










本文提供了一个简短的简单指南,介绍如何设置你的第一个 Elasticsearch 开发环境,以便快速进行并开始探索/利用技术提供的功能。简介将基于 Elasticsearch 提供的最重要的 API,这些API是获取数据和执行查询的基础。第二个目的是提供文档和其他有趣资源的链接,以了解其他潜在的操作方面,其他出色的功能和各种工具。
目标受众可以是个人数据分析师或 Web 开发人员,具有相关数据用例且已经听说过 Elasticsearch 的小型团队。并不是要提供技术的完整技术概述(集群,节点,分片,副本,Lucene,反向索引等),也不是要针对某些特定主题进行深入研究,因为有很多很好的资源可以在我的博客中的其它文章中找到。
我们如何开始?
在我看来,开始尝试 Elasticsearch(和许多其他软件技术)的最简单方法是通过 Docker,因此示例将能够利用这种方法。 通常,容器化(已经有一段时间)将接管实际的生产部署/操作,因此可以是二合一的。 Uber 提供了大规模的示例,展示了它们对 Elastic 集群的各个部分的完全容器化方法。 所以让我们开始吧...
安装 Elasticsearch 开发环境
我想你已经对 Docker 熟悉了(如果不熟悉,请安装 Docker for Desktop for Mac,Windows 或 Linux 发行版,阅读一些介绍性的内容,你会很高兴)。 注意:示例已在macOS Mojave上进行了测试,请记住,Linux发行版或Win上可能有一些 Docker 规范。
我们的第一个 node
准备好 Docker 环境后,只需打开终端并使用以下命令启动 Elasticsearch 集群:
docker network create elastic-network这将为我们将来的容器创建一个基本的 “namespace”。
现在,如果你只想进行一个节点部署,请运行:
docker run --rm --name esn01 -p 9200:9200 -v esdata01:/usr/share/elasticsearch/data --network elastic-network -e "node.name=esn01" -e "cluster.name=liuxg-docker-cluster" -e "cluster.initial_master_nodes=esn01" -e "bootstrap.memory_lock=true" --ulimit memlock=-1:-1 -e ES_JAVA_OPTS="-Xms512m -Xmx512m" docker.elastic.co/elasticsearch/elasticsearch:7.5.0在这里,我们创建了一个叫做 liuxg-docker-cluster 的 Elasticsearch 集群尽管里面目前只有一个 node。
