







 本文介绍了在不同hash算法中,性能表现的对比测试。通过测试,发现Cityhash算法在性能上优于暴雪hash和Murmurhash64A。测试代码包括了对这三种算法的实现和运行时间的记录。结论是,在Cityhash、Murmurhash64A和暴雪hash中,Cityhash的效率最高。
本文介绍了在不同hash算法中,性能表现的对比测试。通过测试,发现Cityhash算法在性能上优于暴雪hash和Murmurhash64A。测试代码包括了对这三种算法的实现和运行时间的记录。结论是,在Cityhash、Murmurhash64A和暴雪hash中,Cityhash的效率最高。
前些天要写一个小功能,想到了之前看到的暴雪hash,同事推荐murmurhash,于是写了点简单的代码测试了一下。后来在网上又找到了cityhash,于是加了进去测了一下。
结论:暴雪hash算法 murmurhash64A算法 cityhash算法中,性能最高的是cityhash算法
cityhash网址:https://github.com/google/cityhash linux可以很容易的configure make make install
murmurhash64a在网上找的
暴雪hash算法网上找的
最初我是直接用的网上一个叫陈相礼封装的暴雪hash进行对比的,但是发现性能差的巨大(比murmurhash64a),后来实际分析了一下,发现性能是损耗在了冲突上面。
暴雪hash做了两件事:第一、hash(并且是三次,防止冲突) 第二、把它放到散列表中(这样就可以下标访问了)。随着数量越来越多,散列出来的冲突概率也就越来越大,于是乎性能完全不在一个层次上了。原因在于它处理冲突的方式是直接找下一个一直到没有为止。
改进了直接进行暴雪的一次hash,性能对比:
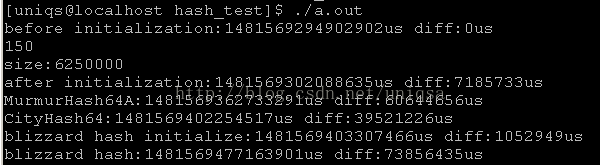
before initialization:1481569294902902us diff:0us
150
size:6250000
after initialization:1481569302088635us diff:7185733us
MurmurHash64A:1481569362733291us diff:60644656us
CityHash64:1481569402254517us diff:39521226us
blizzard hash initialize:1481569403307466us diff:1052949us
blizzard hash:1481569477163901us diff:73856435us
murmurhash64a用了60秒
cityhash64用了39秒
暴雪hash用了73秒
测试代码:
main.cpp
#define TESTNUM (50 * 51 * 52 * 53)
#define TESTLOOP 100
#include <iostream>
#include <fstream>
#include <list>
#include <vector>
#include "hash_algo.h"
#include <string>
#include <sys/time.h>
#include <city.h>
#include "murmurhash.h"
using namespace std;
long getTimeUS()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000 + tv.tv_usec;
}
int main( int argc, char**argv )
{
long uslast = getTimeUS();
long uscurr = getTimeUS();
#define PRINTTIME(str) uscurr = getTimeUS();\
cout<<str<<uscurr<<"us diff:"<<uscurr - uslast<<"us"<<endl;\
uslast = uscurr;
PRINTTIME("before initialization:");
vector<string> dic;
do{
string sks = "我人有的和主产不为这工要在地一上是中国经以发了民同金八月白禾言立水火之啊木大土王目日口田给又女子已山";
cout<<sks.size()<<endl;
for(int i = 0;i < sks.size() / 3;++i)
{
dic.pus 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









