







下载jdk1.7.0_67,每个节点传一份
scp -r jdk1.7.0_67 cloud@XXX.XXX.XXX.XXX:/home/cloud/
在每个节点:
配置环境变量,sudo vim /etc/profile,增加代码:
export JAVA_HOME=/home/cloud/jdk1.7.0_67
export CLASSPATH=/home/cloud/jdk1.7.0_67/lib
export PATH=$JAVA_HOME/bin:$PATH
使profile文件更新生效:
. /etc/profile
运行java -version查看:

2、SSH免密码登陆
在每个节点,执行:ssh-keygen -t rsa
然后在Master结点,执行:cd .ssh
分发给每个slave:scp id_rsa.pub cloud@XXX.XXX.XXX.XXX:/home/cloud
在每个slave节点:cat id_rsa.pub >> ~/.ssh/authorized_keys
(主节点也要搞一下,不然每次start-all都有输一次密码)
然后在每个节点:vim /etc/hosts
#127.0.0.1 localhost
10.0.0.22 hadoop-slave20
10.0.0.15 hadoop-slave12
10.0.0.16 hadoop-slave13
10.0.0.19 hadoop-slave17
10.0.0.20 hadoop-slave18
10.0.0.21 hadoop-slave19
#127.0.1.1 cloud
ssh实验一下。
3、安装scala
下载scala-2.10.6.tgz:
wget http://downloads.typesafe.com/scala/2.10.6/scala-2.10.6.tgz
解压:tar -xzvf scala-2.10.6.tgz
配置环境变量:sudo vim /etc/profile,增加代码:
export SCALA_HOME=/home/cloud/scala-2.10.6
export PATH=${SCALA_HOME}/bin:$PATH
使profile文件更新生效:
. /etc/profile
运行scala -version查看:

