







文本分类(Text Classification)
是自然语言处理(NLP)领域中的一种任务,它指的是将文本数据(如新闻文章、电子邮件或社交媒体帖子)自动分配到一个或多个预定义的类别(如政治、体育、娱乐等)中。这可以通过训练机器学习模型来实现,该模型可以根据文本的词汇、语法等特征来预测它的类别。
零样本文本分类(Zero-Shot Text Classification)
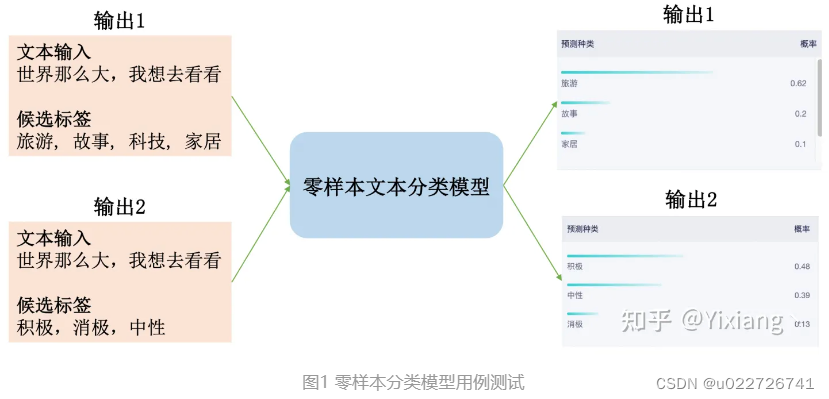
是一种文本分类方法,其优势在于它不需要任何预先标记的训练样本来分类文本。 这意味着,即使在缺乏预先标记的数据的情况下,也可以对文本进行分类。传统的文本分类方法需要大量预先标记的训练样本来训练模型,但在实际应用中,很难收集到足够的预先标记的样本。 因此,零样本文本分类可以作为一种替代方案,以便在缺乏预先标记的数据的情况下进行文本分类。图1展示了零样本分类的测试效果,从图中不难发现,零样本分类模型可以支持标签的自定义,从而使得可以对任何文本分类任务进行推理。
常见的零样本分类模型主要可以分为以下两类:
基于自然语言推理的模型
模型特点:在训练阶段仅使用NLI相关数据集进行训练,在进行零样本分类时,需要将样本转换成nli样本形式。
模型优势:进行推理时,在各种分类任务上的表现比较均衡,受到训练数据的影响较小,分类结果稳定。
模型缺点:每次推理时都需要推理n个样本(其中n为标签数量),模型推理时间随标签数量线性增长。
基于文本生成的模型
模型特点:需要设计prompt来结合文本和标签,让模型生成文本对应的标签。
模型优势:推理效率较高,每次推理只需要推理1个样本。
模型缺点:由于是生成模型,生成的结果可能不稳定,即生成的文本不存在与候选标签中。同时该模型在训练时使用了大量文本分类数据集进行训练,因此在不同分类任务上表现出的性能可能存在较大差异。
基于自然语言推理的零样本分类模型
从模型原理的解析中可以发现基于自然语言推理的零样本文本分类模型在进行分类时,需要将候选标签逐一与文本进行结合生成对应的NLI的样本,这意味着有N个候选标签,就需要生成N个待推理样本。因此,该模型的推理效率可能较低,是一种用时间成本来获取更高准确率的方案。但该方案在抹零战役工单分类任务的低资源场景下,表现出了优异的性能。因此,在推理时间不敏感的低资源场景下的文本分类任务,该模型非常适用。
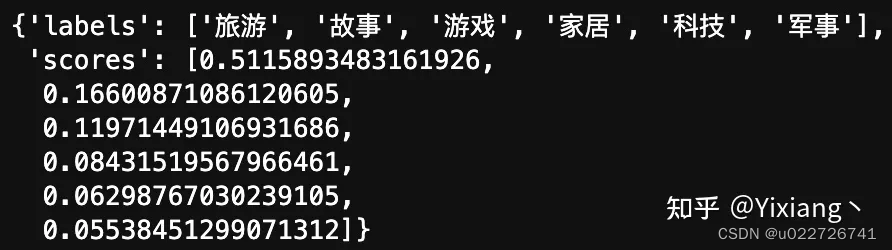
举例:对三个样本进行自然语言推理的预测之后,最后将预测结果进行整合,即可实现零样本分类任务。例如多分类任务中,可以将“前提句”蕴含“假设句”概率最大的那个假设作为最后的标签。
