







AI时代,我们听到很多新名词,技术领域,应该不陌生:向量技术,语义搜索。我们稍稍了解深入一点,就知道语义相似搜索,是基于向量技术的。
但是,普通的文本,是怎么转成向量的呢?为什么转成向量,就能进行相似计算呢?这些问题,就算是有相当经验的IT从业人员,也会存疑,知其然不知其所以然。
最近深入研究,把这个问题科普了,在此总结一下。
1、词汇搜索与语义搜索
词汇搜索:就是根据关键字匹配,无论是sql的“=”、like,还是Elasticsearch的倒排索引,都离不开匹配,也就是搜索结果与条件必须有完全相同的关键字。
语义搜索:搜索结果的相关性是由系统内的语义接近度决定的,而不仅仅是关键字匹配。
举例,我们要搜索“会抓老鼠的动物”,如果用词汇搜索,是无论如何都不会得出“猫”这样的结果的,但是,用语义搜索,就可以。
2、文本转换成向量,此向量就是在一个空间中的位置(坐标)
该坐标单独并不具有任何意义,必须与其他文本同时存在于此空间才有意义,因为不同的坐标体现了不同文本的距离。这里的距离就是相关度。
3、文本的坐标如何算出来?
一个机器学习模型,就是各种文本+文本坐标的集合,那么,文本坐标是怎么算出来的?是不是AI的黑科技?其实,归根结底,都是“训练”两个字,说到训练,到底还是离不开人。
怎么去训练呢?核心就是数据集。数据集是要人工去整理的,数据集介乎结构化数据和非结构化数据之间,他看起来是这样的:
简单来说,就是人工把大量的文本进行了整理归类,让其有固定格式,并体现一定的内在关系。
这些数据集通过机器学习,大模型就获得了很多文本的意义关系,也即他们的坐标距离。
坐标的绝对值,其实无所谓,只要这个值能体现各个坐标的距离即可。
可以说,一个语言模型的能力,除了技术因素之外,还在很大程度上取决于训练数据集的质量和数量(规模)。
一个比较直观的向量坐标示意图,可以帮助理解:
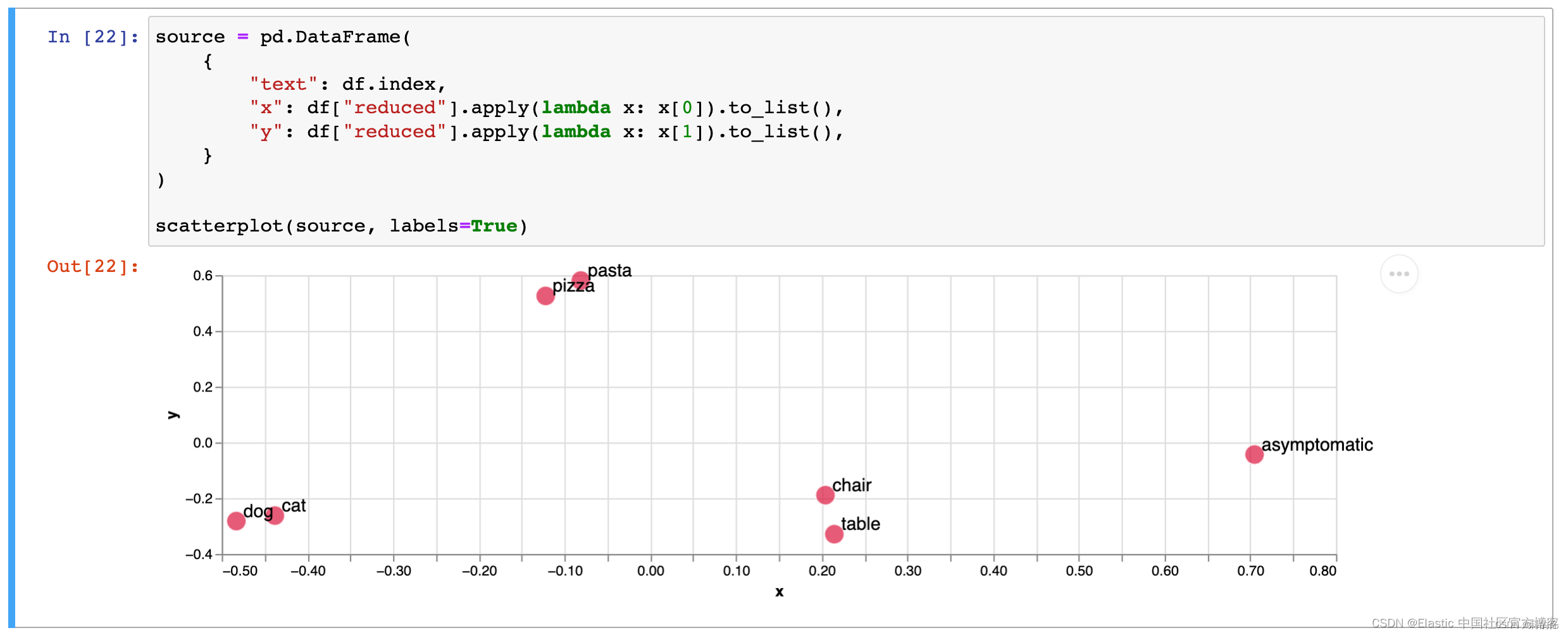
上图是一个大语言模型里面的几个词的坐标(二维化之后)示意图,从图中,可以看到,dog和cat在坐标上的距离是比较近的,而chair和table比较近。
这就体现了语义相似度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









