







今天,你AI了没?
关注:决策智能与机器学习,学点AI干货
对偶理论是研究线性规划中原始问题与对偶问题之间关系的理论。 对偶形式是解决优化问题的一种有效办法,即每一个线性规划问题(称为原始问题)有一个与它对应的对偶线性规划问题(称为对偶问题),在求出一个问题解的同时,也给出了另一个问题的解。可以说是优化求解中四两拨千斤的方法。
本文讨论的就是强化学习问题的对偶形式求解问题。
友情提示:技术深度解读,文中大量公式,公式恐惧症的同学慎入。

原文下载,请在公众号回复:20190620
特色
考虑找到MDP上的最优策略使得累积奖励最大,如果已知 dynamics(P)和 reward(R)那么该问题是一个动态规划问题(DP),又称作规划问题(planning problem);如果这两者未知只能通过和环境交互得到,那么该问题是一个强化学习问题(RL),又称作学习问题(learning problem)。相应的动态规划问题可以表示为一个线性规划问题(LP,可以参见我导师的讲义),相应地,该问题就其对偶形式。前面讲到的 successor representation (SR)就实际上是在解相应的对偶问题。本文给出了 DP 和 RL 问题的相应对偶形式,具体地,给出了对偶形式的 policy evaluation、policy iteration、TD evaluation、SARSA、Q-learning。
过程
这篇文章都是矩阵-向量表示形式,需要注意符号定义,特别是维度。
1. 线性规划及其对偶问题
考虑一个规划问题,它可以写为 LP 的形式
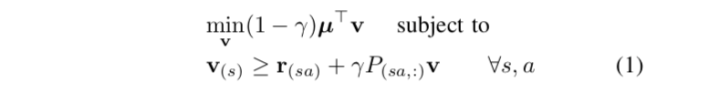
其中 是初始状态分布,
,
,
。要证明它的解是规划问题的解,只需要证明相应的
满足 Bellman equation
。对于任意一个状态
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2828
2828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