设置三个标签:家居,旅游,科技
输入文本:世界那么大,我想去看看
对以上输入进行零样本分类的时候,将生成以下三个自然语言推理任务的样本:
1. 前提:世界那么大,我想去看看,假设:家居
2. 前提:世界那么大,我想去看看,假设:旅游
3. 前提:世界那么大,我想去看看,假设:科技
基于文本生成的零样本分类模型
生成式模型
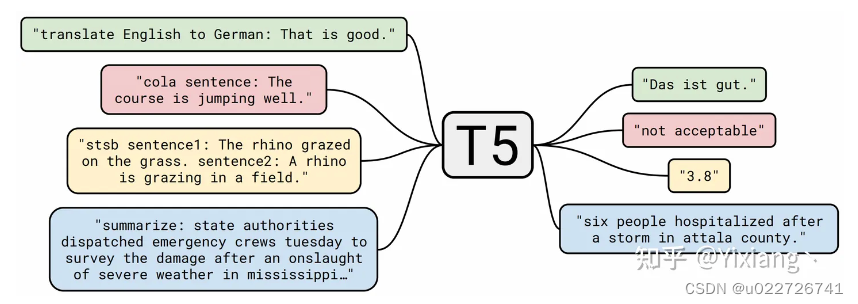
任务统一框架:把所有任务,如文本分类、相似度计算、文本生成等,都使用一个text-to-text的框架进行解决。即T5:Text-to-Text Transfer Transformer,是一种模型架构或者说是一种解决NLP任务的一种范式。它的主要目标就是使用文本生成的方式来解决各种自然语言处理任务,例如机器翻译、摘要、问答等。T5通过使用一种统一的编码和解码方法来解决不同的任务,从而避免了为每个任务单独设计模型的问题,在训练过程中使用了大量的数据和计算资源,以便在比较小的数据集上训练任务特定的模型。并且在大型的数据集上进行了广泛的评估,在许多自然语言处理任务中表现出优越的性能。
该模型除了支持零样本分类外,还可以支持其他任务的零样本学习。支持任务包含:
文本分类:给定一段文本和候选标签,模型可输出文本所属的标签。
自然语言推理:给定两段文本,判断两者关系。
阅读理解:给定问题和参考文本,输出问题的答案。
问题生成:给定答案和参考文本,生成该答案对应的问题。
摘要生成:给定一段文本,生成该文本的摘要。
标题生成:给定一段文本,为其生成标题。
评价对象抽取:给定一段文本,抽取该段文本的评价对象。
翻译:给定一段文本,将其翻译成另一种语言。
总结:
使用文本生成的方式实现零样本分类时,可以将所有候选标签进行结合,只需要生成一个样本进行分类。相比基于NLI的零样本分类模型,在推理效率上优势比较大。但该模型会带来了分类结果不稳定的问题,即输出的文本不存在于候选标签中。而全任务零样本学习-mT5分类增强版-中文-base通过一种数据增强的方式大幅提升了在文本分类场景下的稳定性,在零样本分类稳定性评测中表现出的准确率可达98.51%,远大于其他模型,但在稳定性方面依然不如基于nli的模型。因此,该模型适用于对推理时间较为敏感的低资源文本分类场景。
最终结论:
结合科亿知识库的使用场景,可以使用基于自然语言的零样本分类模型
本文来源:http://docs.kykms.cn/docs/network/network-1f6fs53cgmdms














 2930
2930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









