









2.1二分类问题

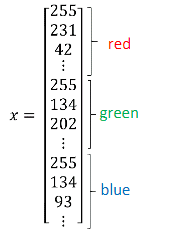
将三通道的RGB图片每一个像素值竖直摞起来放置,形成特征向量x.
即特征向量x为64×64×3(12288,1)的矩阵

我们用x(1)代表第一张训练图片形成的特征向量
总共共训练m张训练图片。将x(1)—x(m)横向放置,形成大矩阵X。
故X为(nx,m)的矩阵
输出的标签结果y,为(1,m)的矩阵
logistic regression逻辑回归

另一种写法:
x0=1,故x属于nx+1维向量
其中θ0表示w^Tx+b,中的b。θ1-θnx中的w

logistic回归损失函数

对于逻辑回归来说,如果采用原来的损失函数:L(y^ ,y)=1/2(y^ -y)2,其损失函数图像为non-convex非凸的,则利用梯度下降很难找到整体最优值。
故新的逻辑回归的损失函数变为,如上所示。
假如y=1(真实值为1):L(y^ ,y)=-logy^ 想要-logy^ 越接近0,则根据图像,y^越接近1
假如y=0(真实值为0):L(y^ ,y) =-log(1-y^ ) 想要-log1-y^ 越接近0,则根据图像,1-y^ 越接近1,y^越接近0


loss function衡量了单个样本(y^(i)),预测值与实际值之间的差距
cost function衡量了m个样本之间,差距的平均值
梯度下降法

画出取得不同w,b的时候,对应的J(w,b)的图像。此图像为凸函数。我们需要找到J(w,b)图像中最低的点,即为全局最优点。

对w进行更新的方法:
w=w-α(学习率) dJ(w)/dw
其中学习率α决定了梯度下降每次下降的步伐大小。
注意:
如果J(w,b)函数中有大于等于2个的变量,我们就需要使用偏导数符号
computation graph计算图
解释什么为正向传播,什么为反向传播
正向传播计算数量

反向传播计算导数


逻辑回归损失函数的解释

设P(y|x)=y(hat)y (1-y(hat))(1-y)
则,当y=1时,P(y|x)=y(hat)1 (1-y(hat))0 =y(hat) 1 =y(hat)
当y=0时,P(y|x)= y(hat)0 (1-y(hat))(1-y) = 1 (1-y(hat)) =1-y(hat)
由于log函数是单调增加的函数,故对P(y|x)取对数。其结果就是负的loss function。
逻辑回归中取最小的逻辑回归值,也就是取最大的P(y|x)的概率
















 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









