






 本文介绍了如何使用ReliefF算法进行分类数据特征选择,并提供了Matlab代码示例。通过该算法,可以从大量特征中选出对分类任务最具影响力的部分。
本文介绍了如何使用ReliefF算法进行分类数据特征选择,并提供了Matlab代码示例。通过该算法,可以从大量特征中选出对分类任务最具影响力的部分。
基于ReliefF算法的分类数据特征选择算法
matlab代码,输出为选择的特征序号
ID:7329678622137982
誩宝
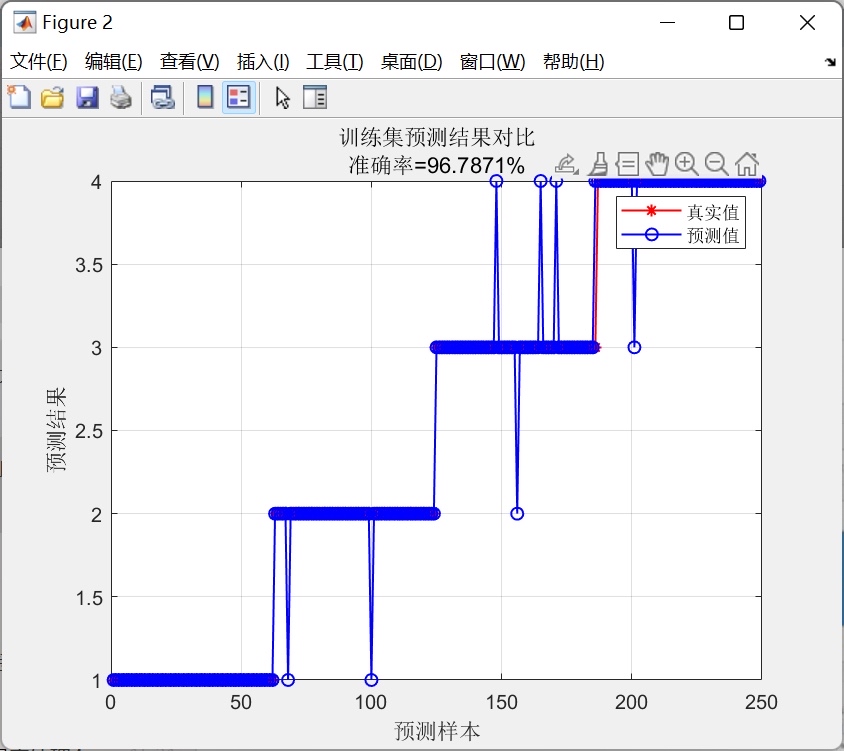
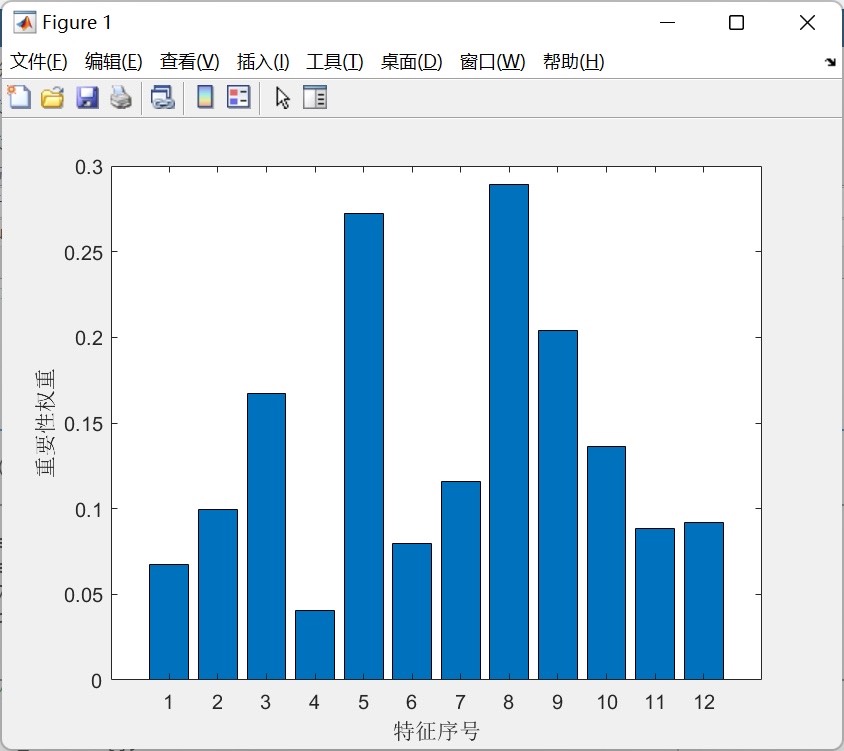
基于ReliefF算法的分类数据特征选择算法
在现代数据分析和机器学习领域,特征选择是一个重要但又具有挑战性的问题。特征选择的目标是从原始数据中找到最具有代表性的特征,以便在分类任务中提高模型的性能和泛化能力。在这篇文章中,我们将介绍一种基于ReliefF算法的分类数据特征选择算法,并提供相应的Matlab代码,通过该代码可以输出选择的特征序号。
首先,让我们来了解一下ReliefF算法。ReliefF算法是一种经典的特征选择方法,它通过计算特征之间的距离和样本之间的距离来评估特征的重要性。具体而言,ReliefF算法通过随机选取一个样本,然后从与该样本不同类别的样本中选取一个最近邻和一个最远邻,计算特征差异值,即当前特征与最近邻特征之间的差异和当前特征与最远邻特征之间的差异。通过累积所有样本的特征差异值,ReliefF算法可以得到一个特征重要性的评估值,从而实现特征选择。
基于ReliefF算法的特征选择算法的流程如下:首先,对于给定的数据集,我们需要初始化一个特征重要性列表,将所有特征的重要性值初始化为0。然后,从数据集中随机选择一个样本。接下来,我们需要计算该样本与所有其他样本的距离,并确定其最近邻和最远邻。然后,对于每个特征,我们计算当前特征与最近邻特征和最远邻特征之间的差异,并更新特征的重要性值。重复上述过程,直到遍历完所有样本。最后,根据特征重要性值进行排序,选择重要性较高的特征作为最终的特征序号输出。
我们提供的Matlab代码实现了基于ReliefF算法的特征选择过程。代码主要分为两个部分,第一部分是数据预处理和初始化操作,主要包括读取数据集、标准化数据、初始化特征重要性列表等;第二部分是特征选择过程的实现,主要包括随机选择样本、计算距离、更新特征重要性列表等。通过运行代码,我们可以得到选择的特征序号,这些特征具有较高的重要性,可以在分类任务中发挥重要作用。
然而,需要注意的是,我们的代码只提供了特征选择过程的实现,并没有提供对代码的详细讲解。如果读者对于ReliefF算法和特征选择方法有所了解,可以直接使用我们的代码进行特征选择。但如果读者对于ReliefF算法和特征选择方法不熟悉,建议先学习相关的知识和理论,并参考相关的文献和资料进行深入学习。
总之,基于ReliefF算法的分类数据特征选择算法是一种有效的特征选择方法。我们提供了相应的Matlab代码,通过该代码可以输出选择的特征序号。读者可以根据自己的需求和实际情况,使用该代码进行特征选择,并将其应用于实际的数据分析和机器学习任务中。希望本文所提供的内容能对读者有所帮助,提高数据分析和机器学习的效果和效率。
【相关代码 程序地址】: http://nodep.cn/678622137982.html















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