4、安装Hadoop
下载hadoop-2.5.2:
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.5.2/hadoop-2.5.2.tar.gz
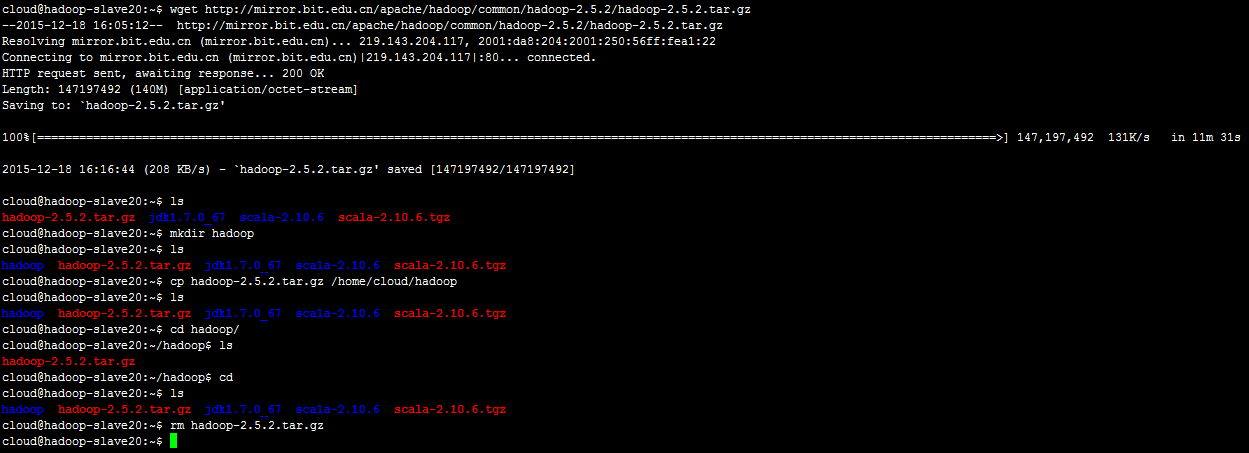
cd hadoop
解压,tar -vxzf hadoop-2.5.2.tar.gz
配置环境变量,sudo vim /etc/profile,增加以下内容:
export HADOOP_INSTALL=/home/cloud/hadoop/hadoop-2.5.2export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
更新. /etc/profile
编辑配置文件:
cd /etc/hadoop
配置hadoop-env.sh
export JAVA_HOME=/home/cloud/jdk1.7.0_67
配置core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-slave20:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/cloud/hadoop/tmp</value>