在这里需要注意的是如果是在我们的笔记本电脑上进行操作的话,对于那个 ES_JAVA_OPTS 的设置,我们可以设置的比较小一些,否则 docker 会退出。针对我的情况,我使用 512M 内存没有问题。
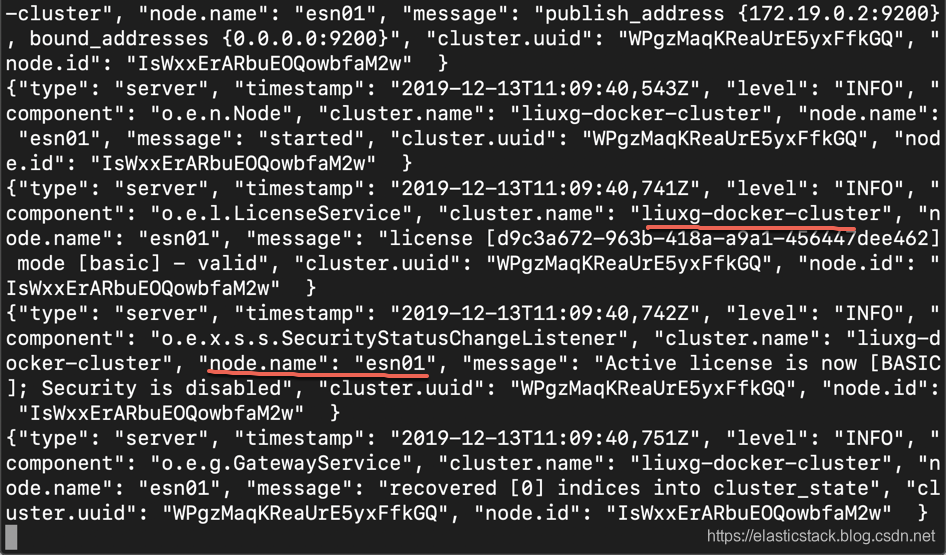
从上面的 log 我们可以看出来,我们的 cluster 已经被成功启动,并运行,。
Hooray…我们开始在 Docker 容器中运行的第一个Elasticsearch节点(esn01),侦听端口 9200(docker -p 参数)。多亏了cluster.initial_master_nodes,它在称为引导群集的过程中创建了一个新的群集(名称在 cluster.name 中),并立即假定该群集为主服务器(独自一人时要做的其他事情:)。最后值得一提的是 -v 参数,该参数由新的 Docker 卷 esdata01 创建并绑定到正在运行的 Elasticsearch 目录-这样,在我们重启后,我们的工作数据将得以保留。其余参数与系统设置相关且非常重要-我们禁用与 bootstrap.memory_lock 的交换,并通过 ESLJAVA_OPTS 增加文件/进程的限制(即专用内存)根据你的配置进行调整...但是请记住,Elasticsearch 还会利用堆外资源,因此请勿将可用内存设置为 50% 以上。许可说明:默认情况下,它与基本许可证一起使用(如Elastic声称的那样,它应永久免费),但是如果要使用纯开放源代码版本,只需在映像名称的末尾添加* -oss。
其他两个节点(可选)
现在,如果你想尝试一下分布式设置,请向集群添加两个(或更多)其他节点。 在这个教程中并不需要(在本地计算机上运行),也不需要实际的基本操作。 但是,由于分布式部署实际上是 Elasticsearch 的核心增值功能之一(因为索引部分主要由 Apache Lucene 库负责),因此至少应该意识到这一点。 因此,如果我们决定来尝试一下,我们可以按照如下的方式启动另外两个节点(在单独的终端中运行):
