] pos = new int[len]; // 创建后序数组
HashMap<Integer, Integer> map = new HashMap<>(); // 使用HashMap存储中序数组的值与索引的对应关系
// 将中序数组的值和索引存入HashMap
for (int i = 0; i < len; i++) {
map.put(in[i], i);
}
// 递归生成后序数组
setPos(pre, 0, len - 1, in, 0, len - 1, pos, len - 1, map);
return pos; // 返回后序数组
}
// 递归生成后序数组
private int setPos(int[] p, int pi, int pj, int[] n, int ni, int nj, int[] s, int si, HashMap<Integer, Integer> map) {
// 基础情况:当前序数组指针超出范围时,直接返回后序数组索引
if (pi > pj) {
return si;
}
// 根据当前前序数组的值生成后序数组
s[si--] = p[pi];
int i = map.get(p[pi]); // 在中序数组中找到当前根节点的位置
// 递归生成右子树的后序数组
si = setPos(p, pj - nj + i + 1, pj, n, i + 1, nj, s, si, map);
// 递归生成左子树的后序数组
return setPos(p, pi + 1, pi + i - ni, n, ni, i - 1, s, si, map);
}
public static void main(String[] args) {
GeneratePostOrder generator = new GeneratePostOrder();
int[] pre = {1, 2, 4, 5, 3, 6, 7};
int[] in = {4, 2, 5, 1, 6, 3, 7};
int[] post = generator.getPosArr(pre, in);
System.out.println("Generated Post-order array: " + Arrays.toString(post));
}
}解题思路:
-
首先,判断给定的前序和中序数组是否为空,如果为空则直接返回null。
-
创建一个HashMap来存储中序数组中每个节点值对应的索引,方便查找。
-
调用
setPos方法递归生成后序数组,该方法的核心是根据前序、中序数组以及HashMap,生成对应的后序数组。 -
在
setPos方法中,首先处理基础情况,即当前序指针超出范围时直接返回。然后根据当前前序节点值生成后序数组,并找到该节点在中序数组中的位置。 -
递归处理右子树和左子树,直到处理完所有节点。
通过这种递归的方法,可以根据给定的前序和中序数组生成正确的后序数组,时间复杂度为 O(N)。
二十三 统计和生成所有不同的二叉树
【题目】
给定一个整数N,如果N<1,代表空树结构,否则代表中序遍历的结果为{1,2,3,...,N}。请返回可能的二叉树结构有多少。
进阶:N的含义不变,假设可能的二叉树结构有M种,请返回M个二叉树的头节点,每一棵二叉树代表一种可能的结构。
package live.every.day.ProgrammingDesign.CodingInterviewGuide.BinaryTree;
import live.every.day.ProgrammingDesign.CodingInterviewGuide.BinaryTree.BinaryTreePrinter2.Node;
import java.util.LinkedList;
import java.util.List;
/**
* 统计和生成所有不同的二叉树
*
* 【题目】
* 给定一个整数N,如果N<1,代表空树结构,否则代表中序遍历的结果为{1,2,3,...,N}。请返回可能的二叉树结构有多少。
* 进阶:N的含义不变,假设可能的二叉树结构有M种,请返回M个二叉树的头节点,每一棵二叉树代表一种可能的结构。
*
* 【难度】
* 中等
*
* 【解答】
* 如果中序遍历有序且无重复值,则二叉树必为搜索二叉树。假设num(a)代表a个节点的搜索二叉树有多少种可能,再假设序列为
* {1,...,i,...,N},如果以1作为头节点,1不可能有左子树,故以1作为头节点有多少种可能的结构,完全取决于1的右子树有多
* 少种可能结构,1的右子树有N-1个节点,所以有num(N-1)种可能。
* 如果以i作为头节点,i的左子树有i-1个节点,所以可能的结构有num(i-1)种,右子树有N-i个节点,所以有num(N-i)种可能。故
* 以i为头节点的可能结构有num(i-1)*num(N-i)种。
* 如果以N作为头节点,N不可能有右子树,故以N作为头节点有多少种可能,完全取决于N的左子树有多少种可能,N的左子树有N-1个节
* 点,所以有num(N-1)种。
* 把从1到N分别作为头节点时,所有可能的结构加起来就是答案,可以利用动态规划来加速计算的过程,从而做到O(N^2)的时间复杂
* 度。
* 具体请参看如下代码中的numTrees方法。
*
* 进阶问题与原问题的过程其实是很类似的。如果要生成中序遍历是{a...b}的所有结构,就从a开始一直到b,枚举每一个值作为头节
* 点,把每次生成的二叉树结构的头节点都保存下来即可。假设其中一次是以i值为头节点的(a<=i<=b),以i头节点的所有结构按如下
* 步骤生成:
* 1、用{a...i-1}递归生成左子树的所有结构,假设所有结构的头节点保存在listLeft链表中。
* 2、用{a...i+1}递归生成右子树的所有结构,假设所有结构的头节点保存在listRight链表中。
* 3、在以i为头节点的前提下,listLeft中的每一种结构都可以与listRight中的每一种结构构成单独的结构,且和其他任何结构都
* 不同。为了保证所有的结构之间不互相交叉,所以对每一种结构都复制出新的树,并记录在总的链表res中。
*
* 具体过程请参看如下代码中的generateTrees方法。
*
* @author Created by LiveEveryDay
*/
public class DoStatisticsAndGenerateAllDifferentBinaryTrees {
public static int numTrees(int n) {
if (n < 2) {return 1;}
int[] num = new int[n + 1];
num[0] = 1;
for (int i = 1; i < n + 1; i++) {
for (int j = 1; j < i + 1; j++) {
num[i] += num[j - 1] * num[i - j];
}
}
return num[n];
}
public static List<Node> generateTrees(int n) {
return generate(1, n);
}
public static List<Node> generate(int start, int end) {
List<Node> res = new LinkedList<>();
if (start > end) {
res.add(null);
}
Node head = null;
for (int i = start; i < end + 1; i++) {
head = new Node(i);
List<Node> lSubs = generate(start, i - 1);
List<Node> rSubs = generate(i + 1, end);
for (Node l : lSubs) {
for (Node r : rSubs) {
head.left = l;
head.right = r;
res.add(cloneTree(head));
}
}
}
return res;
}
public static Node cloneTree(Node head) {
if (head == null) {
return null;
}
Node res = new Node(head.data);
res.left = cloneTree(head.left);
res.right = cloneTree(head.right);
return res;
}
public static void main(String[] args) {
System.out.printf("The number of trees is: %d%n", numTrees(3));
List<Node> trees = generateTrees(3);
for (Node node : trees) {
BinaryTreePrinter2.print(node);
}
}
}
// ------ Output ------
/*
The number of trees is: 5
1
\
2
\
3
1
\
3
/
2
2
/ \
1 3
3
/
1
\
2
3
/
2
/
1
*/














 1319
1319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