</property>
</configuration>
配置yarn-env.sh
export JAVA_HOME=/home/cloud/jdk1.7.0_67
配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-slave20:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-slave20:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-slave20:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop-slave20:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop-slave20:8088</value>
</property>
</configuration>
配置mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
加入:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>hadoop-slave20:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-slave20:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-slave20:19888</value>
</property>
</configuration>
配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-slave20:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>${hadoop.tmp.dir}/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置slaves
hadoop-slave12
hadoop-slave13
hadoop-slave17
hadoop-slave18
hadoop-slave19
把hadoop所有文件传给个节点:
scp -r hadoop hadoop-slave XX:/home/cloud/
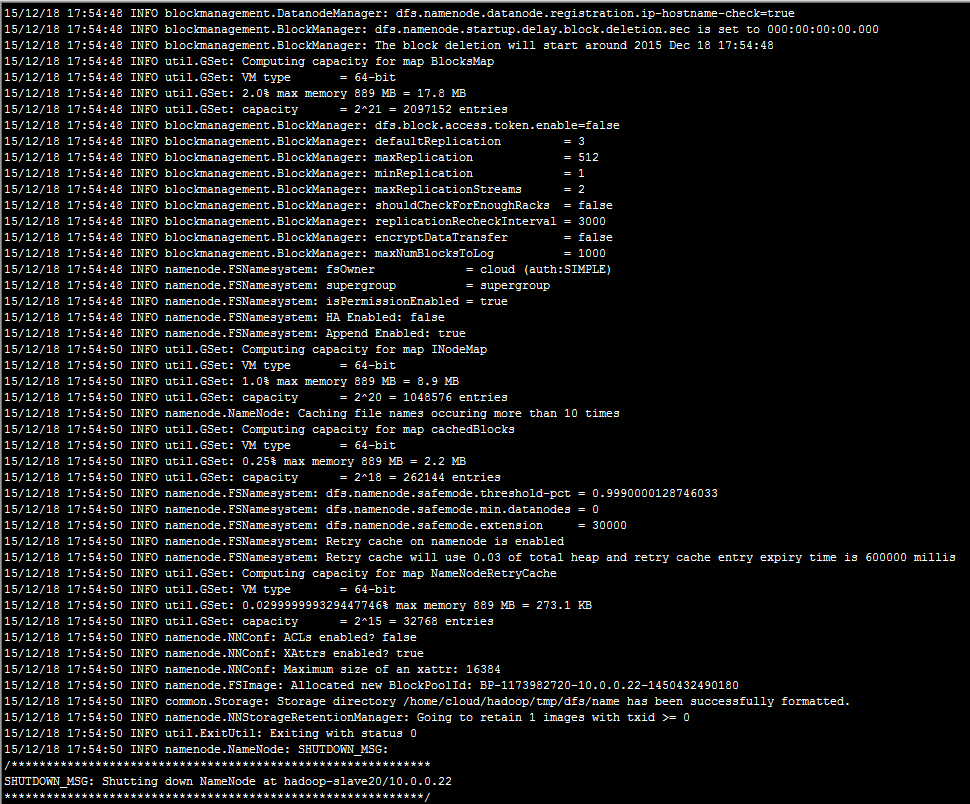
格式化NameNode:
bin/hadoop namenode -format
启动Hadoop:
sbin/start-all.sh
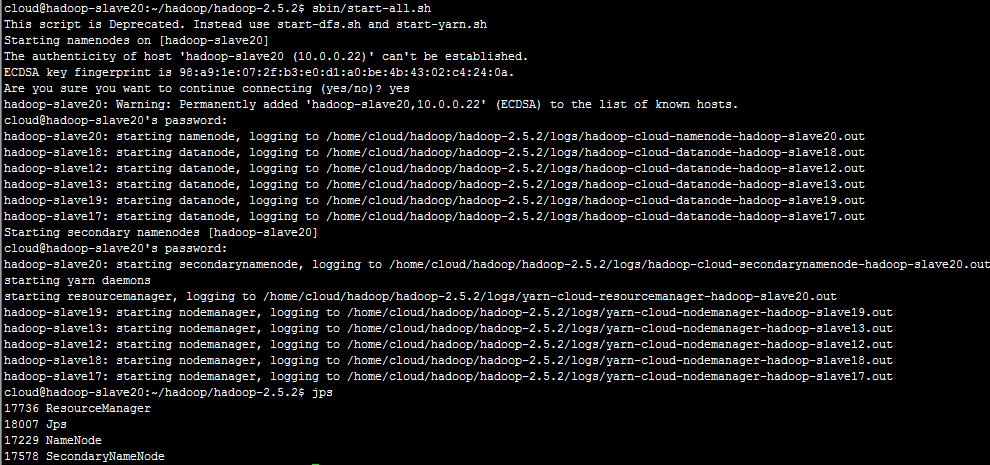
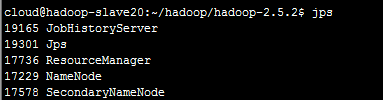
使用jps查看。
查看网页:
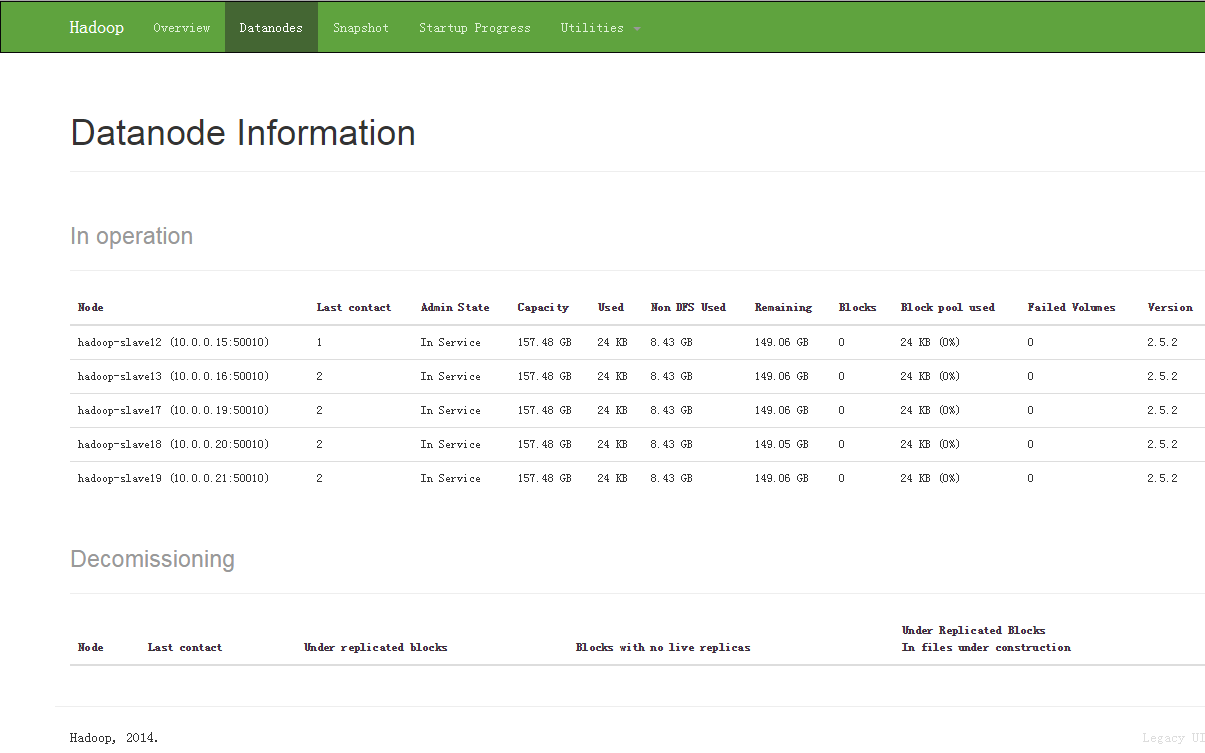
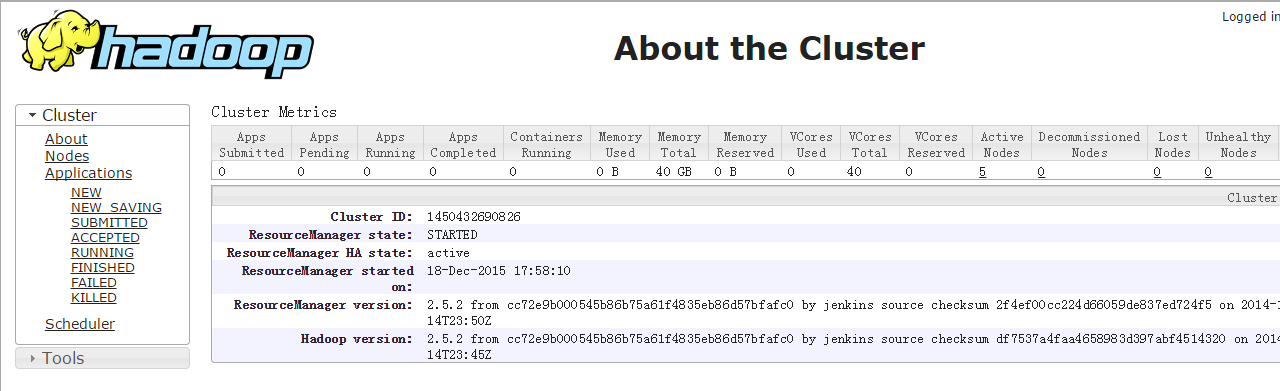
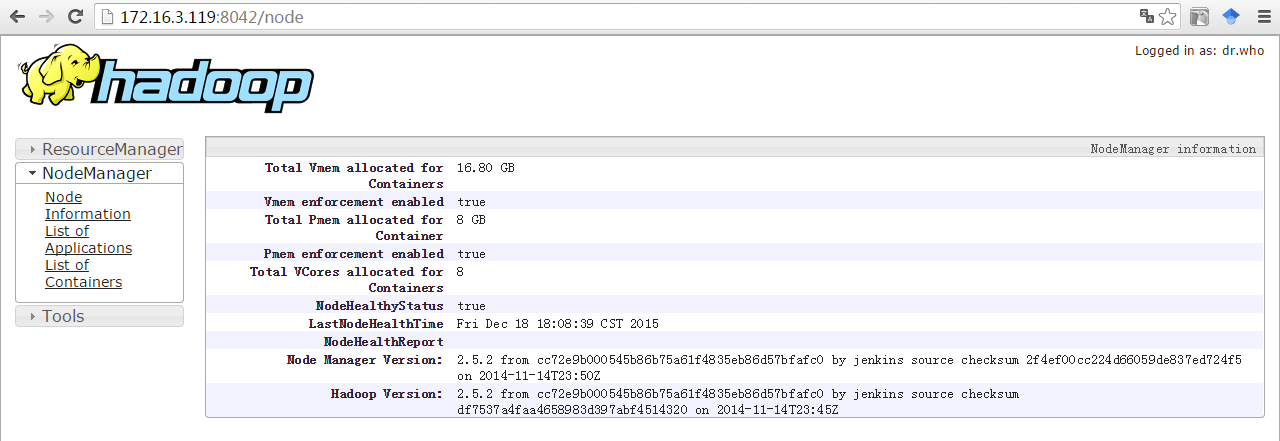
完成(此处该有掌声!)。
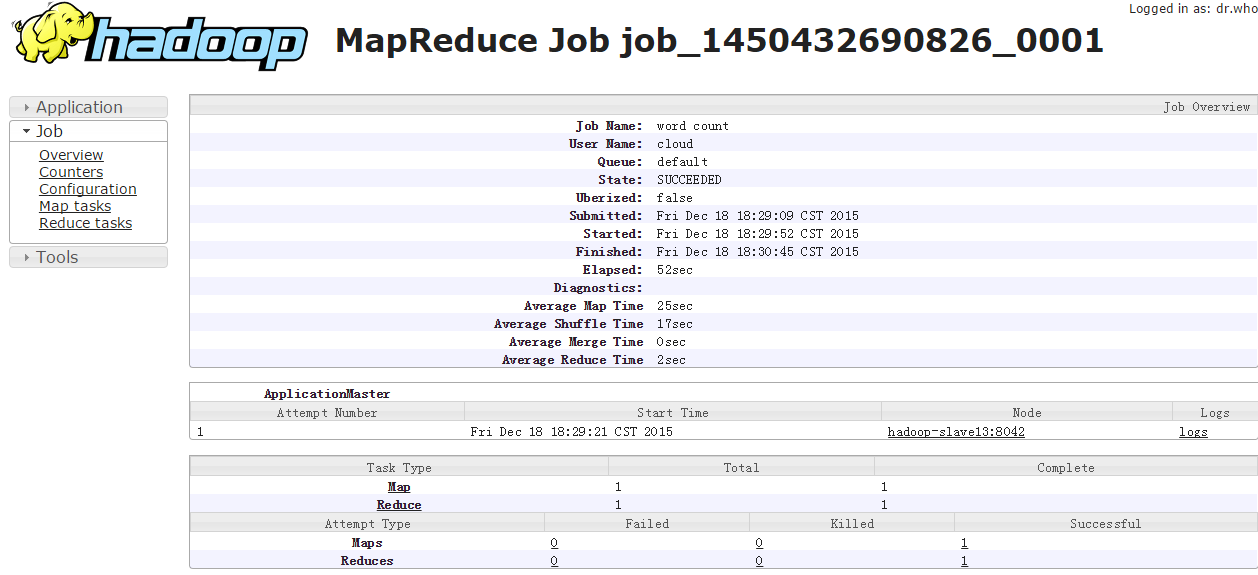