docker run --rm --name esn02 -p 9202:9200 -v esdata02:/usr/share/elasticsearch/data --network elastic-network -e "node.name=esn02" -e "cluster.name=liuxg-docker-cluster" -e "discovery.seed_hosts=esn01" -e "bootstrap.memory_lock=true" --ulimit memlock=-1:-1 -e ES_JAVA_OPTS="-Xms512m -Xmx512m" docker.elastic.co/elasticsearch/elasticsearch:7.5.0docker run --rm --name esn03 -p 9203:9200 -v esdata03:/usr/share/elasticsearch/data --network elastic-network -e "node.name=esn03" -e "cluster.name=liuxg-docker-cluster" -e "discovery.seed_hosts=esn01,esn02" -e "bootstrap.memory_lock=true" --ulimit memlock=-1:-1 -e ES_JAVA_OPTS="-Xms512m -Xmx512m" docker.elastic.co/elasticsearch/elasticsearch:7.5.0针对我的情况,由于内存的限制,我只启动了两个 node:esn01 和 esn02。
我们可以在浏览器打开 localhost:9200 来查看信息:
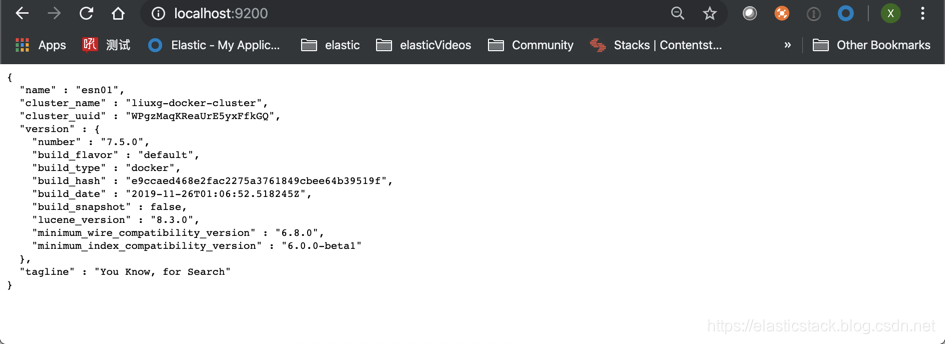
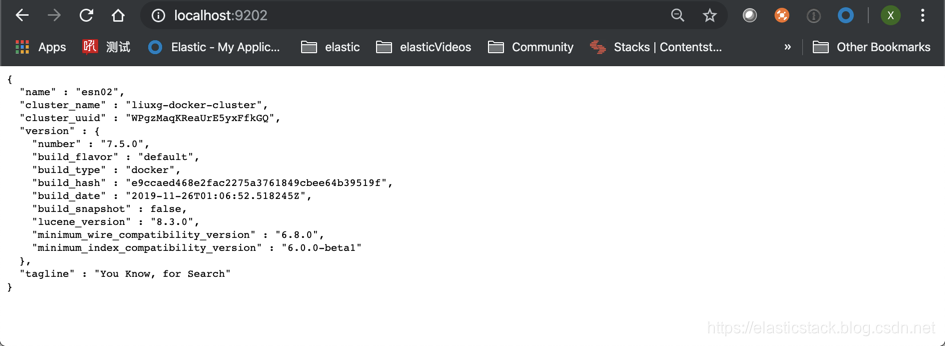
显然我们的两个 node 都已经起来了。
我们也可以使用如下的命令来查看我们的集群里的 node:
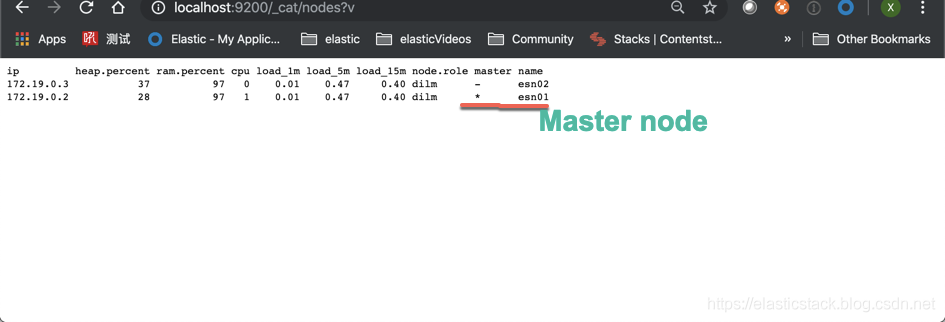
带有 * 符号的 node 被称之为 master node。至此我们已经成功地创建了我们的 liuxg-docker-cluster 集群。
现在,随着节点加入我们的集群,它变得越来越有趣。你可以在日志中观察这个过程,在日志中有关于添加的消息(来自我们的主集群,关于新添加的节点 esn02)。 通常,这些节点将加入 cluster.dised_hosts 参数中列出的其他“已经存在”的节点-该参数(以及上述 cluster.initial_master_nodes)属于 important discovery settings 里的参数。 群集中节点之间的所有通信都是直接在传输层上进行的(即没有 HTTP 开销),因此为什么要有端口 9300(而不是我们为与群集“外部”通信而公开的端口920x)。
