







数组中的数据有序是一个很好的性质,那么对一个数组中的数字的排序就是很常用的一个算法。一个例子就是二分查找的前提就是数组中的数据有序。
快速排序是最佳的排序方式。快排不仅实现原地排序,期望时间复杂度只有
O(nlogn)
。其中
n
是数组的长度。在最不差的情况下,快排的时间复杂度会退化到
下面的代码来自算法导论85页,是快速排序的结构。其中,A是数组名,p是起始位置,r是结束位置。
1 QUICKSORT(A,p,r)
2 if p > r
3 then q = PARTITION(A,p,r)
4 QUICKSORT(A,p,q-1)
5 QUICKSORT(A,q+1,r)
快速排序的核心是PARTITION函数,返回值是关键字的位置q。经过PARTITION的处理之后,整个数组会有一个非常好的性质:一趟排序完成后,A[q]左边的数都比q小,A[q]右边的数都比q大。有了这个性质之后,对A[q]左右两的部分进行同样的快速排序操作。我们尽可能地让q接近p和r的中间值,这样的划分最为平衡。
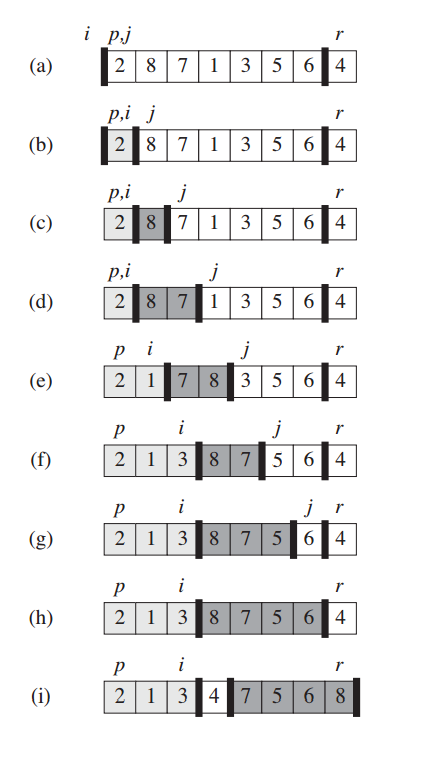
下面是快速排序的关键部分,分为两个部分:1.选取关键字,2.将关键字放在正确的位置上:关键字左边的数都比它小,右边的数都比它大。这样,这个关键字在接下来的排序中都不会改变位置。
1 PARTITION(A,p,r)
2 x = A[r]
3 i = p-1
4 for j = p to r-1
5 do if A[j] ≤ x
6 then i ++
7 swap(A[i],A[j])
8 swap(A[i+1],A[r])
9 return i+1
上面的代码原地完成了对A[r]中数的移动,使之到达最终正确的位置。
下面的图详细给出了这个过程,A[r]成为了关键字x,整个过程结束后,4会到达正确的位置上。p,r是整个区间的起点和终点,是固定的。而i,j标明了两个区间的终点和起点,是在整个过程中不断修正的。i是一个关键的位置:i是比值关键字A[r]小的序列的末尾位置。i+1则是比A[r]大的数的区间的最左边的位置。i从整个区间最左端p-1开始不断增加。在整个过程结束之后,A[r]会和A[i+1]交换,就是和比A[r]大的序列的最左边的数交换,来达到A[r]的正确位置。(h步中的8和4交换)
j向左移动的条件是A[j]小于等于x。j要略过这些数值,因为这些数字本身比关键字x小,是符合要求的,所以i的值也要跟随增加。但是当A[j]的值大于x时,这个位置上的数不应该在x的左边区间,因此i不动,j继续右移。[i+1,j]就是比关键字大的数的区间。[p,i]是比关键字x小的区间。因为选取的关键字A[r]在区间的最右边,这个位置应该放比关键字大的数。因此,最后一步是将区间[i+1,j]的最左边的位置上的书和关键字交换。
上面给出的代码是的目标是升序有序,就是右边的数大于等于左边的数,这里由第5行决定。如果想要非增序排序,则i向右移动的条件是A[j] ≥ x。
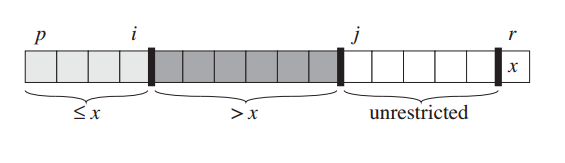