测试wordcount
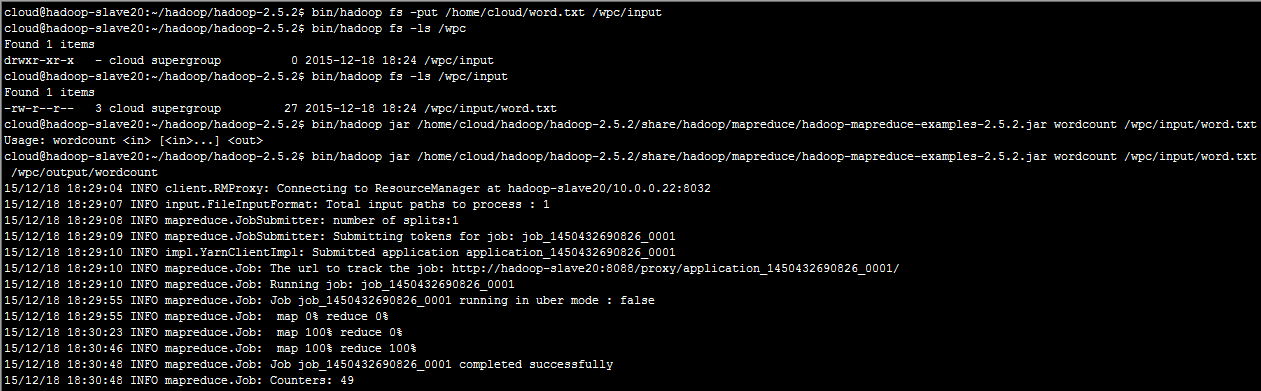

查看jobhistory
用命令mapred historyserver
http://172.16.3.125(master):19888/
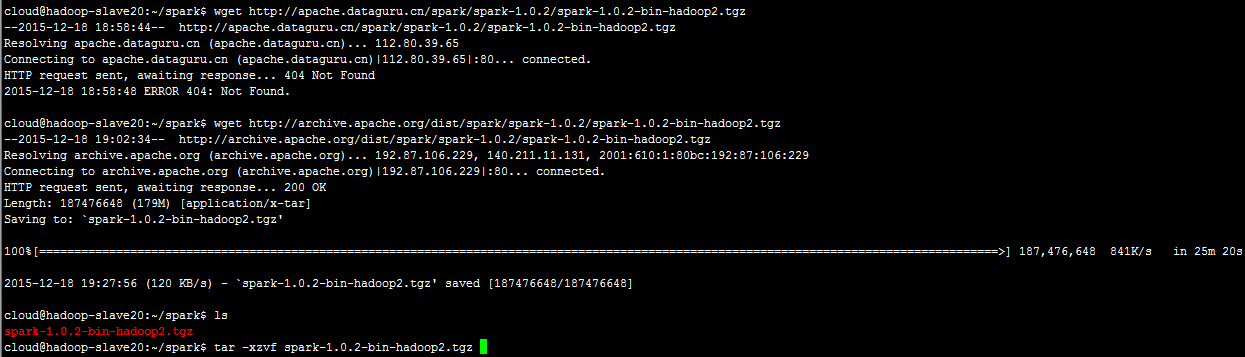
5、安装spark
wget http://archive.apache.org/dist/spark/spark-1.0.2/spark-1.0.2-bin-hadoop2.tgz
配置spark-env.sh
export JAVA_HOME=/home/cloud/jdk1.7.0_67
export SCALA_HOME=/home/cloud/scala-2.10.6
export HADOOP_HOME=/home/cloud/hadoop/hadoop-2.5.2
export HADOOP_CONF_DIR=/home/cloud/hadoop/hadoop-2.5.2/etc/hadoop
export SPARK_WORKER_MEMORY=7g