{“type”: “server”, “timestamp”: “2019–08–18T13:40:28,169+0000”, “level”: “INFO”, “component”: “o.e.c.s.ClusterApplierService”, “cluster.name”: “stanislavs-docker-cluster”, “node.name”: “esn01”, “cluster.uuid”: “ilHqkY4UQuSRYnE5hFbhBg”, “node.id”: “KKnVMTDwQR6tinaGW_8kKg”, “message”: “added {{esn02}{4xOwc-_fQDO_lwTlpPks2A}{FW-6YGVSSsmgEt3Mo_GY_Q}{172.18.0.3}{172.18.0.3:9300}{dim}{ml.machine_memory=8360488960, ml.max_open_jobs=20, xpack.installed=true},}, term: 1, version: 16, reason: Publication{term=1, version=16}” }我们可以通过如下的命令来查看我们的集群的健康情况:
curl localhost:9202/_cluster/health?pretty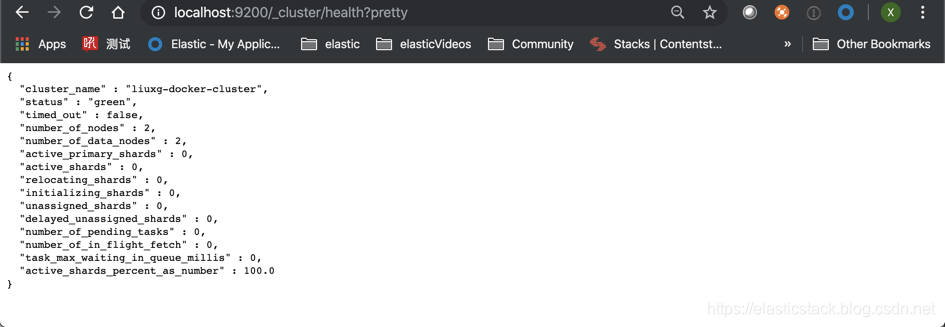
上面显示状态(status)为绿色,也就是说如果我们的一个 node 由于某种原因坏掉的话,不能导致数据的丢失。
每个 node 在 Elasticsearch 的集群中扮演不同的角色,有时甚至某个 node 扮演多个角色。
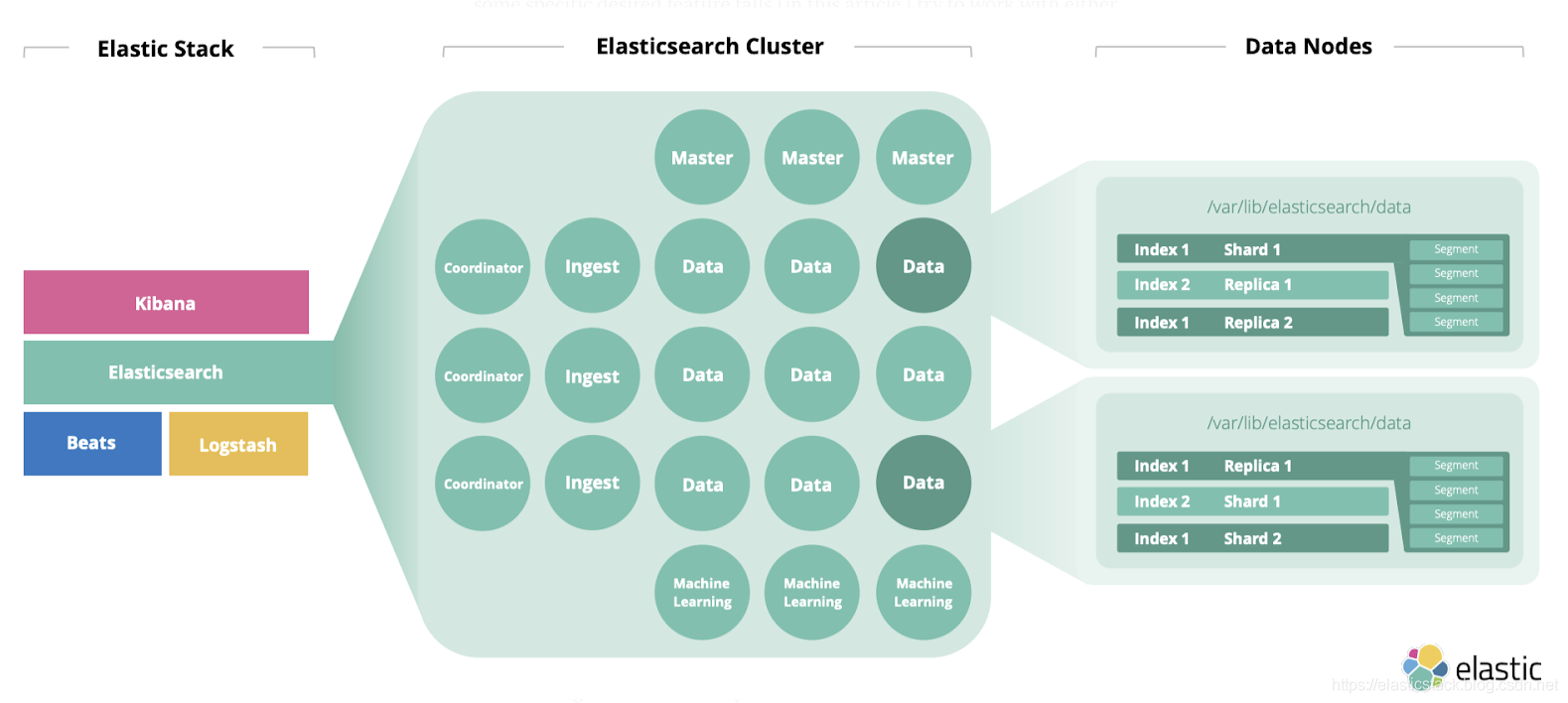
如果大家想了解更多关于这些node的介绍,请参阅我之前的文章 “Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica”。
把数据装载到 Elasticsearch 中去
在这节中,我们将使用 CSV 作为一个例子来展示如何把数据装载到 Elasticsearch 中。
设置好初始环境后,就该将我们的数据移到运行的节点上,以进行搜索了。 Elasticsearch 的基本原理是,放入我们数据的任何“单位”都称为 DOCUMENT。 这些文档的必需格式是 JSON。 这些文档不是单独存储的,而是分为称为 INDEX 的特定集合。 一个索引中的文档具有相似的特征(即数据类型映射,设置等),因此该索引还为所包含的文档提供了管理和 API 层。
