






我第一次接触 Embedding 是在 Word2Vec 时期,那时候还没有 Transformer 和 BERT 。Embedding 给我的印象是,可以将词映射成一个数值向量,而且语义相近的词,在向量空间上具有相似的位置。
有了 Embedding ,就可以对词进行向量空间上的各类操作,比如用 Cosine 距离计算相似度;句子中多个词的 Embedding 相加得到句向量。
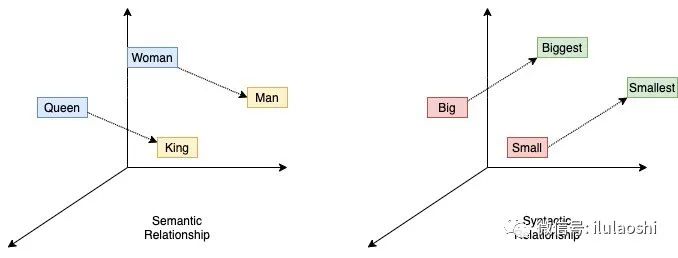 图1 Word2Vec 时期,Embedding 可以将词映射到向量空间,语义相似的词在向量空间里有相似的位置
图1 Word2Vec 时期,Embedding 可以将词映射到向量空间,语义相似的词在向量空间里有相似的位置
那 Embedding 到底是什么?Embedding 怎么训练出来的?
查询矩阵和One-Hot
Embedding 本质是一个查询矩阵,或者说是一个 dict 数据结构。以词向量为例, Embedding dict 的 Key 是词在词表中的索引位置(Index),Embedding dict 的 Value 是这个词的 dim 维的向量。假设我们想把“北京欢迎你”编码为向量。词表一共5个词(Token)(每个字作为一个词):“北”: 0、“京”: 1、“欢”: 2、“迎”: 3、“你”: 4。每个 Token 都有文字表示和在词表中的索引。BERT 等模型的 Token 是单个字,一些其他模型的 Token 是多个字组成的词。
深度学习框架都有一个专门的模块来表示 Embedding,比如 PyTorch 中 torch.nn.Embedding 就是一个专门用于做 Embedding 的模块。我们可以用这个方法将 Token 编码为词向量。

这里 Embedding 的参数中,num_embeddings 表示词表大小,即词表一共多少个词, embedding_dim 为词向量维度。在当前这个例子中,某个词被映射为3维的向量,经过 Embedding 层之后,输出是 Index 为1的 Token 的3维词向量。
Embedding 里面是什么?是一个权重矩阵:

输出是 Embedding 中的权重矩阵,是 num_embeddings * embedding_dim 大小的矩阵。
刚才那个例子,查找 Index 为1的词向量 ,恰好是 Embedding 权重矩阵的第2行(从0计数的话则为第1行)。
权重矩阵如何做查询呢?答案是 One-Hot 。
先以 One-Hot 编码刚才的词表。
为了得到词向量,torch.nn.Embedding 中执行了一次全连接计算:
One-Hot 会将词表中 Index=1 的词(对应的 Token 是“京”) 编码为 [0, 1, 0, 0, 0]。这个向量与权重矩阵相乘,只取权重矩阵第2行的内容。所以,torch.nn.Embedding 可以理解成一个没有 bias 的 torch.nn.Linear ,求词向量的过程是先对输入进行一个 One-Hot 转换,再进行 torch.nn.Linear 全连接矩阵乘法。全连接 torch.nn.Linear 中的权重就是一个形状为 num_embeddings * embedding_dim 的矩阵。
下面的代码使用 One-Hot 和矩阵相乘来模拟 Embedding :

那么可以看到, Embedding 层就是以 One-Hot 为输入的全连接层!全连接层的参数,就是一个“词向量表”!或者说,Embedding 的查询过程是通过 One-Hot 的输入,以矩阵乘法的方式实现的。
如何得到词向量
既然 Embedding 就是全连接层,那如何得到 Embedding 呢?Embedding 层既然是一个全连接神经网络,神经网络当然是训练出来的。只是在得到词向量的这个训练过程中,有不同的训练目标。
我们可以直接把训练好的词向量拿过来用,比如 Word2Vec、GloVe 以及 Transformer ,这些都是一些语言模型,语言模型对应着某种训练目标。BERT 这样的预训练模型,在预训练阶段, Embedding 是随机初始化的,经过预训练之后,就可以得到词向量。比如 BERT 是在做完形填空,用周围的词预测被掩盖的词。语料中有大量“巴黎是法国的首都”的文本,把“巴黎”掩盖住:“[MASK]是法国的首都”,模型仍然能够将“[MASK]”预测为“巴黎”,说明词向量已经学得差不多了。
预训练好的词向量作为己用,可以用于下游任务。BERT 在微调时,会直接读取 Embedding 层的参数。预训练好的词向量上可以使用 Cosine 等方式,获得距离和相似度,语义相似的词有相似的词向量表示。这是因为,我们在用语言模型在预训练时,有窗口效应,通过前n个字预测下一个字的概率,这个n就是窗口的大小,同一个窗口内的词语,会有相似的更新,这些更新会累积,而具有相似模式的词语就会把这些相似更新累积到可观的程度。苏剑林在文章中举了”忐忑“的例子,“忐”、“忑”这两个字,几乎是连在一起用的,更新“忐”的同时,几乎也会更新“忑”,因此它们的更新几乎都是相同的,这样“忐”、“忑”的字向量必然几乎是一样的。
预训练中,训练数据含有一些相似的语言模式。“相似的模式”指的是在特定的语言任务中,它们是可替换的,比如在一般的泛化语料中,“我喜欢你”中的“喜欢”,替换为“讨厌”后还是一个成立的句子,因此“喜欢”与“讨厌”虽然在语义上是两个相反的概念,但经过预训练之后,可能得到相似的词向量。
另外一种方式是从零开始训练。比如,我们有标注好的情感分类的数据,数据足够多,且质量足够好,我们可以直接随机初始化 Embedding 层,最后的训练目标是情感分类结果。Embedding 会在训练过程中自己更新参数。在这种情况下,词向量是通过情感分类任务训练的,“喜欢”与“讨厌”的词向量就会有差异较大。
一切皆可Embedding
Embedding 是经过了 One-Hot 的全连接层。除了词向量外,很多 Categorical 的特征也可以作为 Embedding。推荐系统中有很多 One-Hot 的特征,比如手机机型特征,可能有上千个类别。深度学习之前的线性模型直接对特征进行 One-Hot 编码,有些特征可能是上千维,上千维的特征里,只有一维是1,其他特征都是0,这种特征非常稠密。深度学习模型不适合这种稀疏的 One-Hot 特征,Embedding 可以将稀疏特征编码为低维的稠密特征。
一切皆可 Embedding,其实就是说 Embedding 用一个低维稠密的向量“表示”一个对象。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 1884
1884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