export SPARK_MASTER_IP=hadoop-slave20
slaves配置:
hadoop-slave12
hadoop-slave13
hadoop-slave17
hadoop-slave18
hadoop-slave19
传给每个节点。
在sbin里面启动spark:
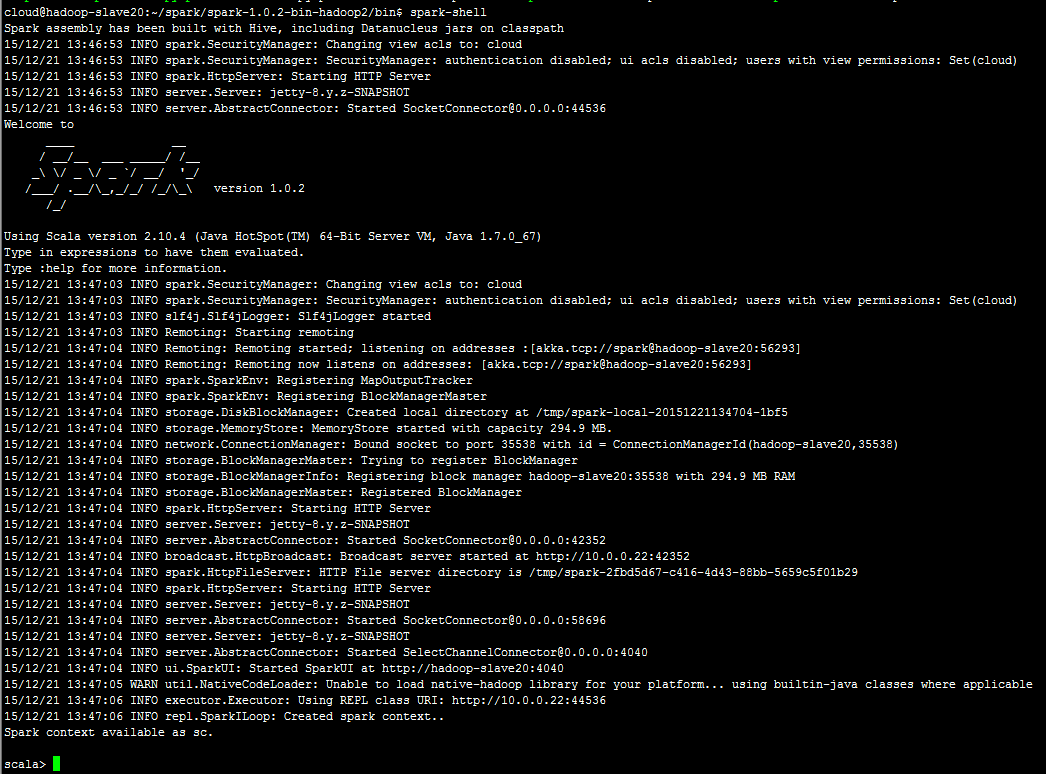
spark-shell
spark/spark---/conf/sbin:
start-all.sh是启动NameNode,DataNode
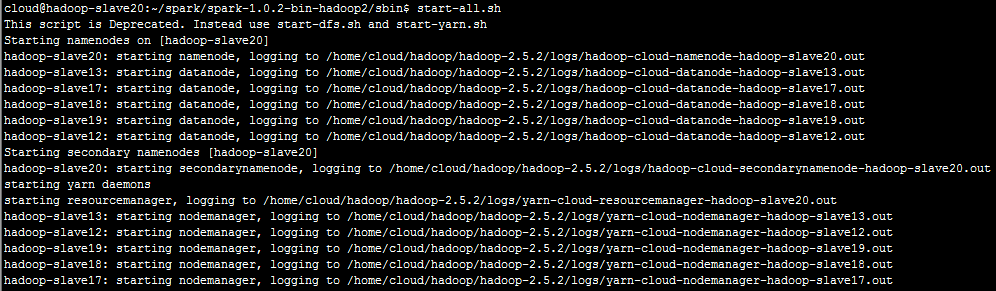
sh start-all.sh是启动Master和Slave的。

跑一个测试例子:
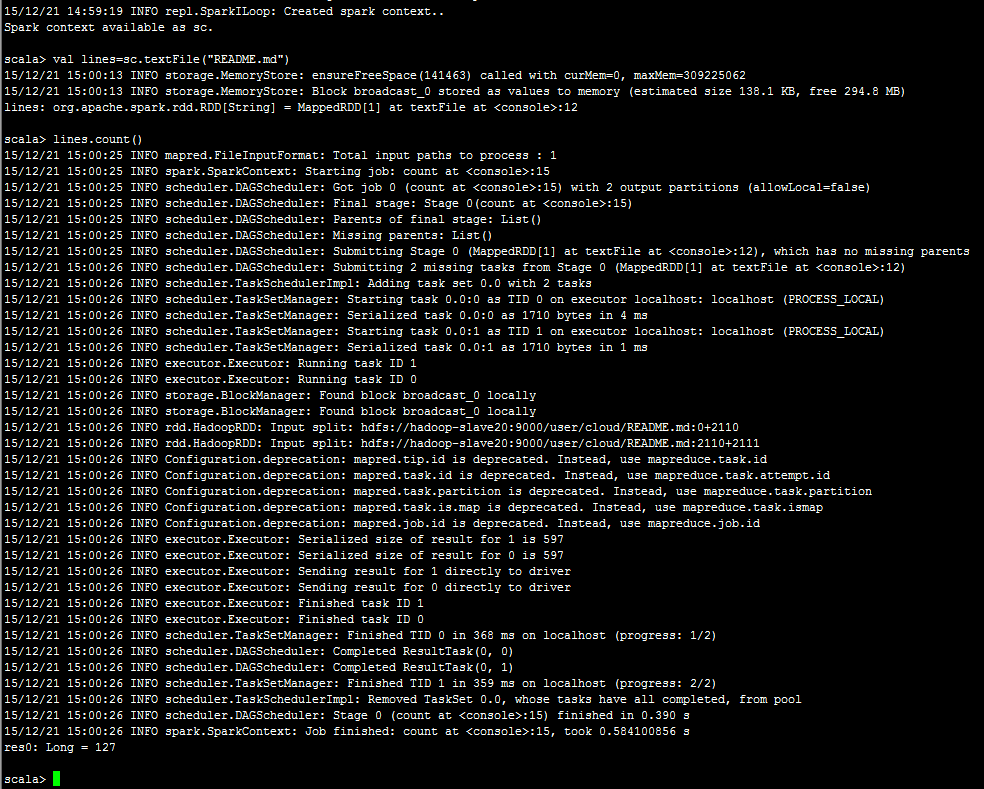
web
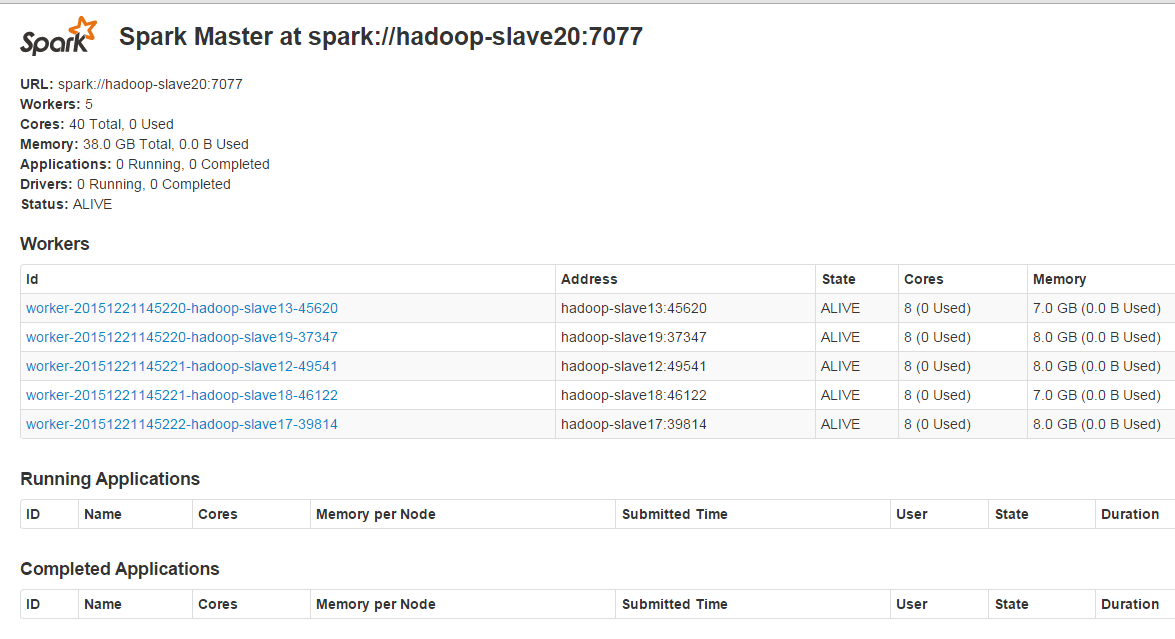















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