创建 Index
让我们使用 Create-Index API 创建索引,然后将一个文档索引到 Index-Document API…
curl -X PUT \
http://localhost:9200/test-csv \
-H 'Content-Type: application/json' \
-d '{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}'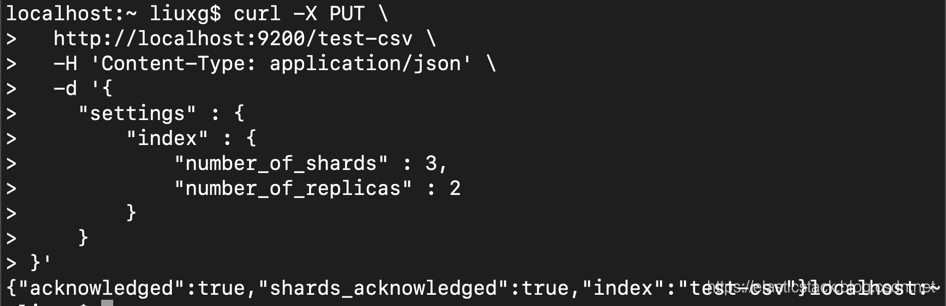
我们创建了第一个名为 test-csv 的索引,并定义了分片和副本数量的重要参数。主分片和分片副本是一种将索引(即文档集合)分成多个片段,从而确保冗余的方法。实际值取决于我们有多少个节点。分片的数量(即,我们将拆分成多少个单元)在索引创建是固定的,而且以后不可以改变。复制副本的数量决定了将“复制”主分片(即我们的3个分片)的次数。我们定义了一个状态,其中每个节点都有一个主分片(我们的数据的1/3),但也有我们其他数据的副本。此设置可确保我们丢失所有数据。提示:如果你想使用这些设置来入门,那么如果你尝试在没有现有索引的情况下为文档建立索引,则必须为此付费-它会自动创建(具有默认的1个分片和1个副本)。
curl -X PUT \
http://localhost:9203/test-csv/_doc/1?pretty \
-H 'Content-Type: application/json' \
-d '{
"value": "first document"
}'curl -X PUT \
http://localhost:9200/test-csv/_doc/1?pretty \
-H 'Content-Type: application/json' \
-d '{
"value": "first document"
}'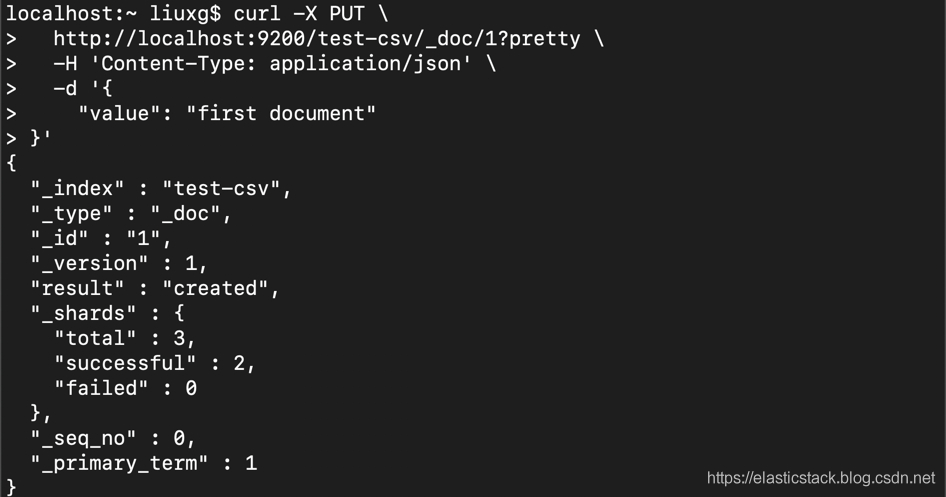
我们已经将第一个文档索引到我们的 test-csv 索引中,所有分片均得到正确回答。 我们已经为只有一个字段的一个非常简单的 JSON 文档建立了索引,但是只要它是有效的 JSON,就可以对任何文档进行索引(从大小,深度等角度来看)-但请尝试将其保持在每个文档 100MB 以下:)。 现在,你可以使用 Get API 通过其 ID 轻松检索单个文档。 由你自己决定。
使用 Python 来装载 CSV 数据