下图是整个区间的划分情况。[p,i]是比x小的数的区间,[i+1,j]是比x大的区间。这两个区间是有序区间,而[j+1,r-1]是待处理的原始区间。最终状态是j到达位置r-1的,此时只剩两个有序区间。
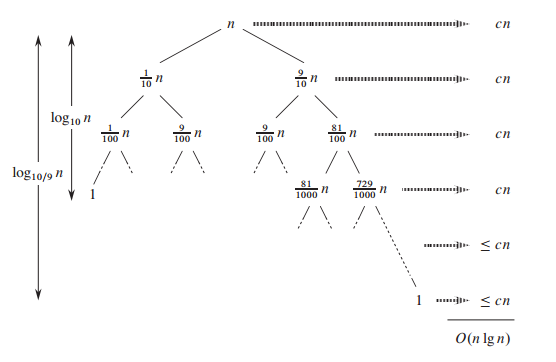
时间复杂度分析:PARTITON在区间[p,r]上运行的时间是线性级别的和,区间的长度有关:n=r-p+1. j从p开始一直扫描到r-1。下图解释了快速排序的整体复杂度。下图中的二叉树的每个节点的变量是子区间的长度。值得注意的是,每一行无论区间的个数,区间长度的和都是n。这也就说明了,每一行的复杂度的和是
O(n)
。但是树的高度是一个随机变量, 它取决于关键字的取法。在最佳的情况下,树的高度最低,是
log(n)
的。这种情况中,每次划分都得到两个等长度的子区间。最差的情况就是树退化成一个线性表,这时数的高度是
n
,这里对应每次划分都得到一个长度为0的区间和长度为n-1的区间。对于上面的例子,有序序列会是一个最差情况。有意思的一点是,从图中看出,即使达不到平衡的划分,而是每次按照比例划分区间,例如1:10划分。其复杂度仍然是
理想情况分析:每次PARTITION执行完之后,返回的都是当前区间的中间位置,就是两个子区间的长度相等。这样会减少划分的次数,一共只用划分 log(n) 次。这样总的时间复杂度为 O(nlog(n))
极端情况分析:当整个区间升序有序的时候,i从p-1一直增加到了位置r-1。这样的划分显然不理想,一个区间很长,另一个区间长度为0.这样的话,划分要进行n次,时间复杂度退化到 O(n2) 。因此,选择关键字的位置十分重要。为了减少极端情况出现的概率,我们可以随机选择一个位置,然后和A[r]交换。这样每次的关键字选择就有了随机性,整个时间复杂度就会接近期望值。
对动态操作能力有限:不过,快速排序的算法对动态操作的处理能力有限。如果在有序序列的基础上插入一个数,或者删除一个数,都要搬移整个序列长度规模的元素。对于动态操作而言,需要更加高级的数据结构。
找第k大的数:根据PARTITION函数的良好性质,还可以做一个引申,就是找一个无序序列第k大的数。我们当然可以将整个序列排序,之后直接返回位置k上的数。这样做的时间复杂度是 O(nlog(n)) 。然而,不需要全部排序。利用PARTITION函数的良好性质,返回q和k作比较。如果k = q,运气好,一下就选对了数,而且还做了验证。如果k<q ,则仅在左边的区间里面找就可以了。这样整个查找的时间复为 O(log(n)) 。
为何快速排序速度快?快速排序相对于插入排序,到底快在哪里?最重要的一点就是,快速排序减少了没有意义的比较。各种排序算法都是基于比较而来的,对于插入排序,最坏情况下每个数都要和前面的有序序列中的每一个比较。而且,插入排序是没有理由跳过一些数不比较的。但是,快速排序就有理由可以跳过一些元素,只跟有必要的元素比较。在对一个区间进行划分之后,形成了两个区间。前一个区间里的数是没有必要和后面区间里面的数比较的。划分完成之后,不仅给关键字找到了最终的位置,而且还隔离了比较域。















 586
586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