现在,你要使用 curl 逐个索引文档。当你可能已经在应用程序,数据库或存储驱动器中的某处拥有此数据时,此功能就越多。为此,有针对各种编程语言的官方 Elasticsearch 客户,例如 Java,JS,Go,Python 等。你可以根据你的技术堆栈使用其中任何一种,并使用其API以编程方式执行索引/删除/更新/…操作。
但是,如果你只拥有数据并希望快速获取它们,则有两个选择……我选择了一个 Python 客户端和一个非常简单的 CLI 脚本,该脚本可让你从给定文件中索引数据-支持 CSV 格式和 NDJSON 格式(以换行符分隔的 JSON,通常用于日志记录,流处理等)。你可以浏览许多其他与 Elasticsearch API 匹配的方法和帮助程序。使用脚本之前,请不要忘记在安装模块之前安装 elasticsearch 的 python 包:
pip install elasticsearch此仓库中免费提供的代码/脚本:
git clone https://github.com/liu-xiao-guo/load_csv_or_json_to_elasticsearch在这个代码里,有两点非常重要:
1)它利用 Python 生成器概念遍历给定文件,并为索引执行产生一个预处理的元素/行。 选择此“元素方式”操作是为了确保内存效率,甚至能够处理大文件。
def _csv_generator(self, es_dataset, **kwargs):
with open(es_dataset.input_file) as csv_file:
csv_dict_reader = csv.DictReader(csv_file)
for cnt, row in enumerate(csv_dict_reader):
yield self._prepare_document_for_bulk(es_dataset, row, cnt)2)另一方面,实际的索引操作使用 BULK API 来索引多个多文档块(默认为500个项目),这与速度调整建议相一致。 对于此操作,它使用 python elasticsearch 客户端提供的其中一个帮助程序(在原始 API 之上为便利性抽象)-elasticsearch.helpers.streaming_bulk。
for cnt, response in enumerate(streaming_bulk(self.client, generator, chunk_size)):
ok, result = response执行后,有必要使用 refresh API 来使文档立即可搜索。
self.client.indices.refresh(index=es_dataset.es_index_name)从数据的角度来看,现在有很多选项可用于获取一些有趣的数据集(Kaggle 数据集,AWS 数据集或其他公开数据集的精选列表),但我们也想展示一些文本功能。 NLP 地区的一些东西-可以在这里找到不错的收藏。 危险问题数据集不是典型的演示数据集。 注意:如果使用此设置,还请考虑从标题中删除空格,以使列/字段名称更简洁。
运行
现在我们可以在终端中运行以下命令并查看 stdout 日志。为了测试方便,我们使用如下的数据。
https://data.cityofchicago.org/api/views/xzkq-xp2w/rows.csv?accessType=DOWNLOAD
这是一个芝加哥城市职员的工资表单。
$ ls
Current_Employee_Names__Salaries__and_Position_Titles.csv
README.md
load_csv_or_json_to_elasticsearch.py运行我们的 Python 应用:
$ python3 load_csv_or_json_to_elasticsearch.py Current_Employee_Names__Salaries__and_Position_Titles.csv test-csv
我们在浏览器的地址栏中打入如下的命令:
http://localhost:9200/_cat/indices?v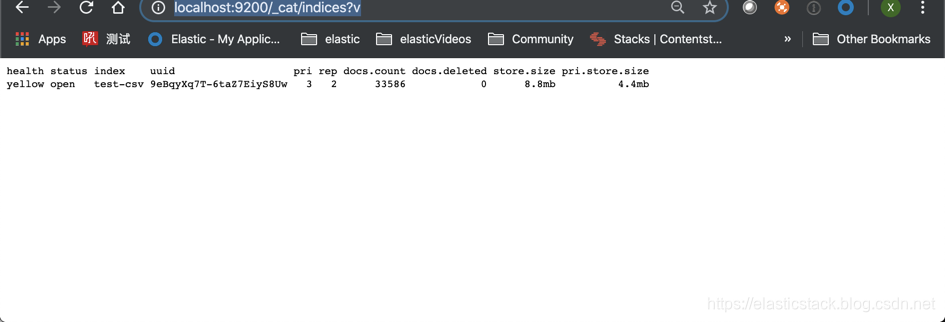
我们可以看到我们的 test_csv 索引,并且它有 33586 个文档。我们甚至可以使用如下的命令来进行查询:
http://localhost:9200/test-csv/_search?q=Department=POLICE&pretty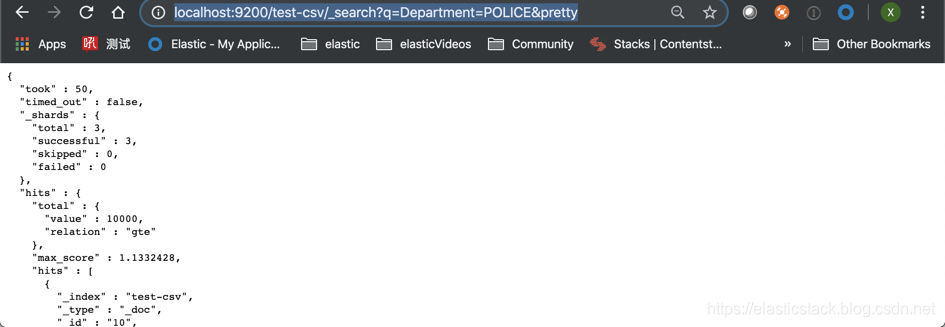
现在我们已经掌握了如何使用 Python 来把我们的一个 CSV 文档导入到 Elasticsearch 之中了,那么我们还需要了解哪些知识呢?
还需要了解的技术点:
- 索引映射/设置:使用获取映射 API 检查索引结构数据,并使用获取设置 API 检查索引设置-有多种设置选项。
- INDEX TEMPLATING:对于持续创建相似索引(即在某些时间段)的用例,为此使用预定义的结构很方便-索引模板就是这种情况
- 索引更改:你可以使用 Reindex API 在索引之间移动数据(在需要更改分片时很有用-创建后无法使用),可以与索引别名结合使用,以允许你创建“昵称”以我们可以指向我们的查询(这一抽象层允许你更自由地更改别名后面的索引)
- 分析器:当我们进行索引或全文搜索查询时,请阅读有关分析器及其核心构件的更多信息,其中包括字符过滤器,标记器和标记过滤器,或创建自定义分析器。
- 客户端设计:适用于各种编程语言(例如 Java,JS,Go,Python 等)的 Elasticsearch 官方客户端。
- 数据摄入:通常对于基于时间的数据(例如日志,监视等),你可以考虑使用 Elastic Stack 中的其他工具(例如 Beats 或/和 Logstash)进行更复杂的数据预处理在索引到 Elasticsearch 之前
- 内存/存储:如果发现索引数据的磁盘空间越来越少,则可以考虑使用索引生命周期管理,该生命周期管理可基于定义的规则来更改或删除索引。如果内存不足,则可以查看冻结索引,该索引会将不同的开销数据结构移出堆。或者只是购买更多的磁盘空间和内存:)
- 性能:调整索引速度或有效使用磁盘
享受 Kibana 带来的便利
到目前为止,我们一直在直接与我们的 Elasticsearch 集群进行交互。 在第一章中,是通过 python 客户端进行的,但后来大多使用简单的 Curl 命令。 当你想通过绘图,过滤等方式进行数据探索时,Curl 非常适合进行快速测试并将其放在一起。 或需要一些工具来对集群和索引进行管理检查和更新,则可能需要选择一些更方便的基于 UI 的应用程序。 正是 Kibana 是什么,或者正如Elastic将其放在 Elasticsearch 上一样。 事不宜迟,让我们将其添加到我们的设置中,看看我们能做什么:
docker run --rm --link esn01:elasticsearch --name kibana --network elastic-network -p 5601:5601 docker.elastic.co/kibana/kibana:7.5.0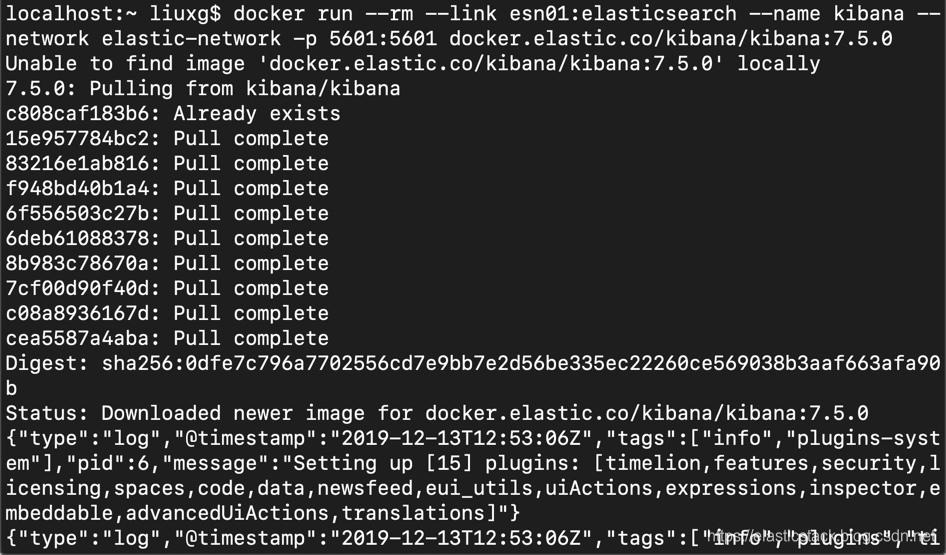
等我们安装好我们的 docker 后,我们可以直接在我们的浏览器中打入如下的地址:
localhost:5601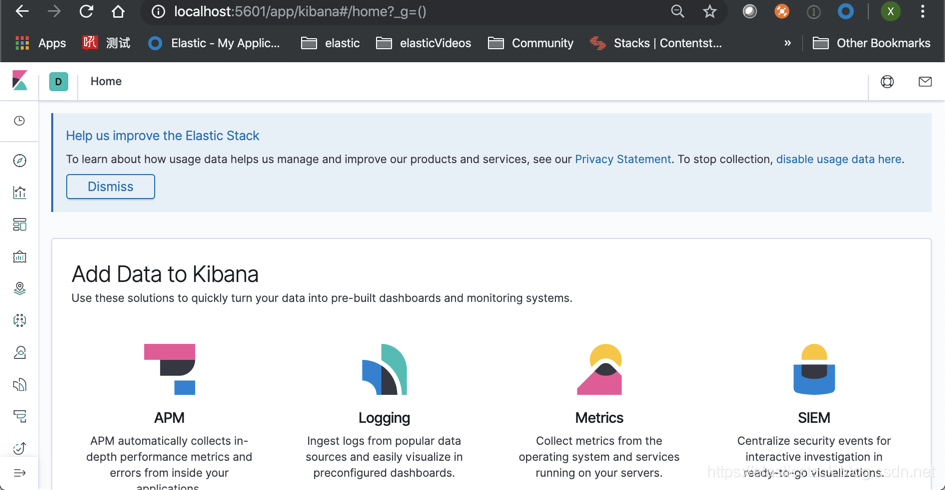
我们可以看到我们的 Kibana 已经被成功启动了。我们可以在这个基础上使用我们的 Kibana 来分析我们的数据了。更多关于Kibana 的介绍,请参阅我的文章。
参考:















 1390
1390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









